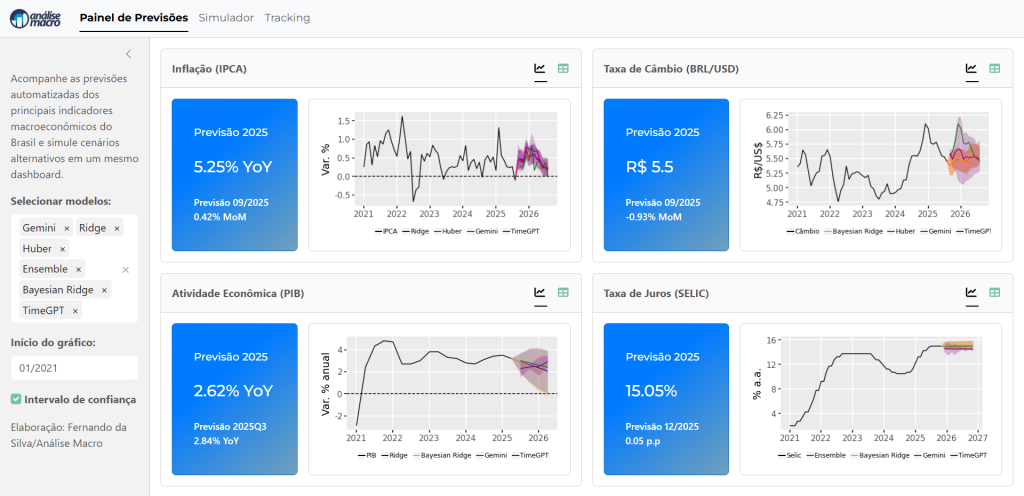
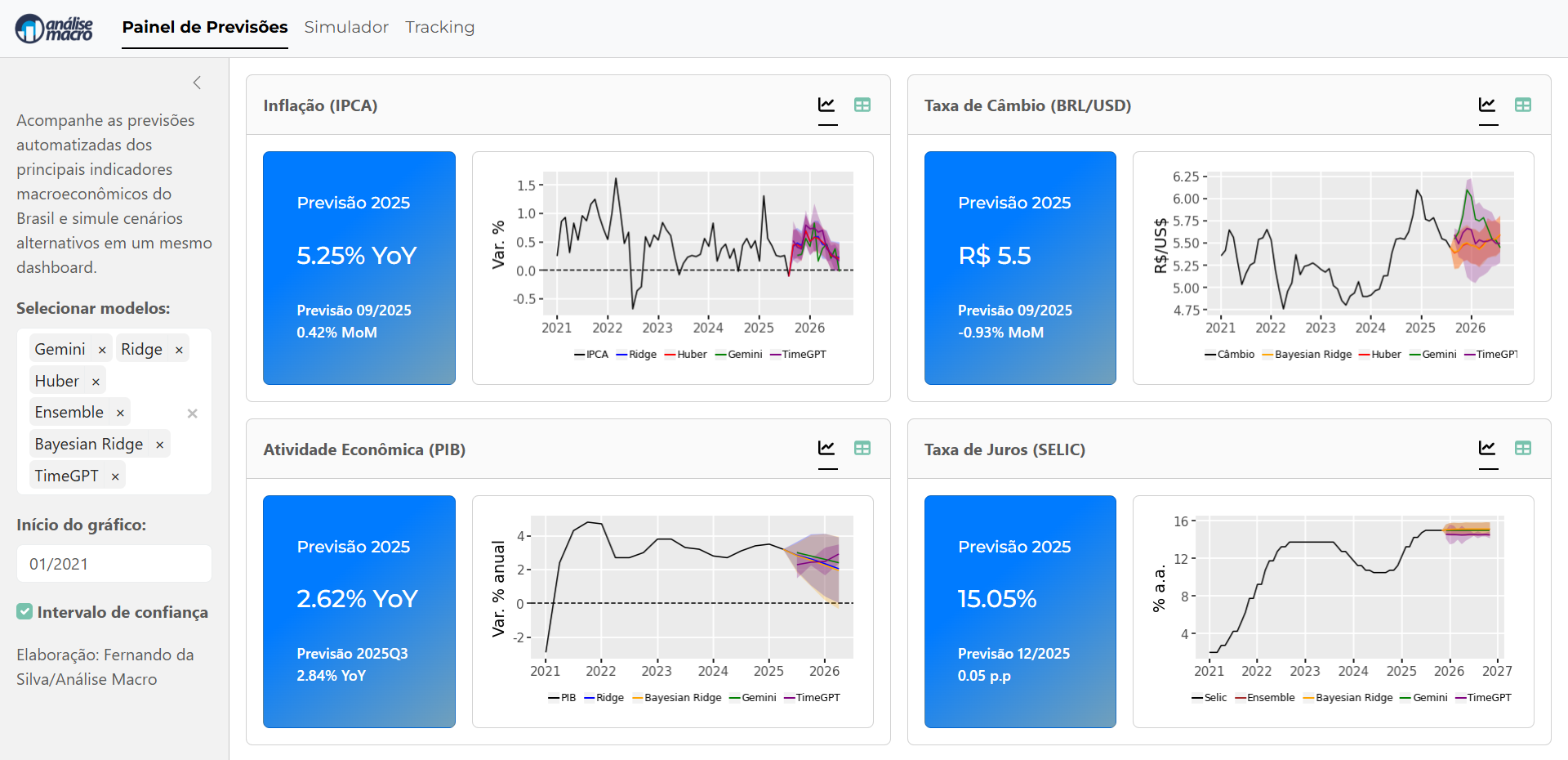
Montar um pipeline de previsão macroeconômica não é apenas uma tarefa técnica — é um exercício de integração entre dados, modelos e automação. Neste post, apresento uma visão geral de como estruturar esse processo de ponta a ponta, da coleta de dados até a construção de um dashboard interativo como o da imagem abaixo, que exibe previsões automatizadas de inflação, câmbio, PIB e taxa Selic.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
1. O ponto de partida: a coleta e integração dos dados
A base de qualquer previsão confiável é a qualidade dos dados. O primeiro estágio do pipeline consiste em reunir e padronizar séries históricas provenientes de diferentes fontes — no caso do projeto, foram utilizados dados do BCB, IBGE, IPEA e FRED.
O script 05-disponibilizacao.py, por exemplo, faz exatamente isso: ele cria uma estrutura organizada com frequências diária, mensal, trimestral e anual, salvando tudo em formato Parquet para uso posterior. Essa etapa garante que os dados estejam limpos, coerentes e prontos para alimentar os modelos.
Essa organização modular facilita tanto a atualização automática quanto o reaproveitamento das bases por outros indicadores.
2. A modelagem: unindo econometria, machine learning e IA
A segunda etapa é a modelagem preditiva. Nela, o foco é combinar diferentes abordagens — econométricas e de aprendizado de máquina — para capturar a dinâmica dos principais indicadores.
O arquivo 09-selic.py, por exemplo, ilustra bem essa integração. Nele, a taxa Selic é prevista a partir de modelos econométricos clássicos (usando medidas como o hiato do produto e hiato da inflação) e algoritmos modernos, como Ridge Regression, Bayesian Ridge e Voting Regressor.
Além disso, são incorporadas previsões com modelos generativos de IA (Gemini) e modelos de séries temporais foundation (TimeGPT, da Nixtla), permitindo comparar a performance entre abordagens estatísticas, híbridas e de IA.
O pipeline também inclui:
-
Tratamento de transformações logarítmicas e diferenciações conforme metadados definidos em planilha.
-
Cenários de simulação baseados em expectativas de inflação (Focus/BCB).
-
Intervalos de confiança com bootstrapping para medir incertezas.
3. Integração com modelos de IA e APIs externas
A inovação do pipeline está na integração direta com APIs.
O script utiliza:
-
Gemini (Google) para gerar previsões em linguagem natural a partir de séries históricas, via prompt de texto;
-
TimeGPT (Nixtla) para previsões automáticas de séries temporais com embeddings especializados.
Essas integrações são feitas de forma reproduzível, garantindo previsões atualizadas automaticamente conforme novos dados chegam.
4. Armazenamento e tracking das previsões
Todas as previsões são salvas em arquivos Parquet e registradas em um tracking histórico, permitindo comparar o erro preditivo dos modelos ao longo do tempo.
Esse histórico é fundamental para calibrar modelos, ajustar pesos em ensembles e monitorar a consistência das previsões ao longo dos meses.
5. Visualização e automação: o dashboard final
O resultado final é o Painel de Previsões Macroeconômicas, desenvolvido em Python com frameworks como Shiny.
O dashboard mostra as previsões mais recentes com seus intervalos de confiança e permite comparar modelos, explorar cenários alternativos e acompanhar as atualizações automáticas de cada indicador.
6. Ferramentas e habilidades envolvidas
Para quem deseja construir algo semelhante, vale dominar as seguintes competências:
-
Coleta e integração de dados públicos (APIs do BCB, IBGE, IPEA, FRED)
-
Manipulação de dados em pandas e parquet
-
Modelagem econométrica e machine learning
-
Automação de pipelines e versionamento
-
Desenvolvimento de dashboards com Shiny
-
Uso de APIs de IA (Gemini, TimeGPT, OpenAI etc.)
Conclusão
Planejar um pipeline de previsão macroeconômica é um exercício multidisciplinar que conecta econometria, ciência de dados e inteligência artificial.
A automatização de todo o fluxo — da coleta ao dashboard — reduz o tempo entre atualização dos dados e entrega de insights, tornando o processo de monitoramento econômico muito mais ágil e replicável.
Se você quer aprender como construir esse pipeline passo a passo, participe da Imersão “Econometria vs. IA na Previsão Macro”, onde exploramos detalhadamente a integração de modelos, APIs e dashboards automatizados aplicados à economia brasileira.

