Com o R, é possível acessar diversas bases de dados e baixar o que precisa diretamente para o RStudio. Um exemplo disso são os microdados da PNAD Covid. Nessa Dicas de R - disponível toda quarta-feira aqui no blog da AM -vamos mostrar como pegar esses dados diretamente do ftp do IBGE. Como de praxe, o código começa carregando alguns pacotes que utilizaremos.
library(tidyverse)
A seguir, nós podemos fazer o download dos dados diretamente do FTP do IBGE. Escolhemos os últimos microdados disponíveis da PNAD Covid.
## Baixar os dados via ftp
url = "ftp://ftp.ibge.gov.br/Trabalho_e_Rendimento/Pesquisa_Nacional_por_Amostra_de_Domicilios_PNAD_COVID19/Microdados/Dados/PNAD_COVID_112020.zip"
download.file(url, destfile='PNAD_COVID_112020.zip', mode='wb')
unzip('PNAD_COVID_112020.zip')
pnad_covid <- read_csv("PNAD_COVID_112020.csv",
col_types = cols(.default = "d"))
No código acima, é preciso observar que estamos baixando os dados para a pasta previamente setada no RStudio. Baixado os dados e importado para o RStudio, podemos agora baixar também o dicionário dos dados.
## Baixar o dicionário dos dados url_2 = "ftp://ftp.ibge.gov.br/Trabalho_e_Rendimento/Pesquisa_Nacional_por_Amostra_de_Domicilios_PNAD_COVID19/Microdados/Documentacao/Dicionario_PNAD_COVID_112020.xls" download.file(url_2, destfile='Dicionario_PNAD_COVID_112020.xls', mode='wb')
De posse desses dados, podemos agora explorá-los. Vamos supor que estamos interessados em saber quem recebeu o auxílio emergencial do governo por tipo de trabalho que a pessoa ocupa. Esse foi o questionamento do meu aluno Rodrigo Ashikawa, da nossa Formação Data Science para Economistas, que acabou me dando a ideia desse Dicas de R de hoje.
Com o código a seguir, nós criamos uma nova variável com o tipo de trabalho que a pessoa ocupa, de acordo com o dicionário dos microdados da pesquisa.
pnad_covid <- mutate(pnad_covid, tipo_emprego = case_when( C007 == 1 ~ "Trabalhador Doméstico", C007 == 2 ~ "Militar", C007 == 3 ~ "Policial ou Bombeiro", C007 == 4 ~ "Setor Privado", C007 == 5 ~ "Setor Público", C007 == 6 ~ "Empregador", C007 == 7 ~ "Conta Própria", C007 == 8 ~ "Trabalhador Familiar", C007 == 9 ~ "Fora do mercado", is.na(C007) ~ 'Não informado'))
Uma vez feito isso, nós podemos agora selecionar as variáveis que queremos dos dados e também criar uma nova variável dummy que diz se a pessoa recebeu ou não o auxílio emergencial. O código a seguir implementa.
auxilio_emprego <- select(pnad_covid, D0051, tipo_emprego) %>% mutate(auxilio_emergencial = ifelse(D0051 == 1, "Sim", "Não"))
Por fim, nós podemos agrupar os nossos dados, de modo a saber quantas pessoas da nossa base receberam o auxílio emergencial de acordo com o trabalho que ocupam.
auxilio_emprego <- auxilio_emprego %>%
group_by(tipo_emprego) %>%
summarise(
count_total = n(),
recebeu = sum(D0051 == 1),
n_recebeu = sum(D0051 == 2)) %>%
mutate("Auxilio Emergencial (%)" = (recebeu / count_total)*100)
O gráfico a seguir ilustra.
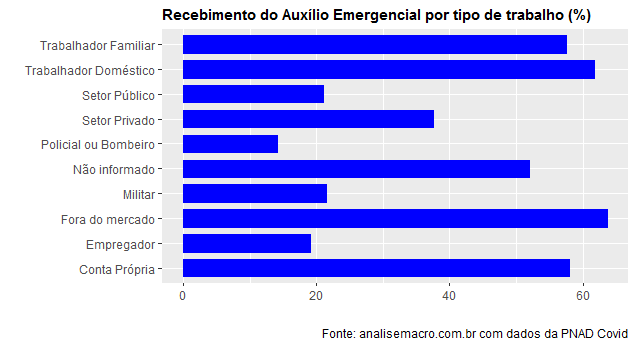
O gráfico resume a pesquisa que fizemos nos microdados da PNAD Covid. 58% dos que se identificaram como "Conta Própria" receberam o auxílio emergencial, enquanto 21,4% que se identificaram como "Militar" tiveram acesso ao benefício. Dos que colocaram "Não informado", o maior contingente, 52% tiveram acesso ao auxílio.
Um pdf e um script com todo o código desse exercício está disponível para os membros do Clube AM.
Caso você tenha interesse em microdados, conheça nosso Curso de Microeconometria usando o R.
____________


