
Como mensalizar dados diários? Ou como filtrar os valores máximos para diversas categorias em uma tabela de dados usando Python? Estas perguntas são respondidas com os métodos de operações por grupos. Neste tutorial mostramos estes métodos disponíveis na biblioteca pandas, que tem como vantagem sua sintaxe simples e prática.
Operações por grupos de dados é uma etapa presente em quase todo tratamento/limpeza de dados. Afinal, com tabelas de dados cada vez maiores, é necessário tratar e processar os valores para a análise dos dados. Sendo assim, vamos a um exemplo prático.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Dados de exemplo
Primeiro, coletamos online uma tabela de dados CSV de exemplo. A fonte dos dados é o Banco Central do Brasil e para coletar os dados também usamos a biblioteca pandas. Abaixo uma visão geral da tabela:
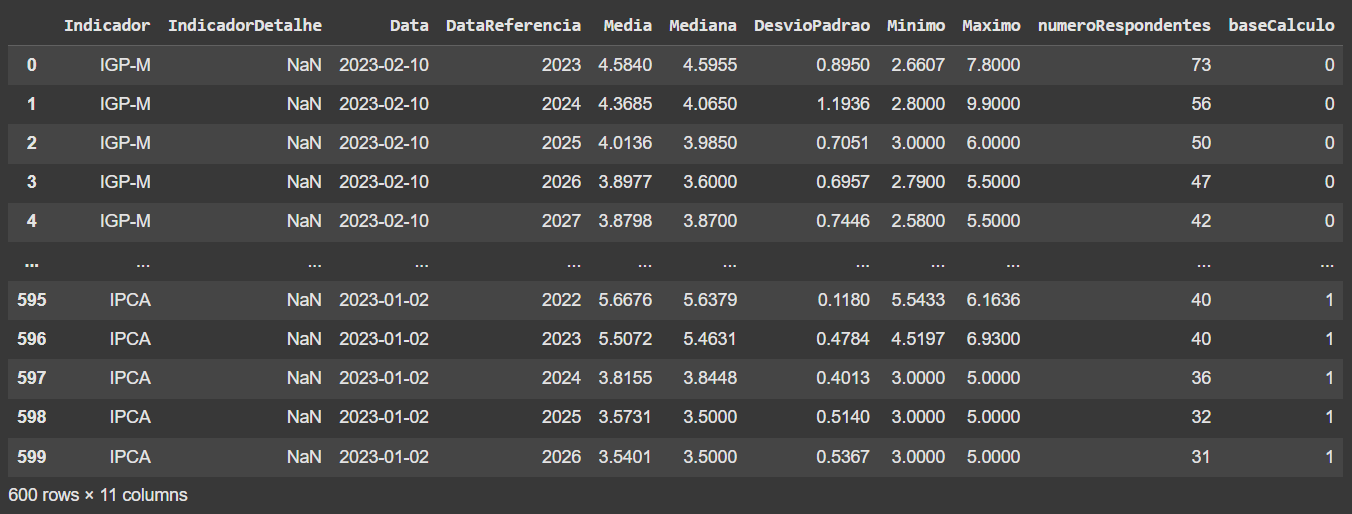
Como fazer operações por grupos de dados?
Diversas operações de manipulação de dados são feitas por grupos de valores definidos em variáveis/colunas. Por exemplo, suponha que você tenha dados diários de uma variável numérica e que precise obter uma média mensal da mesma. Neste contexto, o grupo é o conjunto de valores dentro de cada mês/ano e, para cada um destes n conjuntos de valores/grupos, o cálculo da média deve ser aplicado para obter o resultado desejado. Se os grupos não forem definidos a média da variável seria de toda a amostra de dados, o que não seria o resultado desejado.
Para definir os grupos, e realizar uma operação nos mesmos, use groupby() com a sintaxe tabela.groupby(by = grupos), onde grupos é o nome da coluna cujos valores definem os grupos (ou uma lista de nomes).
A função groupby() divide o DataFrame de modo que uma operação (função) aplicada na sequência é realiza pelos grupos definidos. Por exemplo, a seguir aplicamos um filtro para obter as primeiras linhas de cada grupo com a função head():
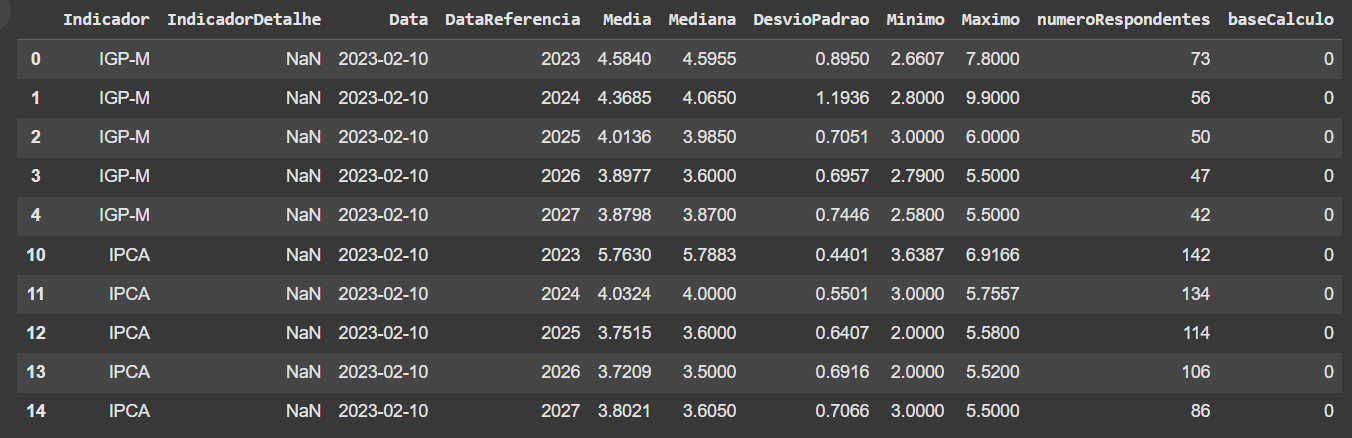
Outra possibilidade é especificar mais de um agrupamento para os dados, ou seja, você pode definir grupos por quantas colunas precisar para realizar uma operação.
Para funções simples como head(), aplicadas sobre os grupos, o retorno será um DataFrame com estrutura semelhante a tabela anterior à operação. Em outros casos, pode ser que o DataFrame retornado contenha um novo index. Por exemplo, abaixo agrupamos a tabela e usamos a função apply() para filtrar a Data e DataReferencia máxima e o retorno possui como index os grupos definidos:

Para evitar isso pode ser interessante usar group_keys = False em groupby().Para saber mais consulte a documentação da biblioteca.
Conclusão
Como mensalizar dados diários? Ou como filtrar os valores máximos para diversas categorias em uma tabela de dados usando Python? Estas perguntas são respondidas com os métodos de operações por grupos. Neste tutorial mostramos estes métodos disponíveis na biblioteca pandas, que tem como vantagem sua sintaxe simples e prática.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

