Modelar e prever variáveis macroeconômicas — como inflação, câmbio, PIB e juros — exige um processo cuidadoso de preparação e análise dos dados. Antes de qualquer algoritmo de previsão, é preciso entender as séries temporais, aplicar transformações adequadas e selecionar apenas as variáveis mais relevantes e consistentes. Neste post, vamos explorar como esse processo pode ser automatizado com Python, combinando ferramentas da econometria clássica e da inteligência artificial.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
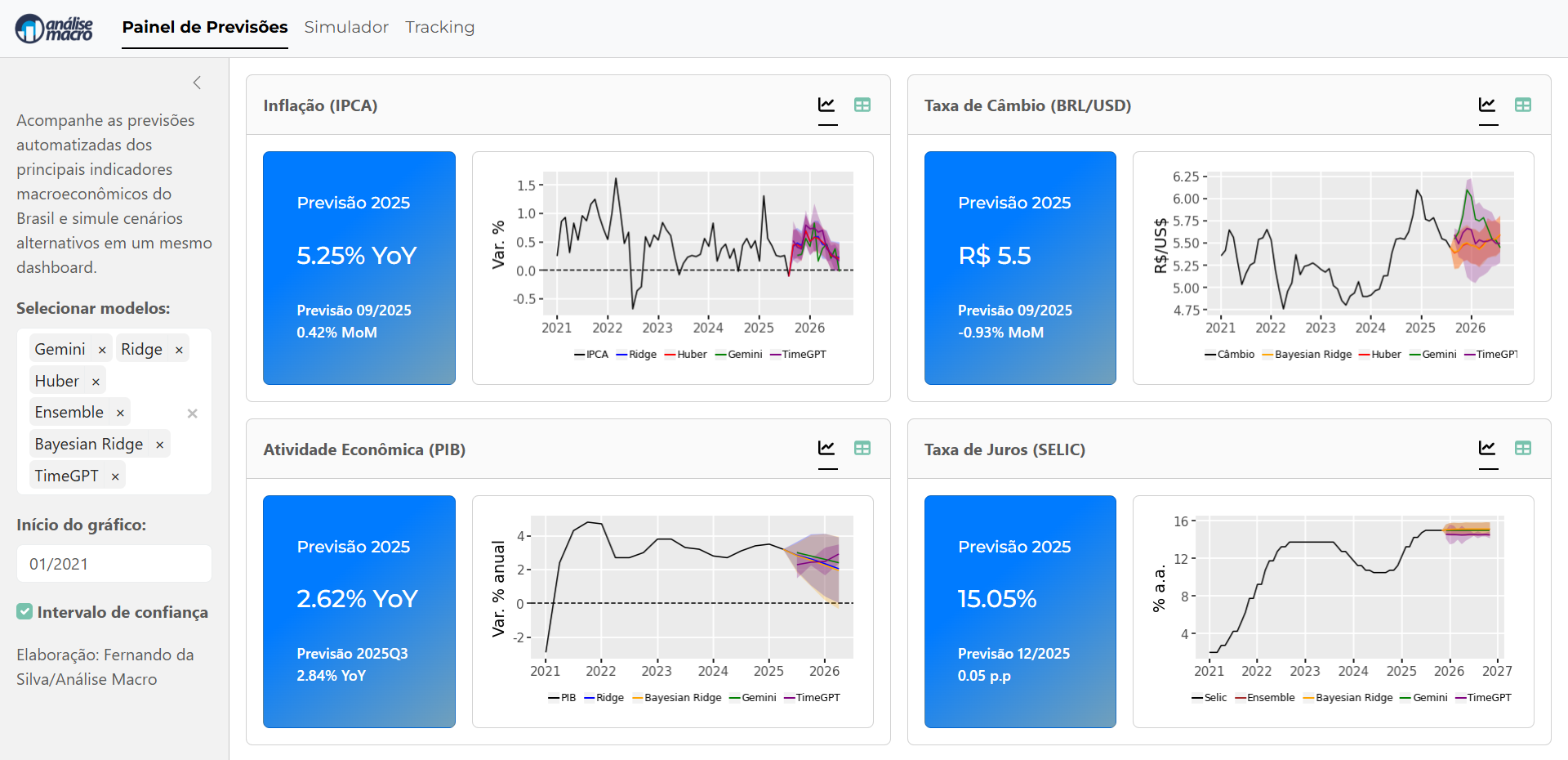
O primeiro passo foi organizar os dados a partir de uma base mensal do Brasil, armazenada em formato Parquet e com metadados definidos em planilha. Cada série econômica traz instruções de transformação — como diferenças, logaritmos ou ambas — que garantem estacionariedade e eliminam tendências espúrias. Essa padronização é fundamental para evitar distorções nas análises de correlação e nas estimativas dos modelos.
Após carregar e transformar os dados, uma etapa crítica foi o tratamento de valores ausentes. As variáveis com mais de 20% de dados faltantes foram removidas, enquanto os demais NAs foram preenchidos com o método de vizinhança (backfill e forward fill). Essa abordagem mantém a coerência temporal das séries e preserva a estrutura de autocorrelação — essencial em aplicações de previsão macroeconômica.
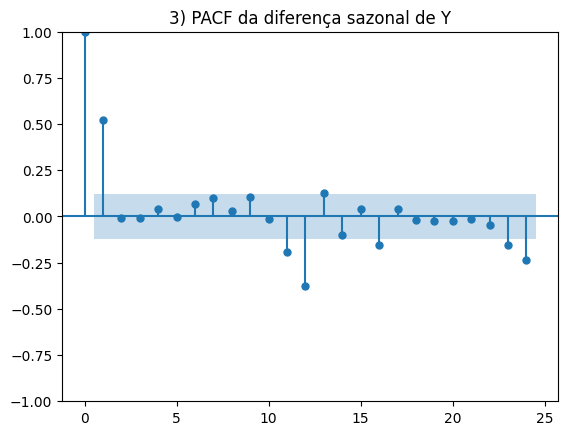
Na sequência, foram aplicadas técnicas de análise exploratória de séries temporais. A decomposição via STL permitiu observar componentes sazonais e tendências de longo prazo no IPCA, enquanto os gráficos ACF e PACF ajudaram a identificar padrões de autocorrelação e possíveis ordens de diferenciação. Essas análises ajudam a entender o comportamento da série e a orientar a escolha do modelo mais adequado.
A análise de correlação entre o IPCA e dezenas de variáveis econômicas auxiliares (como câmbio, expectativas de inflação, atividade e juros internacionais) serviu de base para uma pré-seleção de variáveis. Algumas séries de maior correlação foram priorizadas para o processo de modelagem. Também foram adicionadas dummies sazonais para capturar efeitos de mês do ano, muito comuns em séries de inflação.
Para lidar com multicolinearidade, um dos principais problemas em modelos econométricos e de machine learning, foi implementada uma função baseada no Variance Inflation Factor (VIF). Variáveis com VIF acima de 5 foram iterativamente removidas, garantindo que os preditores restantes fossem informativos e independentes o suficiente para evitar redundância nos modelos.
Na etapa de seleção de variáveis, o script utilizou o método Recursive Feature Elimination with Cross-Validation (RFECV), combinado a um modelo autorregressivo (ForecasterAutoreg) com regressão Ridge. Essa abordagem aproveita a estrutura temporal dos dados e busca automaticamente o conjunto ótimo de variáveis com maior poder explicativo e preditivo, com base em uma validação cruzada específica para séries temporais (TimeSeriesSplit).
O resultado é um conjunto enxuto e robusto de variáveis selecionadas, incluindo expectativas de inflação de curto prazo, indicadores de commodities, câmbio, prévia da inflação, além de componentes sazonais e lags. Esse tipo de seleção não apenas melhora a precisão das previsões, mas também facilita a interpretação econômica dos resultados — um ponto essencial em aplicações de política monetária e análise macroeconômica.
Ao integrar econometria e aprendizado de máquina em um mesmo fluxo de trabalho, é possível construir pipelines de previsão mais consistentes, transparentes e automatizados. Essa abordagem é a base da nova geração de modelos híbridos que unem teoria econômica, estatística e inteligência artificial aplicada a dados reais.
Quer aprender o passo a passo completo desse processo — da coleta automatizada ao modelo preditivo e dashboard final?
👉 Participe da Imersão “Econometria vs. Inteligência Artificial na Previsão Macroeconômica” e domine as técnicas mais avançadas de modelagem aplicada à economia.

