Construímos um agente de IA de coleta de dados que recebe um pedido em português, como “colete o IPCA dos últimos 12 meses”, e decide sozinho onde buscar o dado: no Banco Central ou no IBGE. Ele coleta, confere se o número faz sentido e guarda só o que passou. Quando não tem certeza do que está pegando, ele pergunta, em vez de inventar.
Este agente faz parte do material da Imersão Agentes Autônomos de IA, e é um dos primeiros com um loop real: quem decide qual ferramenta usar, e quantas vezes, é o modelo, e não uma ordem fixa no código. Abaixo está o que ele faz por dentro, com o código do projeto.
É mais fácil ver funcionando. Este é o agente atendendo a três pedidos diferentes no terminal, escolhendo a fonte, coletando e gravando:
No 1º pedido ele vai ao Banco Central; no 2º, ao IBGE, conferindo a combinação antes; no 3º, sem saber o que é a série, ele pergunta em vez de coletar às cegas.
Como o agente de IA de coleta escolhe a fonte
Num agente simples, a ordem das ações fica fixa no código: primeiro listar, depois buscar, sempre nessa sequência. Aqui é diferente. Penduramos duas fontes oficiais no modelo como ferramentas, mandamos o pedido em português, e o próprio modelo lê a descrição de cada uma e escolhe qual chamar.
Em LangGraph, isso é uma aresta condicional. Depois que o agente responde, o grafo olha: ele pediu uma ferramenta? Se sim, executa a ferramenta e volta para o agente. Se não, o trabalho acabou e segue para guardar. Esse vai-e-volta é o loop, e quem decide quantas voltas dar é o modelo.
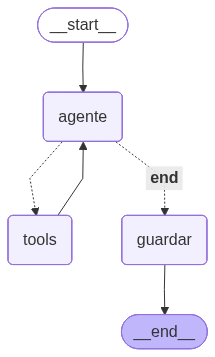
agente, a aresta condicional (tracejada) leva a tools (que volta) ou a guardar. É o loop agêntico.🗣️
🤖
✅
💾
Duas fontes, dois guardrails
O agente fala com duas fontes oficiais, e cada uma exige um cuidado diferente. O motivo é concreto, e só aparece quando você testa as duas APIs.
O Banco Central tem um ponto cego: a API devolve só data e valor, nunca o nome da série. Se você pede a série 433 achando que é a Selic, recebe os números do IPCA e nada avisa. O IBGE, ao contrário, tem uma API de metadados que descreve cada tabela. Com ela dá para conferir a combinação antes de pedir, e recusar a que não existe.
Essa assimetria decide o guardrail de cada fonte. No Banco Central, quando o agente recebe um código que não conhece, ele pergunta o nome ao usuário antes de coletar. No IBGE, ele valida a combinação de tabela e variável contra os metadados e, se algo não bate, recebe um erro que lista o que é válido. Os dois casos têm o mesmo princípio: falhar com uma pergunta clara é melhor que entregar um número errado em silêncio.
Quer acompanhar a construção, agente por agente?
Toda semana publicamos os bastidores de um projeto de IA aplicado à economia brasileira: o que funcionou, o que quebrou e por quê. Assine e receba direto no e-mail.
Validar antes de confiar
Dado coletado não é dado confiável. A API pode devolver um mês a menos, um valor em escala errada, um campo vazio. Se o agente repassa isso adiante sem conferir, o erro reaparece lá na frente, no relatório, quando é caro de achar. Por isso o coletor não termina na coleta: ele coleta, valida e só então guarda.
A validação tem três camadas, e elas vão da mais barata para a mais cara de rodar. Cada uma pega um tipo de erro que a anterior não vê.
A primeira camada confere a forma do dado. Usamos uma biblioteca chamada Pydantic, que verifica se cada ponto da série tem o que deveria ter: a data é mesmo uma data, o valor é mesmo um número, nenhum campo veio vazio. Sem isso, um campo nulo ou um texto onde deveria haver número só estouraria mais tarde, no meio de um cálculo, longe da origem.
A segunda camada confere se o número faz sentido para aquele indicador. Cada série tem uma faixa em que é plausível: o IPCA mensal gira perto de zero, a Selic perto de 15% ao ano, o câmbio perto de 5 reais. Um valor muito fora dessa faixa quase nunca é uma surpresa econômica; é a escala trocada ou a vírgula no lugar errado. A faixa é a defesa contra esse tipo de erro silencioso.
A terceira camada, usada só quando as outras duas não resolvem, é pedir a um modelo barato uma segunda opinião sobre um número que parece estranho no contexto. É o último recurso, porque é o mais lento e o mais caro, e por isso vale uma régua simples: empurre para o código tudo o que o código resolve, e reserve o modelo para o que só ele faz. Validação é quase toda regra fixa, então quase toda ela cabe no código, que é mais rápido, mais barato e mais previsível que uma chamada de IA.
Memória e tolerância a falha
Um agente que roda toda semana não pode recoletar dez anos de IPCA só para pegar o mês novo. A memória de longo prazo resolve isso: o coletor guarda até onde já trouxe e, na próxima vez, busca só o que ainda não tem, ou seja, os meses que faltavam. Em código, a chave é a data: um ponto repetido sobrescreve, não duplica.
E APIs caem. Quem depende de dado de terceiros sabe: o Banco Central entra em manutenção, o IBGE muda um código, a rede oscila. O agente trata isso como rotina. Tenta de novo, dobrando a espera a cada vez (1s, 2s, 4s) para não martelar uma API que já sofre. Se uma biblioteca falha, a ferramenta cai sozinha numa chamada HTTP direta. E, acima disso, o próprio agente pode trocar de fonte: se o Banco Central não trouxe o que precisava, ele tem o IBGE à disposição. A diferença para um script comum é essa: a alternativa de fonte é uma decisão do modelo, não um if cravado no código.
As ferramentas por trás
O que aprendemos construindo
- A descrição da ferramenta é um prompt. O modelo escolhe a fonte lendo a docstring de cada tool. Com duas fontes parecidas, o segredo é fazer as descrições se distinguirem: uma diz “séries de tempo: IPCA, Selic, câmbio”, a outra diz “o IPCA oficial e seus grupos”.
- A mensagem de erro vira conversa. Quando o guardrail do Banco Central recusa uma coleta, o erro volta ao agente como uma mensagem (graças ao
handle_tool_errors), e o agente pergunta o nome ao usuário, em vez de derrubar tudo. - O portal de dados abertos não cobre tudo. Testando, descobrimos que ele tem cerca de um quarto das séries e nem traz o IPCA cheio. Por isso ele é reforço, não garantia: o catálogo curado à mão continua sendo a base.
Perguntas frequentes
O que é um agente de IA para coleta de dados?
É um programa em que um modelo de linguagem decide, a partir de um pedido em linguagem natural, qual fonte oficial consultar e como buscar o dado. Diferente de um script fixo, ele escolhe a ferramenta na hora, lida com erros de API e pode trocar de fonte se a primeira falhar.
Por que o agente precisa de guardrails diferentes para o BCB e o IBGE?
Porque as APIs são diferentes. A do Banco Central devolve só data e valor, sem o nome da série, então o agente pergunta o nome quando não o conhece. A do IBGE tem metadados que descrevem cada tabela, então o agente valida a combinação antes de coletar. O objetivo é o mesmo: não coletar um número sem saber o que ele é.
O agente inventa dados quando a fonte falha?
Não. Essa é uma regra explícita do projeto. Se uma ferramenta falha ou recusa, o agente explica o que aconteceu e o que falta, em vez de preencher com valores fictícios. A validação ainda barra, no código, qualquer número fora da faixa plausível do indicador.
Preciso saber os códigos das séries do Banco Central e do IBGE?
Não para os indicadores comuns. O agente reconhece atalhos como “ipca”, “selic” e “câmbio”. Para uma série específica, você pode passar o código direto. No caso do Banco Central, mande o nome junto, para o agente confirmar o que está coletando.
Construa seus próprios agentes de análise macro
Na Imersão Agentes Autônomos de IA, você monta agentes como este, com código real: agentes que coletam dados oficiais, validam o que recebem e trabalham em time para produzir uma análise. É a mesma stack que usamos aqui.
Leia também:

