No mês de dezembro, iremos lançar uma nova versão do Clube do Código, que se chamará Clube AM. O projeto de compartilhamento de códigos da Análise Macro vai avançar para uma versão 2.0, que incluirá a existência de um grupo fechado no Whatsapp, de modo a reunir os membros do Novo Clube, compartilhando com eles todos os códigos dos nossos posts feitos aqui no Blog, exercícios de análise de dados de maior fôlego, bem como tirar dúvidas sobre todos os nossos projetos, exercícios e nossos Cursos e Formações.
Para ilustrar o que vamos compartilhar lá nesse novo ambiente, estou publicando nesse espaço alguns dos nossos exercícios de análise de dados. Esses exercícios fazem parte do repositório atual do Clube do Código, que deixará de existir. Além de todos os exercícios existentes no Clube do Código, vamos adicionar novos exercícios e códigos toda semana, mantendo os membros atualizados sobre o que há de mais avançado em análise de dados, econometria, machine learning, forecasting e R.
Hoje, graças à excelente base de dados do Instituto de Segurança Pública (ISP), vamos falar da relação entre violência e desemprego. Quando se trata de violência carioca, uma pergunta imediata é quais seriam os fatores relevantes para explicar os diversos aspectos da criminalidade no Rio de Janeiro. Pensando nisso, resolvemos fazer um exercício empírico no âmbito do Clube do Código.
Becker (1968) define a decisão de cometer um crime como um processo racional, onde o potencial criminoso calcularia custos e benefícios para então decidir se vai em frente ou não. A partir desse trabalho seminal, uma extensa literatura teórica e empírica tem sido desenvolvida, relacionando diversos fatores econômicos que impactam nos custos e benefícios da decisão de cometer um crime.
O script, então, começa com alguns pacotes.
library(readr) library(lubridate) library(magrittr) library(dplyr) library(ggplot2) library(scales) library(sidrar) library(corrplot) library(forecast) library(dplyr) library(dynlm) library(lmtest) library(CADFtest) library(gridExtra) library(stargazer)
Na sequência, nós importamos os dados que precisaremos. Vamos basicamente importar uma planilha disponível no ISP que contém diversas séries temporais envolvendo crimes no Rio de Janeiro. Além disso, vamos importar a taxa de desemprego, disponível no site do SIDRA/IBGE.
url = 'http://www.ispdados.rj.gov.br/Arquivos/DOMensalEstadoDesde1991.csv'
download.file(url, destfile='basededados.csv', mode='wb')
data = read_csv2('basededados.csv') %>%
mutate(date = make_datetime(ano, mes))
desemprego = ts(get_sidra(api='/t/6381/n1/all/v/4099/p/all/d/v4099%201')$Valor,
start=c(2012,03), freq=12)
Uma vez que pegamos os dados que precisamos, nós podemos fazer algum tratamento dos mesmos.
data_ts = ts(data[,-c(1,2,57)], start=c(1991,01), freq=12) data_ts = ts.intersect(data_ts, desemprego) colnames(data_ts) = c(colnames(data[,-c(1,2,57)]), 'desemprego')
Com os dados tratados, podemos fazer um gráfico de correlação entre a série de desemprego e as séries de total de roubos e homicídios dolosos.
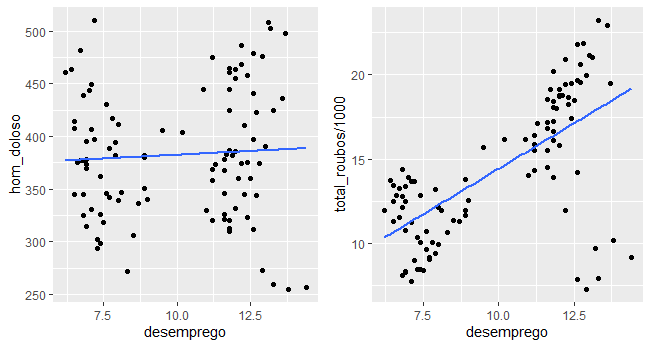
Os gráficos acima relacionam o total de roubos e os homicídios dolosos no Rio de Janeiro à taxa de desemprego medida pela PNAD Contínua. O desemprego funciona como uma proxy para a situação econômica do país. Como é possível ver, há uma diferença importante na correlação entre os dois tipos de crimes. Enquanto os homicídios são apenas levemente correlacionados com o desemprego, há uma correlação mais forte entre esta e o total de roubos.
Com base nessas variáveis, nós podemos criar um modelo de regressão linear que relaciona as variáveis de crime à taxa de desemprego. A tabela abaixo traz, por seu turno, os resultados das regressões do total de roubos e dos homicídios dolosos contra a taxa de desemprego. De modo a prevenir regressões espúrias, no exercício completo disponível no repositório do Clube do Código, nós testamos as especificações usando o teste CADF, de onde conseguimos rejeitar a hipótese nula de ausência de cointegração. Os modelos, contudo, são bastante distintos em termos de ajuste. Enquanto o desemprego (e mais uma dummy) explicam parte importante da variação do total de roubos, ele explica muito pouco da variação dos homicídios dolosos. Esses resultados, a propósito, estão em linha com Levitt (1997), que mostrou que a taxa de desemprego afeta os crimes contra a propriedade, mas não os crimes violentos.
| Dependent variable: | ||
| total_roubos | hom_doloso | |
| (1) | (2) | |
| desemprego | 1,116.398*** | 1.425 |
| (125.847) | (2.420) | |
| dummy | -8,374.023** | |
| (3,193.210) | ||
| Constant | 3,351.565** | 368.084*** |
| (1,294.057) | (24.961) | |
| Observations | 102 | 102 |
| R2 | 0.450 | 0.003 |
| Adjusted R2 | 0.439 | -0.007 |
| Residual Std. Error | 3,151.768 (df = 99) | 61.098 (df = 100) |
| F Statistic | 40.484*** (df = 2; 99) | 0.347 (df = 1; 100) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | |
__________________
(*) Cadastre-se aqui na nossa Lista VIP para receber um super desconto na abertura das Turmas 2021.


