Neste post iremos revelar algumas coisas que nunca te contaram sobre análise exploratória e como usá-la para ter uma visão geral aplicada a dados macroeconômicos.
Antes de tudo, precisamos entender onde a análise exploratória de dados - do inglês exploratory data analysis (EDA) - está inserida no contexto de uma análise descritiva ou em modelos que usem dados macroeconômicos. Para tais contextos, é fundamental conhecer os dados antes de partir para qualquer exercício empírico, ou seja, queremos uma fotografia que mostre um panorama geral sobre os dados. Esse primeiro passo é extremamente útil para identificar possíveis "pontos cegos" que gerariam problemas no seu modelo ou que poderiam ser interpretados de forma errônea em sua análise conjuntural, por exemplo.
Em outras palavras, a famosa expressão garbage in, garbage out (lixo entra, lixo sai) resume perfeitamente a importância da análise exploratória. Você precisa saber se os dados a serem utilizados possuem a qualidade (características) necessária para fazer uma análise ou se estão simplesmente cheios de sujeiras (outliers, valores ausentes, quebras, etc.). É neste momento em que você aprenderá mais sobre os dados, identificando padrões e comportamentos, assim como saberá o que precisará fazer (tratamentos) para torná-los úteis.
Mas de que tipo de dados estamos falando?
Em geral, os dados macroeconômicos mais usados possuem uma estrutura de série temporal, mas outras estruturas como dados em painel, microdados, etc. também possuem aplicações em macroeconomia. Focando em séries temporais, pode-se destacar algumas coisas que você deve ficar de olho ao fazer uma análise exploratória de dados:
- Sazonalidade;
- Tendência;
- Autocorrelação;
- Estacionariedade.
Algumas estatísticas e gráficos que irão te ajudar a inspecionar estes padrões e comportamentos:
- Média, mediana, desvio padrão e IQR;
- Gráfico de histograma;
- Gráfico de linha;
- Gráfico de sazonalidade;
- Correlogramas ACF e PACF;
- Testes de estacionariedade ADF, KPSS e PP.
Parece ser bastante coisa para se preocupar em uma análise exploratória e realmente é - podendo ainda ampliarmos este escopo -, mas se usarmos as ferramentas adequadas podemos colocar tudo isso em prática de maneira rápida e eficiente, direcionando o foco na análise propriamente dita. Na linguagem R, existem diversos pacotes modernos com utilidades para análise exploratória de dados, exploraremos a seguir alguns destes pacotes.
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes de R:
Dados
Para exemplificar uma análise exploratória de dados macroeconômicos, usaremos um conjunto de dados que traz informações sobre indicadores econômicos mensais da economia norte-americana. A fonte dos dados é o FRED e os mesmos já estão salvos em um dataset no R:
Estatísticas descritivas
As medidas de estatística descritiva, como média, desvio padrão, percentis, etc. servem para obter uma visão geral dos dados. É um bom primeiro passo se você não tem expertise sobre a variável com a qual irá desenvolver uma análise. O pacote {skimr} faz esse trabalho de calcular estas estatísticas de uma maneira simples e bem apresentada, basta apontar o objeto com os dados:
Note que, além das estatísticas descritivas, também são apresentadas informações como nº e taxa de valores ausentes, gráfico de histograma, valores mínimos e máximas, etc. - a depender do tipo de variável na qual será computado tais cálculos -, que são informações bastante úteis para identificar possíveis problemas nos dados.
Histograma
Talvez apenas com estatísticas descritivas não seja possível ter uma visão clara sobre o comportamento da variável de interesse, ou seja, como os dados estão distribuídos. Para resolver isso, é conveniente gerar um gráfico de histograma, que pode ser criado com o {ggplot2}:
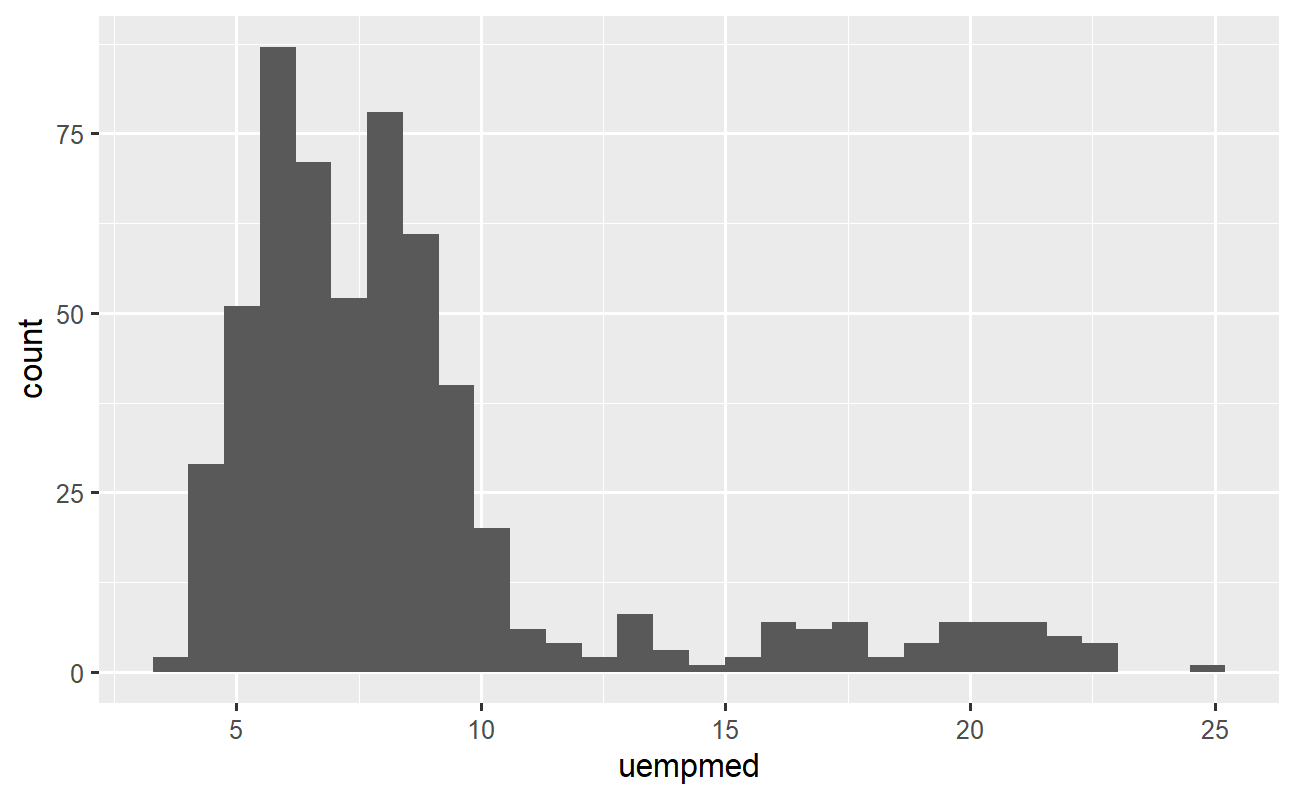
A visualização gráfica dos dados é muito importante pois nos permite rapidamente identificar nos dados algumas coisas interessantes, como neste caso do histograma. A distribuição dos dados apresenta uma cauda alongada a direita, ou seja, possivelmente há algumas poucas observações dessa variável (duração do desemprego) com valores mais "extremos". A questão que surge é: em qual período do tempo aconteceram estes valores? Ou seja, qual é a tendência da variável?
Tendência
O jeito mais direto de identificar a tendência de uma variável é através de um gráfico de linha. Abaixo geramos um gráfico de linha e adicionamos uma linha de suavização, que pode facilitar o rápido entendimento em alguns casos:
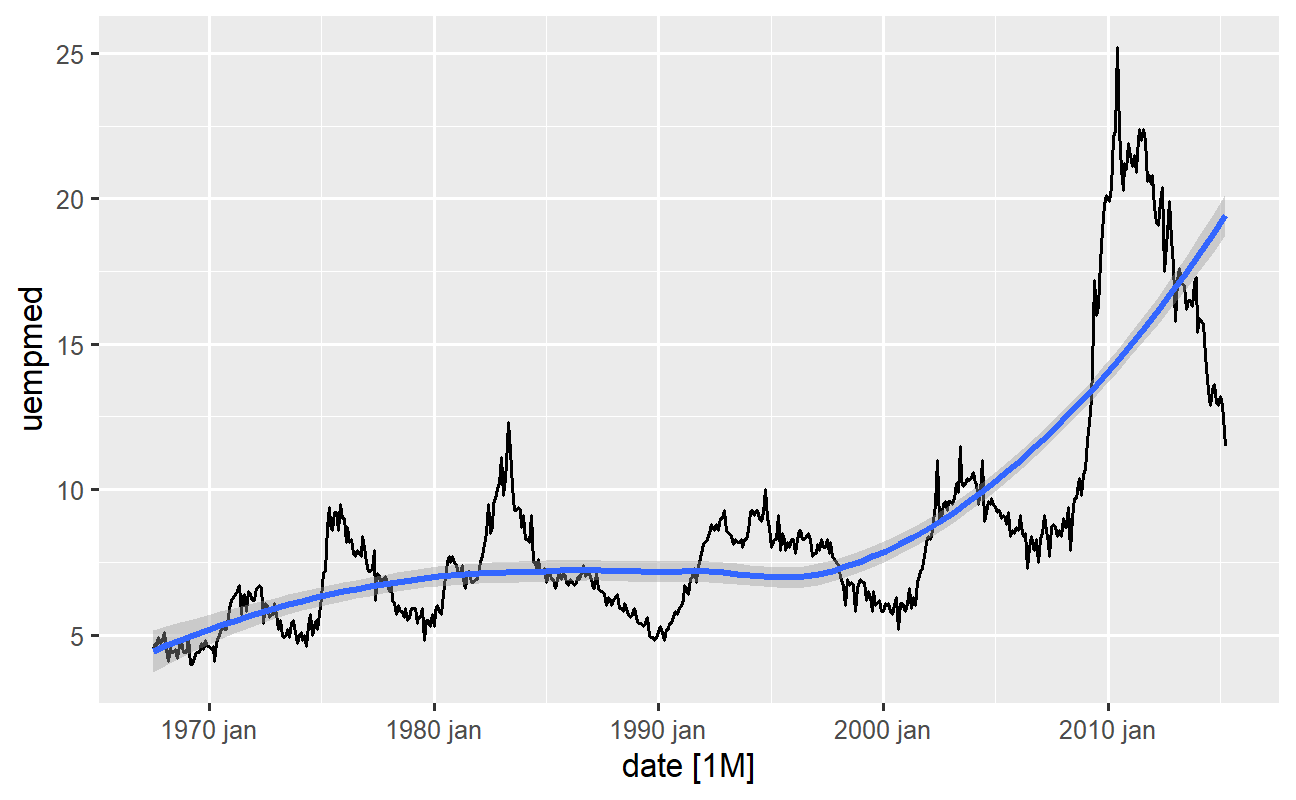
Dessa forma, conseguimos identificar que no período mais recente, ou seja, nas últimas observações a partir de 2010, há uma tendência de aumento no tempo de duração do desemprego, superando o histórico observado nas décadas anteriores. Note que, com apenas dois gráficos e algumas estatísticas descritivas, já conseguimos insumos interessantes para uma análise mais aprofundada.
Sazonalidade
A olho nu no gráfico anterior não parece haver comportamento que indique sazonalidade, mas como poderíamos identificar tal comportamento em uma variável? Novamente, a análise gráfica pode auxiliar nessa tarefa. O gráfico de sazonalidade gerado abaixo basicamente é um gráfico de linha, com a exceção de que o eixo X mostra os dados da sazonalidade observada da variável. No caso de dados em frequência mensal, o eixo X será os meses.

O gráfico facilita identificar mais claramente padrões sazonais, que para essa variável não há, além de ser mais fácil de visualizar em quais anos que o padrão muda.
Estacionariedade
Outro ponto importante, principalmente em contextos de modelagem econométrica, é a estacionariedade da série, ou seja, a média e a variância são constantes ao longo do tempo? Quando em uma variável estes pressupostos não são verdadeiros, dizemos que a série possui raiz unitária (é não-estacionária), de modo que os choques que a variável sofre geram um efeito permanente. Parece ter sido esse o caso da variável em questão, a duração do desemprego. Vimos que as flutuações da variável se alteraram consideravelmente, e isso tem fortes implicações relacionadas a teorias econômicas que tratam de ciclos. Mas, fugindo da teoria, como verificamos de maneira prática se a variável é estacionária? O pacote {forecast} possui uma excelente função permitindo aplicar testes, como o ADF, KPSS e PP, que já retornam o número de diferenças necessárias para a série ser estacionária:
Se o valor retornado for maior do que zero, significa que a série é não-estacionária e precisa ser diferenciada na ordem do valor retornado para ser estacionária.
Autocorrelação
Por fim, outra questão importante em séries temporais é a identificação de possíveis correlações (a relação linear) entre os valores defasados da série. Os correlogramas ACF e PACF podem ajudar neste ponto. Como a série não possui sazonalidade mas possui uma certa tendência, as autocorrelações iniciais tendem a ser grandes e positivas pois as observações próximas no tempo também estão próximas em valor. Assim, a função de autocorrelação (ACF) de uma série temporal com tendência tende a ter valores positivos que diminuem lentamente à medida que as defasagens aumentam.
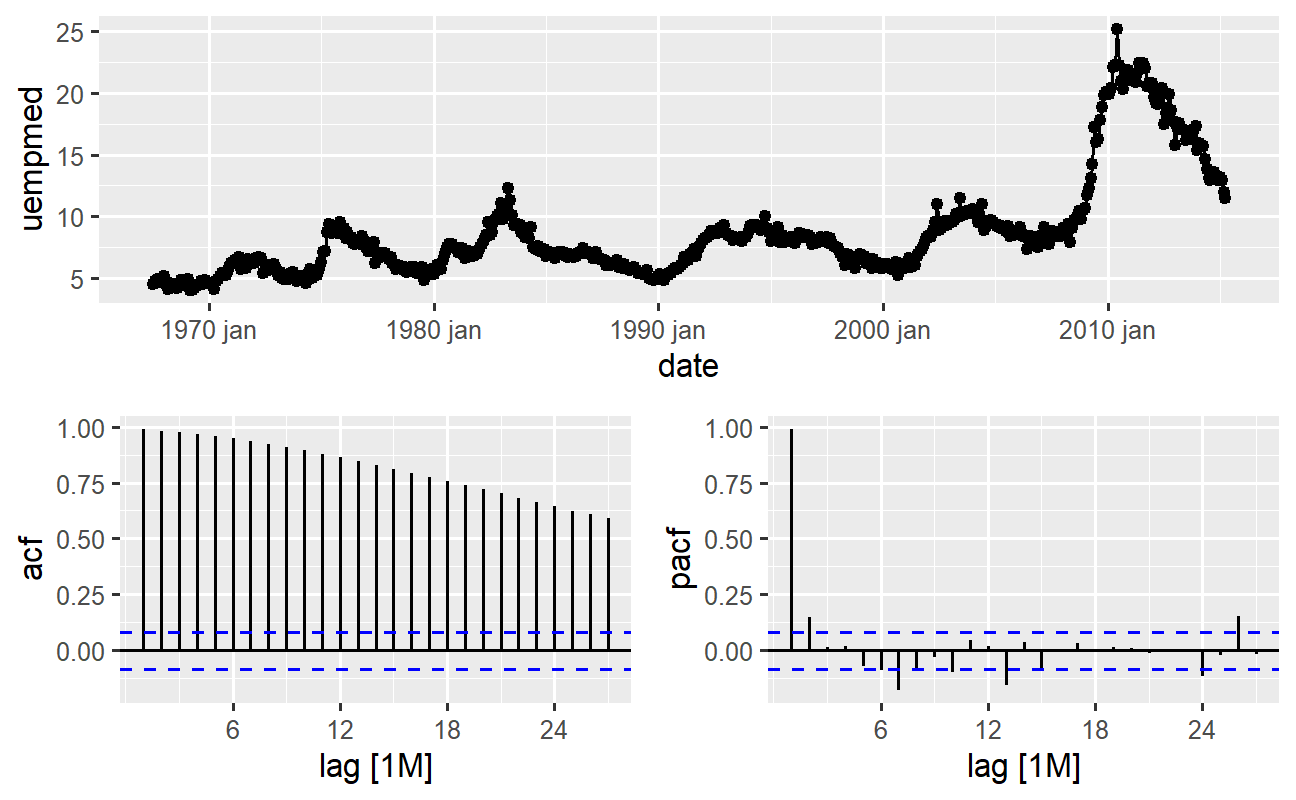
Se fôssemos, por exemplo, implementar uma modelagem ARIMA nessa série, seria apropriado gerar os correlogramas na série estacionária, ou seja, a variável duração do desemprego na primeira diferença.
Saiba mais
Veja nossos cursos de Macroeconomia através da nossa trilha de Macroeconomia Aplicada.
Este exercício buscou navegar pelos principais padrões e comportamentos de dados macroeconômicos, usando ferramentas do R para identificá-los. você pode se aprofundar sobre os assuntos relacionados nestes posts do blog da Análise Macro:
- 5 armadilhas dos dados (macro)econômicos no Brasil
- Como extrair componentes de tendência e sazonalidade de uma série temporal
- {tidyverts}: séries temporais no R
- Gerando previsões desagregadas de séries temporais
- Como criar defasagens de uma variável no R
- Como reverter a primeira diferença de uma série temporal?
- Visualizando dados com ggplot2
- Como importar dados do Banco Central, IPEADATA e Sidra no R?

