Como criar Análise Preditiva?
Análise Preditiva de séries temporais é essencial em economia, finanças, marketing, entre outras áreas.
Mas aplicar modelos do Scikit-learn diretamente nesses dados exige cuidado — esses modelos não foram pensados para lidar com dependência temporal.
A solução? Skforecast — uma biblioteca que conecta os modelos do Sklearn (como Regressão Linear, Random Forest, XGBoost, etc.) à previsão de séries temporais de forma estruturada e intuitiva.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
O que o Skforecast oferece:
✅ Modelos Univariados Previsão de uma série com base no seu próprio histórico (ex: PIB, inflação).
✅ Modelos Multivariados Usa variáveis exógenas para melhorar a previsão (ex: prever inflação com juros, câmbio, expectativas).
✅ Modelos Globais Treine um único modelo para várias séries — ideal para setores, empresas ou regiões.
✅ Engenharia de Variáveis Geração automática de lags, diferenças e outras transformações temporais.
✅ Avaliação de Performance Cross-validation temporal, rolling window, métricas padronizadas.
✅ Previsão Probabilística Estime valores com intervalo de confiança.
✅ Visualização Gráficos rápidos e prontos para análise.
✅ Interpretação de Modelos Compatível com SHAP, PDP e outros métodos interpretáveis.
Estudo de caso de Análise Preditiva: US Change
Se você tem interesse em aprender a criar previsões de séries econômicas eficientes com o Python, veja nossos cursos de Modelagem e Previsão com Python e Previsão Macroeconômica usando Python e IA.
Para ilustrar como criar uma análise preditiva, vamos tomar como exemplo os dados contidos no dataset US Change, que contém as variações percentuais trimestrais no consumo pessoal, renda disponível pessoal, produção, poupança e taxa de desemprego dos EUA, de 1970 a 2016. Os valores originais em dólares estavam ajustados pela cadeia de preços de 2012.
A ideia é criarmos um modelo simples, através de uma Ridge Regression, e que segue a seguinte equação:
![\[\text{Consumption}_t = \sum_{i>0} \beta_{1i} \text{consumption}_{t-12} + \beta_2 \text{unemployment}_{t} + \beta_3 \text{Income}_t + \beta_4 \text{Savings}_t + \beta_5 \text{Production}_t + ϵ\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-76561781a9d26a873373bddcf3f5fcc0_l3.png "Rendered by QuickLaTeX.com")
Carregamos dados da série, e exibimos na tabela logo abaixo. Nosso objetivo será o de criar a modelagem, então passaremos a parte da análise exploratória de dados.
| Quarter | Consumption | Income | Production | Savings | Unemployment | |
|---|---|---|---|---|---|---|
| 0 | 1970-01-01 | 0.618566 | 1.044801 | -2.452486 | 5.299014 | 0.9 |
| 1 | 1970-04-01 | 0.451984 | 1.225647 | -0.551459 | 7.789894 | 0.5 |
| 2 | 1970-07-01 | 0.872872 | 1.585154 | -0.358652 | 7.403984 | 0.5 |
| 3 | 1970-10-01 | -0.271848 | -0.239545 | -2.185691 | 1.169898 | 0.7 |
| 4 | 1971-01-01 | 1.901345 | 1.975925 | 1.909764 | 3.535667 | -0.1 |
Em seguida, preparamos os dados, separando as amostras de treino e teste, e plotamos os dados em um gráfico:
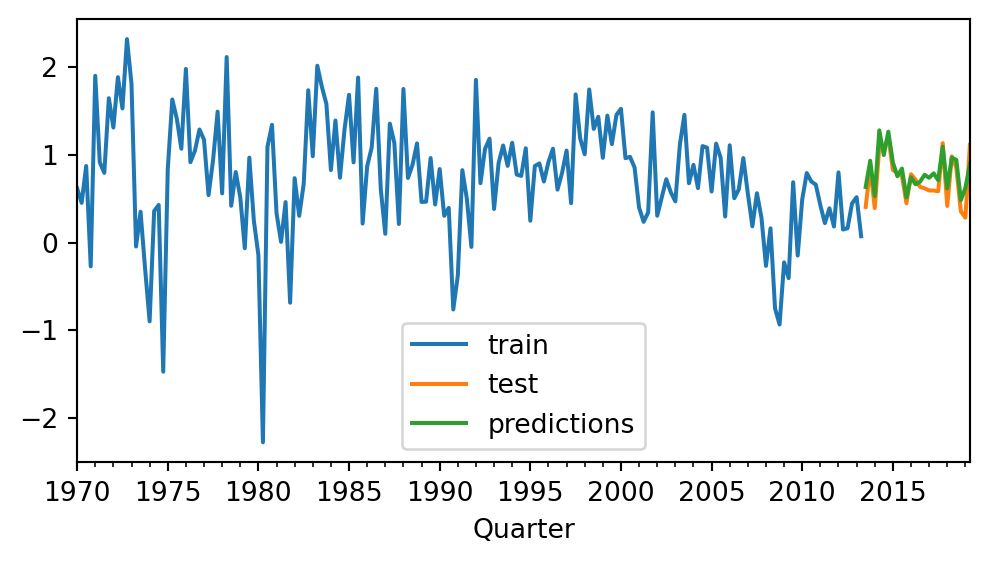
 Agora utilizamos um modelo do sklearn, a regressão Ridge, como previsor para a série temporal, gerando 24 períodos de previsão:
Agora utilizamos um modelo do sklearn, a regressão Ridge, como previsor para a série temporal, gerando 24 períodos de previsão:
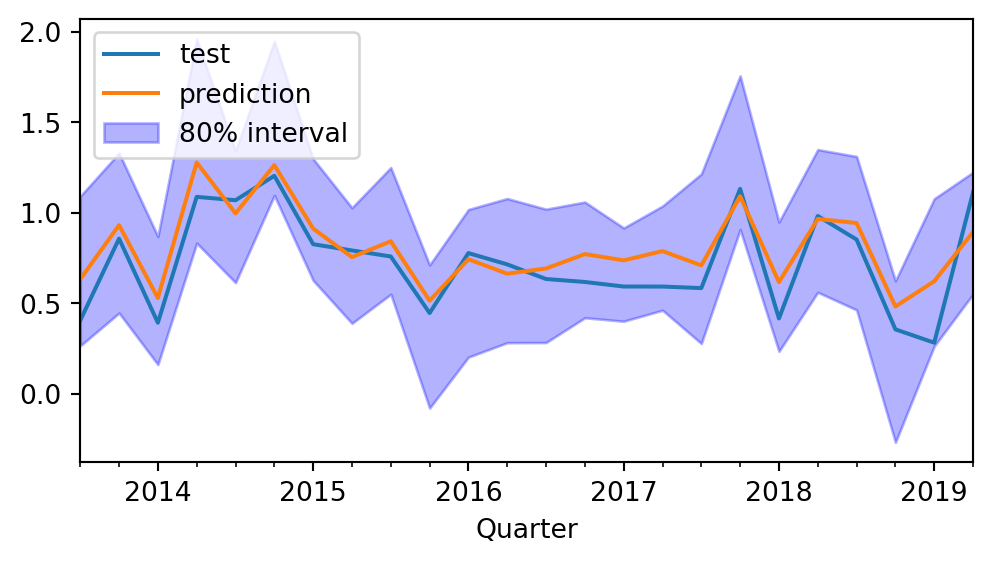
 Calculamos o erro de previsão e exibimos o intervalos de confiança em um gráfico:
Calculamos o erro de previsão e exibimos o intervalos de confiança em um gráfico:
Test error (mse): 0.019882407414541278
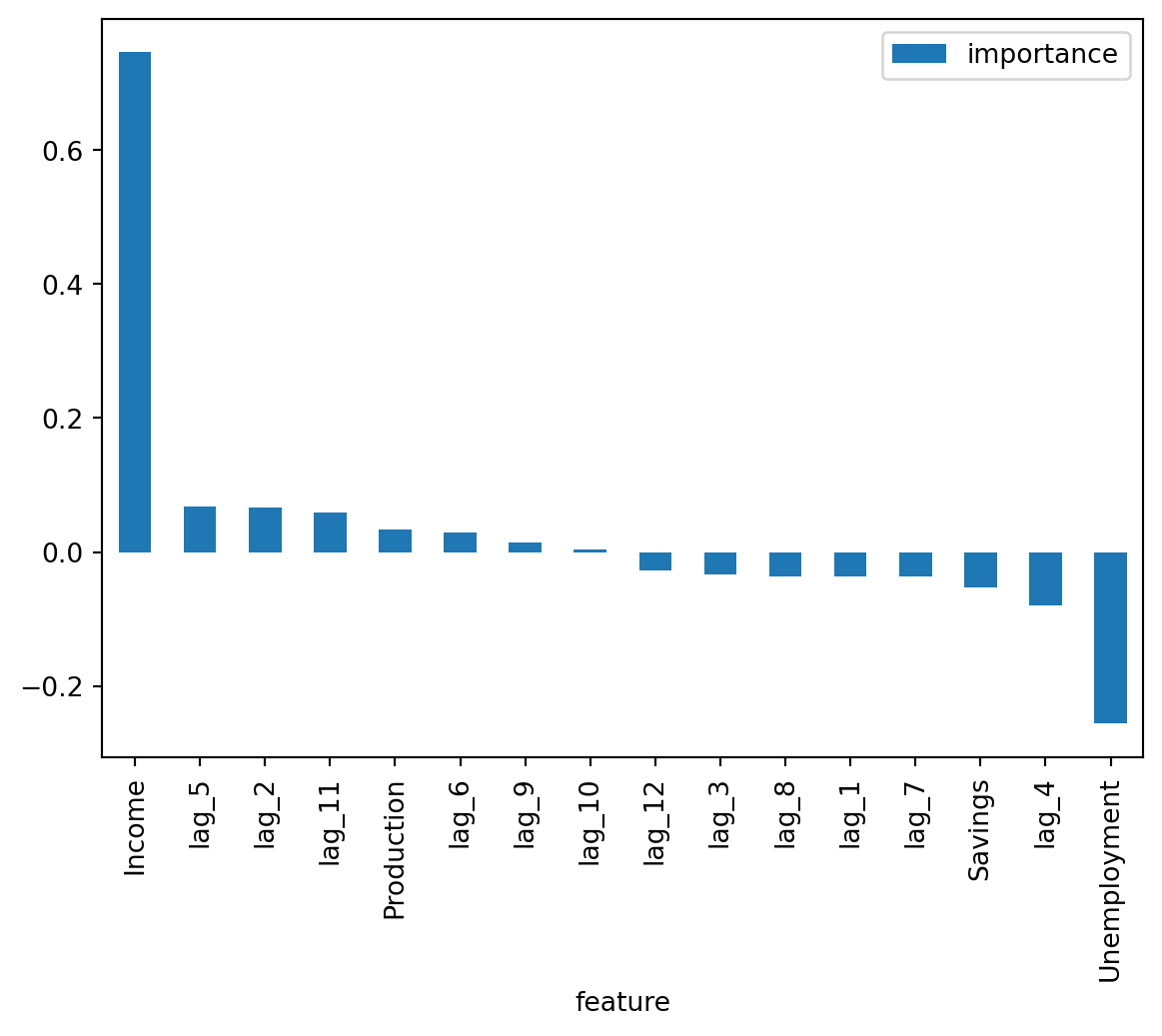
Por fim, criamos um gráfico que mostra a importância de cada regressor no modelo. No caso de uma regressão, isso representa o impacto marginal de cada variável sobre o consumo.
Como era esperado, a renda é a variável com maior influência na explicação do consumo. As defasagens do próprio consumo também têm contribuição positiva, indicando persistência no comportamento do consumidor ao longo do tempo. Já a taxa de desemprego tem impacto negativo, refletindo os efeitos da perda de renda sobre o consumo.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.
Referências
RODRIGO, Joaquín Amat e Escobar Ortiz, Javier. Skforecast: Forecasting time series with machine learning models. Versão 0.15.1. Disponível em: https://skforecast.org/0.15.1/index.html. Acesso em: 9 abr. 2025.

