Nesta postagem, apresentamos uma introdução ao Balanceamento por Entropia, comparando este método com a técnica de pareamento e demonstrando os resultados obtidos com a implementação do código em R.
Matching, ou pareamento, visa criar grupos de tratamento e controle que sejam comparáveis em termos de suas covariáveis. O objetivo é imitar um experimento randomizado ao parear unidades de tratamento com unidades de controle que têm características semelhantes.+
Uma abordagem comum é o Propensity Score Matching (PSM), onde se calcula a probabilidade de cada unidade receber o tratamento com base em suas covariáveis e, em seguida, cada unidade de tratamento é pareada com uma ou mais unidades de controle que têm escores de propensão semelhantes.
Outras formas de matching incluem o Nearest Neighbor Matching, onde cada unidade de tratamento é pareada com a unidade de controle mais próxima em termos de uma métrica de distância; o Exact Matching, onde as unidades são pareadas exatamente em todas as covariáveis, e o Caliper Matching, que impõe uma tolerância máxima na diferença dos escores de propensão entre as unidades pareadas.
O matching é simples de entender e implementar, e pode reduzir o viés ao criar grupos comparáveis. No entanto, pode resultar em perda de dados se muitas unidades não encontrarem pares adequados, e pode não balancear bem as covariáveis se os grupos forem muito diferentes inicialmente.
Por outro lado, o Entropy Balancing é uma técnica mais recente e sofisticada que ajusta os pesos das unidades no grupo de controle para que as distribuições das covariáveis coincidam entre os grupos de tratamento e controle Hainmueller (2012)
Em vez de agregar, selecionar, e encontrar o par, como no matching, o balanceamento de entropia força restrições na distância entre tratamento e controle. Basicamente, tenta encontrar ajustar os momentos de forma igual para as distribuições do conjunto de tratamento e controle. Por momentos, falamos da média, variância, assimetria, etc.
Entropy balancing garante que as covariáveis sejam balanceadas exatamente em seus momentos e utiliza toda a amostra, o que pode aumentar a eficiência estatística. Além disso, é flexível e pode ser aplicado a muitas situações diferentes. No entanto, pode ser computacionalmente intensivo, especialmente com grandes conjuntos de dados, e requer a especificação de um modelo de pesos, o que pode ser complexo.
Comparando as duas técnicas, o entropy balancing é mais complexo e computacionalmente intensivo do que o matching, mas oferece um ajuste mais preciso das covariáveis. Enquanto o matching pode descartar muitas observações que não encontram pares adequados, o entropy balancing utiliza todas as observações ajustando seus pesos. Além disso, o entropy balancing tende a fornecer um balanceamento mais exato das covariáveis, especialmente quando há muitas covariáveis ou quando as distribuições das covariáveis diferem substancialmente entre os grupos.
Seja aluno da nossa formação Do Zero à Avaliação Prática de Política Públicas com a Linguagem R, e tenha acesso às aulas teóricas e práticas, com o código disponibilizado em R .
Exemplo
Iremos nos basear no estudo de Broockman (2013) e no exemplo de Huntington-Klein (2021).
Neste estudo, Broockman deseja examinar as motivações intrínsecas dos políticos americanos. Ou seja, o que eles farão mesmo sem uma recompensa óbvia? Um exemplo de tal motivação é que os políticos negros nos EUA podem ter um interesse especial em apoiar a comunidade negra americana. Isso faz parte de uma longa linha de pesquisa que examina se os políticos, em geral, oferecem suporte adicional a pessoas como eles.
Para estudar isso, Broockman conduz um experimento. Em 2010, ele enviou uma grande quantidade de e-mails para legisladores estaduais (políticos), simplesmente pedindo informações sobre benefícios de desemprego. A questão é se o legislador responde. Como isso responde à nossa pergunta sobre motivação intrínseca? Porque Broockman varia se o remetente da carta alega morar no distrito do legislador ou em uma cidade distante do distrito. Não há muito benefício direto para um legislador responder a um e-mail de fora do distrito. Essa pessoa não pode votar em você! Mas você ainda pode fazê-lo por senso de dever ou simplesmente por ser uma pessoa gentil.
Broockman então pergunta: os legisladores negros respondem menos frequentemente a e-mails de fora do distrito de pessoas negras do que a e-mails de dentro do distrito de pessoas negras? A resposta é sim. Os legisladores não negros respondem menos a e-mails de fora do distrito de pessoas negras do que a e-mails de dentro do distrito de pessoas negras? Também sim. E então, a grande questão: a diferença entre dentro/fora do distrito é menor para legisladores negros do que para legisladores não negros? Se sim, isso implica que os legisladores negros têm uma motivação intrínseca adicional para ajudar o remetente negro, evidência a favor da hipótese de motivação intrínseca e da hipótese de que legisladores ajudam aqueles que são semelhantes a eles.
Evidências ainda mais fortes repetiriam o mesmo experimento, mas com um remetente branco. Deveríamos ver o mesmo efeito, mas na direção oposta. Se não virmos, então a interpretação adequada pode ser que os legisladores negros são simplesmente pessoas mais prestativas em média.
Onde entra o matching e entropy balancing? Está na última etapa, onde comparamos a diferença dentro/fora do distrito entre legisladores negros e não negros. Esses grupos tendem a ser eleitos em tipos de lugares muito diferentes. Há muitas variáveis ocultas.
Podemos utilizar um dos dois métodos para criar um grupo de comparação melhor. No estudo original, Broockman usou a renda média das famílias no distrito, a porcentagem da população do distrito que é negra e se o legislador é democrata como variáveis de pareamento.
Vamos realizar o pré-processamento das variáveis usando entropy balancing através do pacote {ebal}, que disponibiliza diversas funções e opções de uso do método. Com a obtenção da nova distribuição, encontramos o efeito causal da intervenção usando uma regressão via WLS (weighted least squares) em que os pesos utilizados referem-se aqueles obtidos pelo Balanceamento por Entropia.
# Carregar as bibliotecas necessárias
library(ebal)
library(tidyverse)
library(modelsummary)
br <- causaldata::black_politicians
# Definir a variável de desfecho (Outcome)
Y <- br |>
dplyr::pull(responded)
# Definir a variável de tratamento (Treatment)
D <- br |>
dplyr::pull(leg_black)
# Definir as variáveis de pareamento (Matching variables)
X <- br %>%
dplyr::select(medianhhincom, blackpercent, leg_democrat) |>
# Adicionar termos quadráticos para combinar variâncias, se desejado
dplyr::mutate(incsq = medianhhincom^2,
bpsq = blackpercent^2) |>
as.matrix()
# Realizar o balanceamento por entropia
eb <- ebal::ebalance(D, X)Converged within tolerance # Obter os pesos para uso posterior
# Observando que isso contém apenas pesos dos controles
br_treat <- br |>
dplyr::filter(leg_black == 1) |>
dplyr::mutate(weights = 1) # Pesos dos tratados são 1
br_con <- br |>
dplyr::filter(leg_black == 0) |>
dplyr::mutate(weights = eb$w) # Aplicar os pesos calculados aos controles
# Combinar os dados tratados e de controle em um único dataframe
br_ebal <- dplyr::bind_rows(br_treat, br_con)
# Ajustar o modelo de regressão linear ponderado
m <- lm(responded ~ leg_black, data = br_ebal, weights = weights)
# Resumir os resultados do modelo
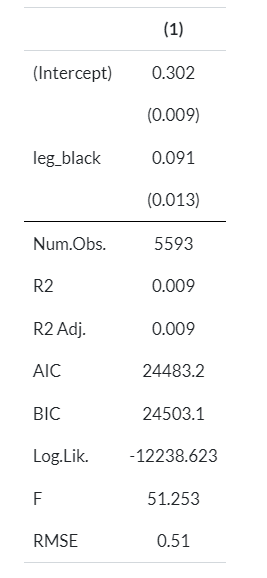
msummary(m)Abaixo, o resultado da regressão via WLS, após obter os pesos da Balanceamento por Entropia.
| (1) | |
|---|---|
| (Intercept) | 0.302 |
| (0.009) | |
| leg_black | 0.091 |
| (0.013) | |
| Num.Obs. | 5593 |
| R2 | 0.009 |
| R2 Adj. | 0.009 |
| AIC | 24483.2 |
| BIC | 24503.1 |
| Log.Lik. | -12238.623 |
| F | 51.253 |
| RMSE | 0.51 |
Referências
Broockman, David E. 2013. “Black Politicians Are More Intrinsically Motivated to Advance Blacks’ Interests: A Field Experiment Manipulating Political Incentives.” American Journal of Political Science 57 (3): 521–36.
Hainmueller, Jens. 2012. “Entropy Balancing for Causal Effects: A Multivariate Reweighting Method to Produce Balanced Samples in Observational Studies.” Political Analysis 20 (1): 25–46.)
Huntington-Klein, N. (2021). The Effect: An Introduction to Research Design and Causality (1st ed.). Chapman and Hall/CRC.

