Introdução
A dinâmica do mercado de trabalho é um dos principais termômetros da saúde econômica de um país. Um dos fenômenos mais observados por economistas ao analisar o turnover (rotatividade) da mão de obra é a diferença salarial entre os trabalhadores que são desligados das empresas e aqueles que são recém-contratados para ocupar novas vagas. Historicamente, em momentos de reestruturação ou crise, empresas tendem a substituir funcionários mais antigos e com salários maiores por novos empregados ganhando menos, gerando um "gap" salarial.
Para investigar essa dinâmica na economia brasileira recente (2020 em diante), utilizamos os microdados do Novo CAGED (Cadastro Geral de Empregados e Desempregados). Lidar com essa base de dados, no entanto, impõe um desafio técnico considerável: estamos falando de milhões de registros mensais. É aqui que a linguagem Python se consolida como uma ferramenta indispensável, permitindo não apenas a coleta e o processamento de Big Data, mas também a aplicação de tratamentos econométricos, como deflacionamento e ajuste sazonal.
Quer ver a vídeoaula do tutorial deste exercício? E receber o código que o produziu? Faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
O Desafio dos Microdados e a Engenharia de Dados em Python
O Novo CAGED não disponibiliza a série histórica de salários médios de forma mastigada em uma API simples. Para obter o valor exato do salário contratual de admissões e demissões, é necessário baixar os microdados mensais diretamente do servidor FTP do Ministério do Trabalho e Emprego (MTE). Cada arquivo compactado contém milhões de linhas.
Para contornar o limite de memória RAM e automatizar o processo dentro do Google Colab, o script em Python foi estruturado com a seguinte arquitetura:
- Coleta e Extração: O código acessa o FTP, baixa os arquivos
.7ze os descompacta dinamicamente. - Processamento em Lotes (Chunks): Utilizando a biblioteca
pandas, os arquivos de texto gigantescos são lidos em pedaços de 200 mil linhas por vez. - Limpeza e Agregação: Em cada lote, removem-se salários zerados ou inválidos e aplica-se um filtro de outliers (excluindo o 1% dos maiores salários para evitar distorções por erros de preenchimento). Em seguida, os salários são separados por tipo de movimentação (Admissão = 1, Desligamento = -1).
- Armazenamento em Banco de Dados: Os dados agregados (soma dos salários e número de vínculos) são salvos em um banco de dados local SQLite. Isso garante que, caso o processo seja interrompido, o código não precise reprocessar os meses já concluídos.
Metodologia Econômica
Analisar apenas os salários nominais ao longo de vários anos gera uma ilusão de ótica devido à inflação. Para que a análise tenha validade econômica, o Python foi utilizado para aplicar duas transformações fundamentais:
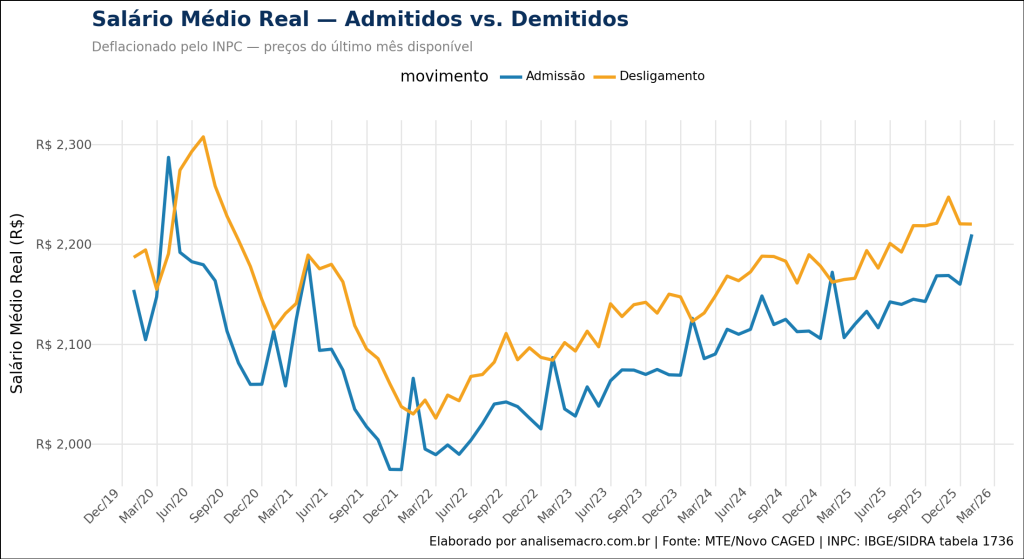
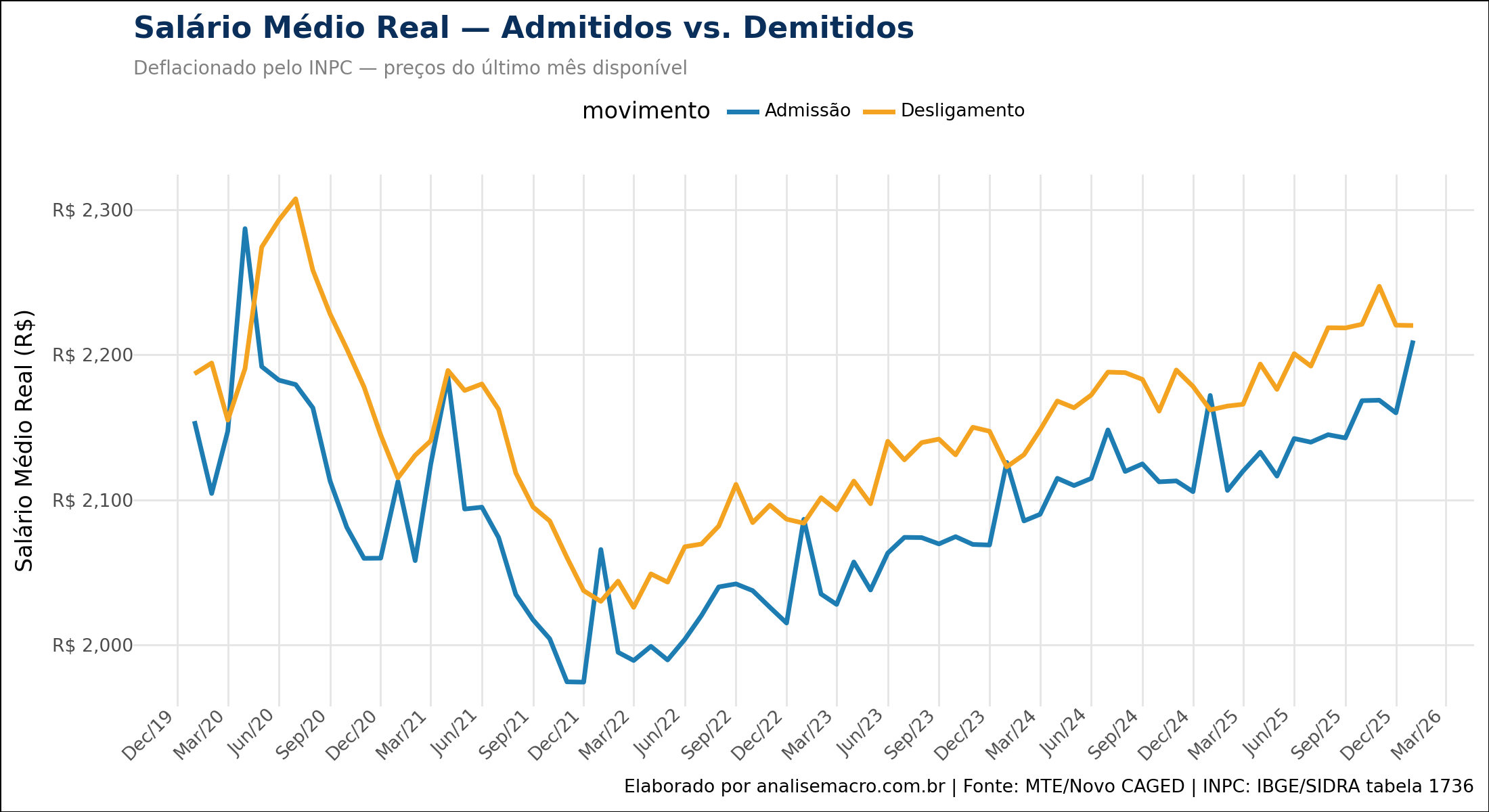
1. Deflacionamento (Salário Real): Através da biblioteca sidrapy, o código consome automaticamente os dados do INPC (Índice Nacional de Preços ao Consumidor) diretamente da API do IBGE (Tabela 1736). Os salários nominais de toda a série histórica foram trazidos para o valor presente (preços do último mês disponível), revelando o verdadeiro poder de compra dos trabalhadores.
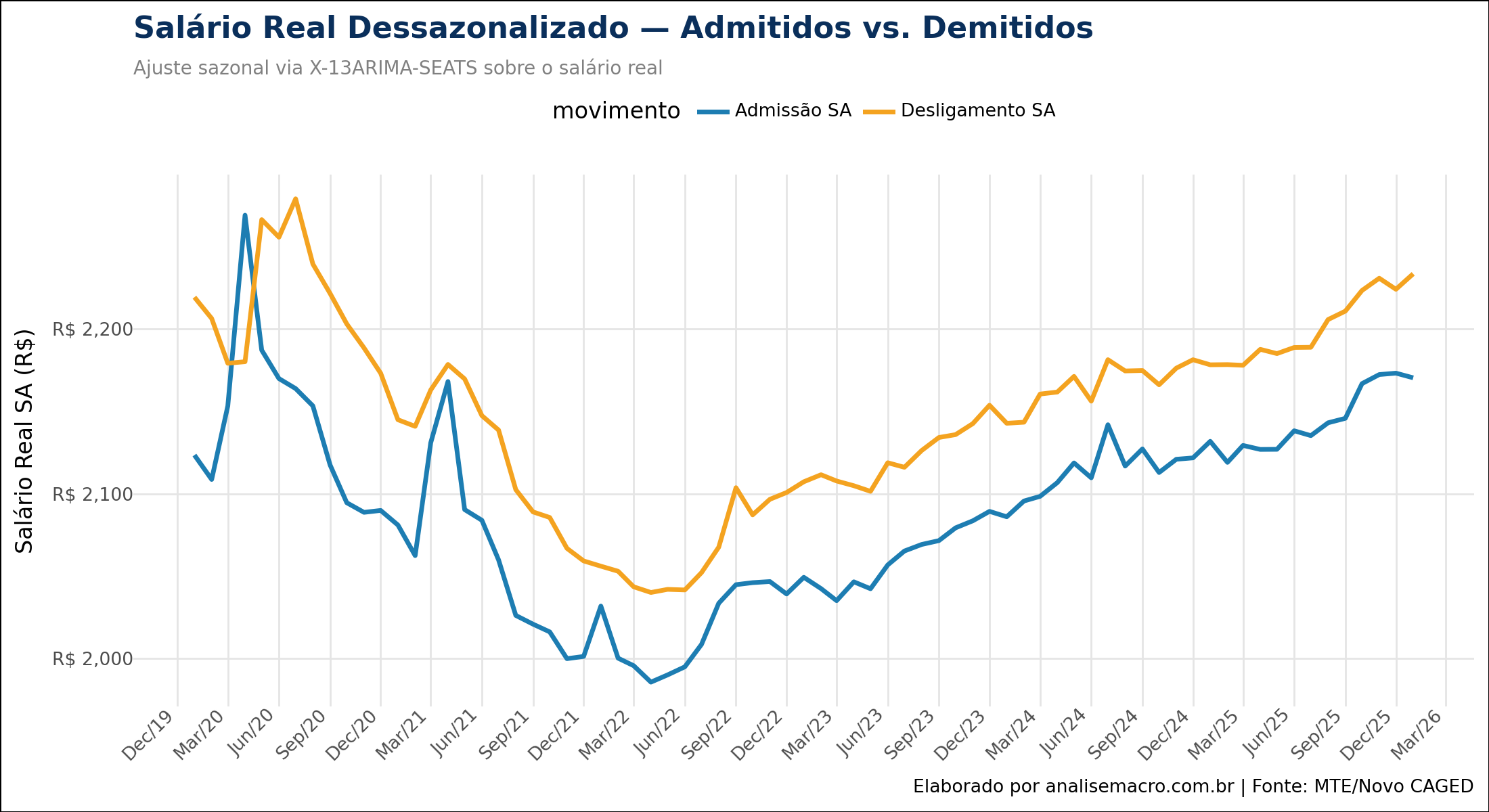
2. Ajuste Sazonal (X-13ARIMA-SEATS): O mercado de trabalho possui forte sazonalidade (ex: contratações temporárias no final do ano, demissões em janeiro). Para enxergar a tendência estrutural dos salários, aplicamos o algoritmo X-13ARIMA-SEATS — o padrão ouro desenvolvido pelo US Census Bureau — integrado ao Python através da biblioteca statsmodels.
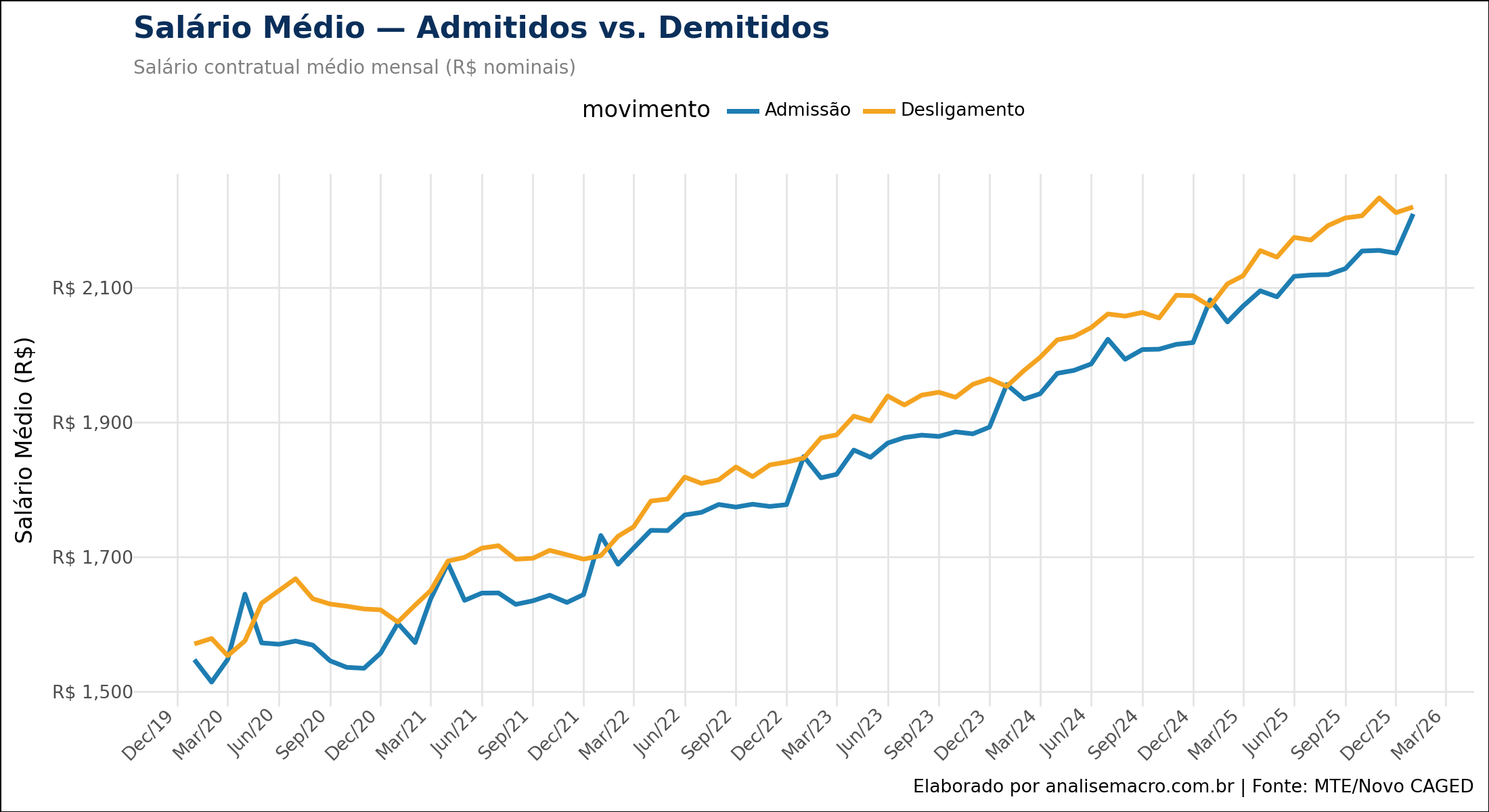
Salários Médios Nominais de Admissão e Demissão CAGED
Salários Médios Reais de Admissão e Demissão CAGED
Salários Médios Reais de Admissão e Demissão CAGED (Sazonalmente Ajustados)