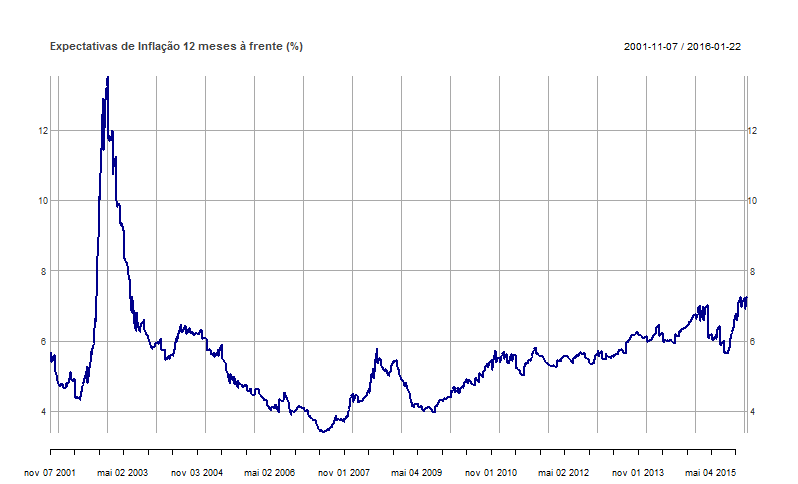
- Inflação, Política Monetária
Enquanto o Banco Central dorme...
- Vitor Wilher
- 26 de janeiro de 2016
- 10:48
Compartilhe esse artigo
Facebook
Twitter
LinkedIn
WhatsApp
Telegram
Email
Print
Boletim AM

Encontre o seu conteúdo
Categorias
- Comentário de Conjuntura
- Cursos da Análise Macro
- Indicadores
- Artigos de Economia
- Hackeando o R
- Data Science
- Política Monetária
- Macroeconometria
- Inflação
- PIB
- Eventos
- Indicação de Leitura Econômica
- Clube AM
- Dados Macroeconômicos
- Mercado financeiro
- Mercado de Trabalho
- Política Fiscal
- Resenhas de Conjuntura Econômica
Artigos mais acessados
Análise Macro © 2011 / 2026
comercial@analisemacro.com.br – Rua Visconde de Pirajá, 414, Sala 718
Ipanema, Rio de Janeiro – RJ – CEP: 22410-002
