Nos últimos anos, o R se tornou bastante popular no Brasil. Com uma sintaxe simples, download fácil e gratuito, uma comunidade pujante e crescente, uma IDE bastante poderosa e inúmeros pacotes disponíveis para lidar com análise de dados, o R tem conquistado cada vez mais adeptos no país.
Uma das coisas que o R faz bem, diga-se, é auxiliar no trabalho de visualização de dados. Algo que exploraremos bastante no nosso novíssimo curso de Introdução ao R para Análise de Dados. Com o pacote ggplot2, um dos mais poderosos da linguagem para isso, é possível construir belos gráficos. Para ilustrar, vamos considerar aqui um tema que está em bastante evidência no Brasil: a reforma do sistema previdenciário.
Para introduzir a questão, podemos nos perguntar se o Brasil gasta muito com previdência em relação à sua população idosa. Para isso, precisamos comparar o Brasil com outros países, não é mesmo?
A ideia aqui, então, é construir um gráfico de correlação entre a variável gasto com previdência e a variável população idosa para países selecionados.
Para iniciar a produção do nosso gráfico, precisamos de dados. Para esse exemplo, eu vou utilizar os dados compilados pela revista The Economist em diversas fontes, como OCDE, Banco Mundial e a nossa Previdência Social. Você pode fazer o download dos dados aqui. De posse desses dados, podemos importá-los para o R com o código abaixo.
data = read.csv2('Economist_pensions.csv', header=TRUE, sep=',', dec='.')
Se você observar os dados, verá que o nome das colunas não é lá muito intuitivo, bem como existem três linhas no final do arquivo que não nos interessam. Podemos tratar esses problemas com o código abaixo.
data = data[-c(36:38),]
colnames(data) = c('country', 'population', 'pension')
Maravilha. Agora, o nosso arquivo tem três colunas, sendo as duas últimas relacionadas à primeira, que contém os nossos países selecionados. Podemos então começar a produzir o nosso gráfico com o ggplot2 colocando a variável population no eixo x e a variável pension no eixo y. Como estamos interessados em um gráfico de correlação, então o geom que utilizaremos será o geom_point. O código abaixo implementa.
library(ggplot2) ggplot(data, aes(x=population, y=pension))+ geom_point()
E o resultado...
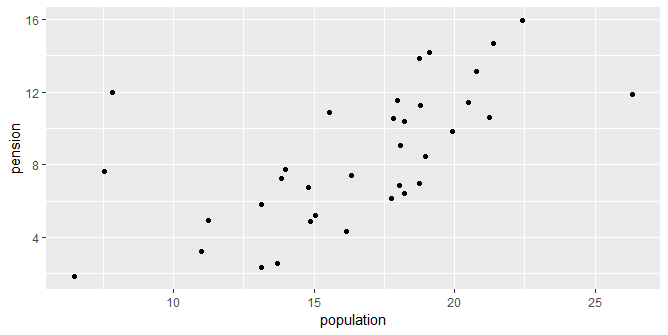
Conseguimos construir o nosso gráfico de correlação. Mas ele não está lá muito agradável aos olhos, não é mesmo? A primeira pergunta que o leitor deverá se fazer é que dados são esses, esses pontos representam o quê, etc. Em outras palavras, o gráfico não traz muita informação para o leitor. De forma a melhorar o nosso gráfico, podemos adicionar o nome dos países nos pontos com o outro geom, o geom_text. O código abaixo implementa.
ggplot(data, aes(x=population, y=pension))+ geom_point()+ geom_text(aes(label=country))
E o resultado...
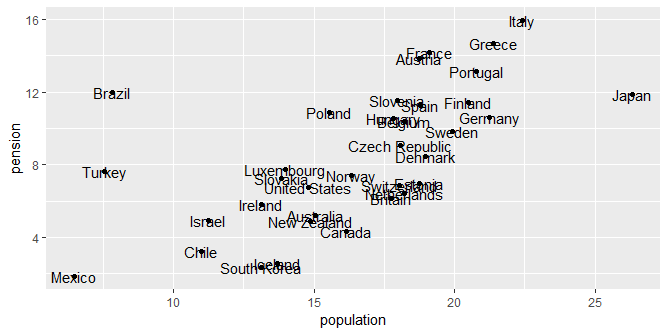
Bom, agora aparecem os nomes dos países. Então, o leitor saberá que o pontos do gráfico se referem às variáveis pension e population para países selecionados. Mas, novamente, o gráfico não é bom porque os nomes ficam uns colados nos outros. Podemos melhorar isso, mudando a função geom_text pela função geom_text_repel do pacote ggrepel, uma espécie de extensão do ggplot2. O código abaixo implementa.
library(ggrepel) ggplot(data, aes(x=population, y=pension))+ geom_point()+ geom_text_repel(aes(label=country))
E o resultado...
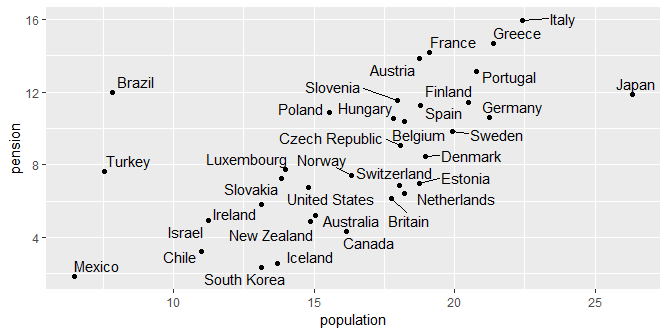
Bem melhor, não é mesmo? Bom, nós chegamos agora a um gráfico razoável. Ele traz os pontos associados às duas variáveis pension e population. Para terminar o nosso trabalho, nós podemos polir o nosso gráfico, tornando-o mais informativo para o leitor final. Fazemos isso, adicionando um tema mais interessante, como o tema da própria revista The Economist. Além disso, como estamos interessados em comparar o Brasil com outros países, podemos destacá-lo no gráfico. Também podemos adicionar uma reta de regressão no gráfico, uma vez que parece existir uma correlação positiva entre as nossas variáveis population e pension. O código abaixo implementa essas modificações.
library(ggthemes)
ggplot(data, aes(x=population, y=pension))+
geom_point(size=6, colour=ifelse(data$pension>=11.8, '#014d64',
'#76c0c1'),
alpha=ifelse(data$pension>=11.8&data$population<8, 1,.6))+
geom_text_repel(aes(label=country),
colour='black',
alpha=c(.4,1,rep(.4,5)),
box.padding = .2,
point.padding = .3,
data=subset(data, pension>=11.8))+
theme_economist()+
xlab('População acima de 65 anos (% do Total)')+
ylab('Gastos com Previdência Social (% PIB)')+
labs(title='Brasil: uma aberração no gasto previdenciário',
caption='Fonte: OCDE, Banco Mundial e Previdência Social')+
theme(plot.title = element_text(size=15))+
geom_smooth(method='lm', colour='black', linetype='dashed', se=FALSE)
E o resultado...
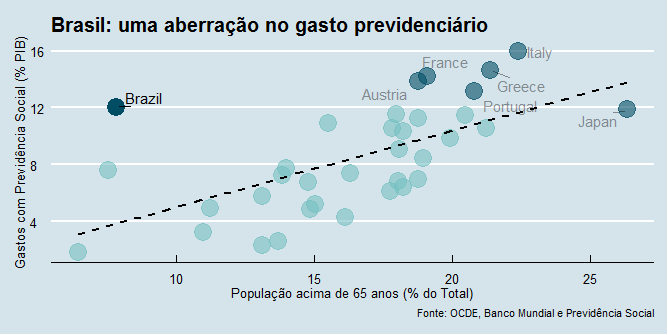
Bem melhor, não é mesmo? Observe que destacamos o Brasil da nossa amostra. Pelo nosso gráfico, podemos ver que o Brasil apesar de ter uma população idosa ainda baixa, se comparada com os demais países, gasta bastante com previdência. Isso torna o país um outlier, na linguagem dos estatísticos. Isto é, um país afastado dos demais países. Países que gastam tanto ou mais do que o Brasil - os pontos mais escuros do gráfico - têm populações idosas bem maiores. O Japão, por seu turno, tem um gasto similar ao Brasil para uma população idosa três vezes maior!
Gostou? Então dê uma olhada no nosso novíssimo Curso de Introdução ao R para Análise de Dados, onde ensinaremos além da visualização de dados com o pacote ggplot2, também a parte de coleta, tratamento, modelagem e comunicação de resultados. As inscrições para o curso começam no dia 6 de maio, com um 1º lote com 30% de desconto!

