Uma das aplicações mais poderosas viabilizadas por LLMs são os chatbots sofisticados de perguntas e respostas (Q&A). São aplicações capazes de responder a perguntas sobre informações específicas de uma fonte. Essas aplicações utilizam uma técnica conhecida como Geração Aumentada por Recuperação, ou RAG (do inglês Retrieval Augmented Generation).
Este tutorial mostrará como construir uma aplicação simples de perguntas e respostas (Q&A) baseada em uma fonte de dados textual. Ao longo do caminho, vamos explorar uma arquitetura típica de Q&A e destacar recursos adicionais para técnicas mais avançadas de Q&A.
Observação: Aqui focamos em perguntas e respostas (Q&A) para dados não estruturados usando o framework langchain. Se você estiver interessado em RAG aplicado a dados estruturados, confira este tutorial sobre como fazer perguntas e respostas com dados SQL.
Visão geral
Uma aplicação RAG típica possui dois componentes principais:
- Indexação: um pipeline para ingerir dados de uma fonte e indexá-los. Isso geralmente ocorre de forma offline.
- Recuperação e geração: a cadeia RAG propriamente dita, que recebe a consulta do usuário em tempo de execução, recupera os dados relevantes do índice e os envia para o modelo.
A sequência mais comum, do dado bruto até a resposta, é a seguinte:
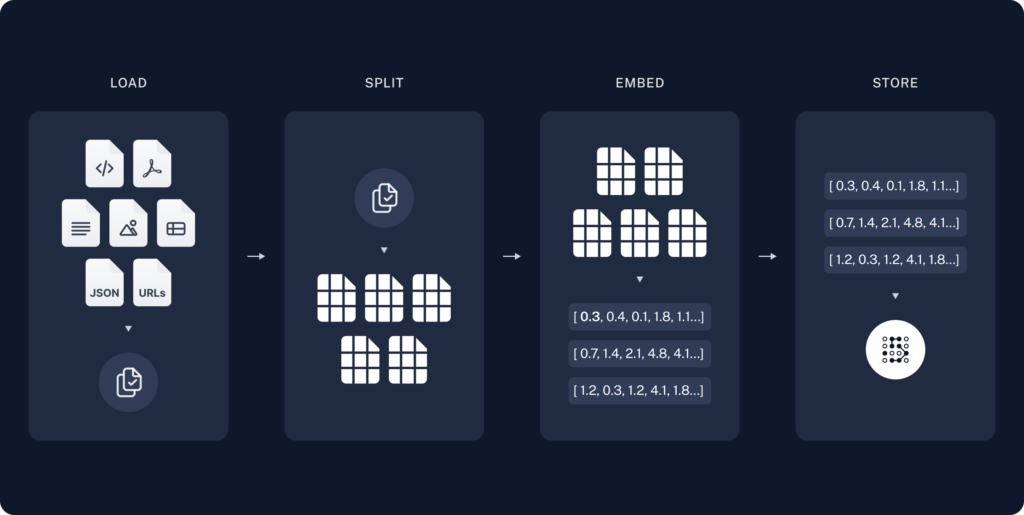
Indexação
- Carregamento (Load): Primeiro, precisamos carregar nossos dados. Isso é feito com Document Loaders (carregadores de documentos).
- Separação (Split): Text splitters (divisores de texto) quebram documentos grandes em trechos menores. Isso é útil tanto para indexar os dados quanto para passá-los ao modelo, já que trechos grandes são mais difíceis de pesquisar e não cabem na janela de contexto finita de um modelo.
- Armazenamento (Store): Precisamos de um local para armazenar e indexar esses trechos, de forma que possam ser pesquisados posteriormente. Isso geralmente é feito utilizando um VectorStore (base de dados vetorial) e um modelo de Embeddings (incorporações).
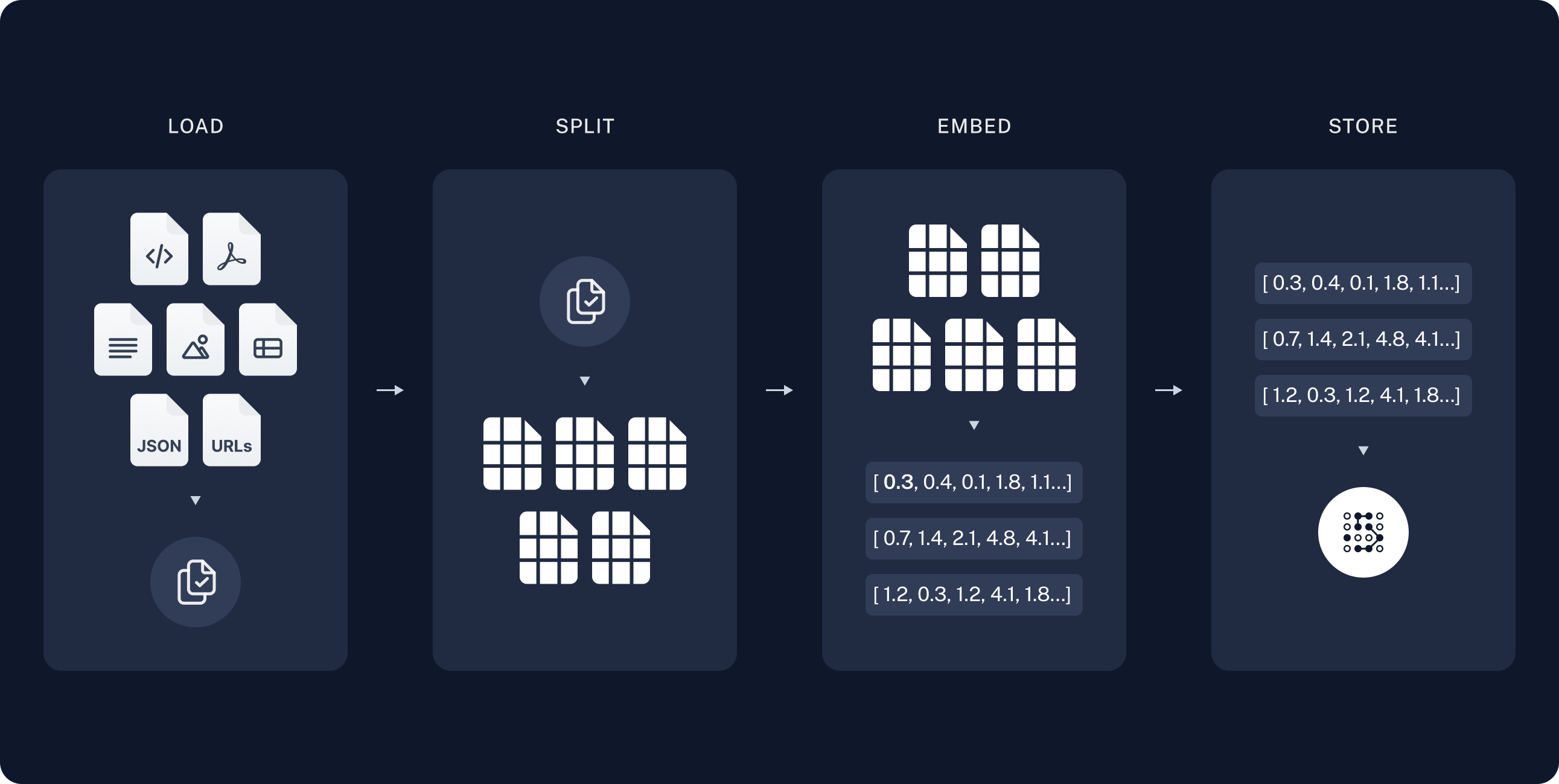
Recuperação e geração
- Recuperar (Retrieve): Dada uma entrada do usuário, os trechos relevantes são recuperados do armazenamento usando um Retriever (mecanismo de recuperação).
- Gerar (Generate): Um ChatModel / LLM produz uma resposta utilizando um prompt que inclui tanto a pergunta quanto os dados recuperados.
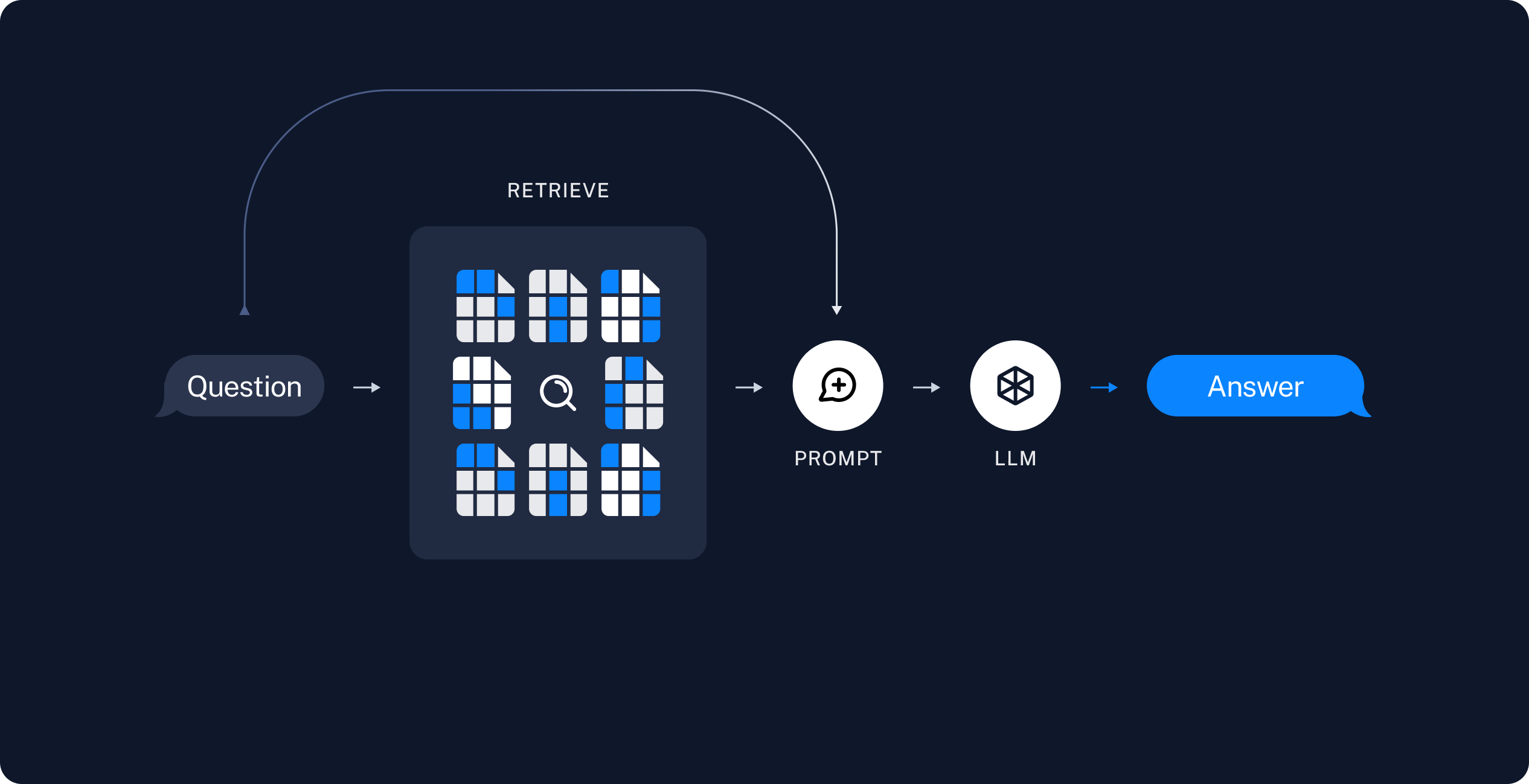
langchain como nosso framework de orquestração para implementar as etapas de recuperação e geração.
Exemplo prático
Para exemplificar um pipeline RAG utilizaremos os documentos/atas do Comitê de Política Monetária - COPOM do Banco Central do Brasil (BCB). São dados textuais disponíveis publicamente. O objetivo será construir uma interface simples de chat que permita ao usuário fazer perguntas sobre as atas do comitê e obter respostas acuradas usando inteligência artificial.
Neste exemplo utilizaremos o Google Colab como interface de programação e os modelos de IA do Google como o cérebro da aplicação.
Bibliotecas
Primeiro carregamos as bibliotecas de Python.
Autenticação
Em seguida definimos a chave de API do Google, gerada previamete no Google AI Studio, como variável de ambiente. Essa chave é necessária para usar os modelos de IA do Google nas limitações da Free tier.
Dados
Agora carregamos os dados textuais das atas do COPOM. Aqui há um mundo de possibilidades, dados que cada fonte de dados possui uma estrutura própria. No nosso caso, as atas podem ser disponibilizadas em PDF, página web, via API, etc.
Apesar do langchain oferecer excelentes ferramentas para coleta automatizada dos dados, como parseadores de conteúdo web, de PDFs, etc., nosso foco não será no web scraping dos textos do COPOM. Sendo assim, copiamos os últimos 4 textos manualmente diretamente do site da instituição e salvamos o conteúdo como arquivos de texto. Em seguida, carregamos os documentos e separamos os mesmos em trechos para otimizar a busca.
Modelo de Embedding
Modelos de embedding criam uma representação vetorial de um trecho de texto. Existem diversos modelos atualmente. Aqui usamos um modelo do Google.
Modelo de chat
Modelos de chat são modelos de linguagem (SLM/LLM) que utilizam uma sequência de mensagens como entrada e retornam mensagens como saída (em vez de usar texto simples). Existem diversos modelos atualmente. Aqui usamos um modelo do Google.
Base de dados vetorial
Uma base de dados vetorial (vector store) armazena dados incorporados (embedded) e realiza buscas por similaridade. Existem diversas opções atualmente. Aqui usamos uma opção open source.
Recuperação de informações
Agora, vamos escrever a lógica da aplicação. Queremos criar uma aplicação simples que receba uma pergunta do usuário, pesquise documentos relevantes para essa pergunta, envie os documentos recuperados e a pergunta inicial para um modelo, e retorne uma resposta.
Definimos um system prompt de instruções para o modelo LLM, que vai incorporar os trechos das atas relevantes para a pergunta, além da própria pergunta. Em seguida, definimos um utilitário de pergunta & reposta do langchain , que incoporta, por sua vez:
- O modelo LLM, responsável por seguir as instruções do system prompt e entregar a resposta
- Um mecanismo de recuperação que usa a técnica de relevância marginal máxima para recuperar as informações
- O system prompt
Perguntas & Respostas
Por fim, definimos uma função que invoca o aplicativo desenvolvido dado uma pergunta do usuário. E assim podemos recuperar contextualmente diversas informações das atas do COPOM usando inteligência artificial.
recuperar_informacao("Quando foi a última reunião do COPOM?") recuperar_informacao("Sumarize a reunião ocorrida em 6 e 7/5/2025.")
--- Prompt: Quando foi a última reunião do COPOM? --- Resposta: 6-7 maio, 2025 Documentos de origem: - Conteúdo: Informações da reunião Data: 10 e 11/12/2024 Local: Salas de reuniões do 8º andar (10/12 e 11/12 – manhã) e do 20º andar (11/12 – tarde) do Edifício-s... Metadados: {'source': 'ata267.txt'} - Conteúdo: Ata do Comitê de Política Monetária - Copom 270ª Reunião - 6-7 maio, 2025 Data de publicação: 13/05/2025 A) Atualização da conjuntura econômica e d... Metadados: {'source': 'ata270.txt'} - Conteúdo: 22. O Copom então decidiu elevar a taxa básica de juros em 1,00 ponto percentual, para 14,25% a.a., e entende que essa decisão é compatível com a estr... Metadados: {'source': 'ata269.txt'} ---------------------------------
recuperar_informacao("Quais são os principais fatores discutidos na reunião de 6 e 7 de maio de 2025 do COPOM?")
--- Prompt: Quais são os principais fatores discutidos na reunião de 6 e 7 de maio de 2025 do COPOM? --- Resposta: Os principais fatores discutidos foram: * O ambiente externo adverso e incerto, especialmente a política comercial dos EUA e seus efeitos. * O comportamento e a volatilidade de diferentes classes de ativos e seus reflexos nas condições financeiras globais. * A incipiente moderação no crescimento da atividade econômica no cenário doméstico. * A inflação cheia e as medidas subjacentes acima da meta. * As expectativas de inflação para 2025 e 2026 acima da meta. Documentos de origem: - Conteúdo: Ata do Comitê de Política Monetária - Copom 270ª Reunião - 6-7 maio, 2025 Data de publicação: 13/05/2025 A) Atualização da conjuntura econômica e d... Metadados: {'source': 'ata270.txt'} - Conteúdo: Informações da reunião Data: 10 e 11/12/2024 Local: Salas de reuniões do 8º andar (10/12 e 11/12 – manhã) e do 20º andar (11/12 – tarde) do Edifício-s... Metadados: {'source': 'ata267.txt'} - Conteúdo: 8. A conjuntura de atividade segue marcada por sinais mistos com relação à desaceleração de atividade, mas observa-se uma incipiente moderação de cres... Metadados: {'source': 'ata270.txt'} ---------------------------------
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

