Neste post mostraremos como construir modelos de regressão linear de maneira aplicada. Se você já se perguntou em como replicar no R aqueles modelos introdutórios, comuns em disciplinas de estatística e econometria, este post é pra você!
Dessa forma, usaremos a econometria - que é um conjunto de métodos estatísticos utilizados para estimar relações econômicas, testar teorias e avaliar políticas públicas ou de negócios - para explorar um problema aplicado ao mercado de trabalho. Nada melhor do que entender como utilizar algo com um exemplo prático, certo?
Portanto, assumimos que você já possui algum conhecimento teórico sobre modelos de regressão linear, pois daremos ênfase no aspecto prático de como implementar este tipo de modelo usando o R. Você pode conferir o curso de Introdução à Econometria (em R e Python) para explorar mais a fundo os pormenores dos modelos, assim como tópicos mais avançados que fogem do escopo deste post. É uma ótima oportunidade se você acha o assunto "assustador", pois o curso traz exemplos intuitivos e práticos do dia a dia.
Ademais, nossa referência base sobre o assunto é o livro-texto do Wooldridge (2020), que é muito utilizado em disciplinas de econometria de cursos de graduação.
Pacotes
Para reproduzir os códigos deste exercício, você precisará dos seguintes pacotes de R:
O problema e os dados
Para começar a entender o assunto, e exemplificar a estimação de um modelo linear, vamos recorrer a um conjunto de dados clássico do Wooldridge, que traz informações de uma pesquisa populacional. Mais especificamente, iremos investigar um problema de economia do mercado de trabalho: suponha que você seja contratado para determinar o efeito de um programa de aperfeiçoamento profissional na produtividade de trabalhadores. Sem se aprofundar muito na teoria econômica e especializada da área, podemos dizer que fatores como escolaridade, experiência profissional e treinamentos podem afetar a produtividade do trabalhador e, portanto, seus salários. Com esse simples entendimento em mente, podemos então definir um modelo econômico como:
onde é o salário por hora, são os anos de educação formal, são os anos de experiência no mercado de trabalho e é o tempo despendido em aperfeiçoamento profissional. Outros fatores podem afetar , mas este modelo simples capta a essência do problema em questão.
Essa formulação básica que elaboramos carrega a hipótese de que esses fatores especificados estão, de alguma forma, relacionados com o dos trabalhadores. O que precisamos fazer agora é investigar esse "modelinho" de forma empírica.
Dado que estes fatores e variáveis podem ser observados - e se não fossem teríamos que levar isso em consideração -, o próximo passo é transformarmos esta especificação de modelo econômico para um modelo econométrico, como:
onde as constantes , , ..., são parâmetros do modelo que descrevem as direções (sinal) e as magnitudes (tamanho) da relação entre e as demais variáveis utilizadas para explicar no modelo; e o termo de erro contém fatores como "habilidade inata", qualidade da educação, histórico familiar e outros que podem influenciar o salário de um trabalhador, ou seja, o erro é comumente chamado de "medida do nosso desconhecimento". Se estivermos especialmente interessados no efeito do programa de aperfeiçoamento profissional, então é o parâmetro de interesse.
Para uma análise empírica deste modelo precisamos de dados, portanto, após essa breve introdução vamos partir para a prática! No R, o conjunto de dados para usarmos nesse modelo vem do pacote {wooldridge} e pode ser carregado conforme abaixo:
Exploração dos dados
Os dados são do tipo cross-section e contém variáveis de 526 indivíduos referente ao ano de 1976. Deste conjunto de dados, usaremos apenas as variáveis wage (salário por hora), educ (anos de educação) e exper (anos de experiência). Para facilitar o entendimento, utilizaremos a transformação logarítmica na variável dependente (wage), de forma a obter uma interpretação percentual dos parâmetros do modelo.
No R, com um simples comando também é possível obter uma tabela de estatísticas descritivas das variáveis:
Com o pacote ggplot2 podemos facilmente visualizar, em um gráfico de dispersão, a relação entre as variáveis do modelo:
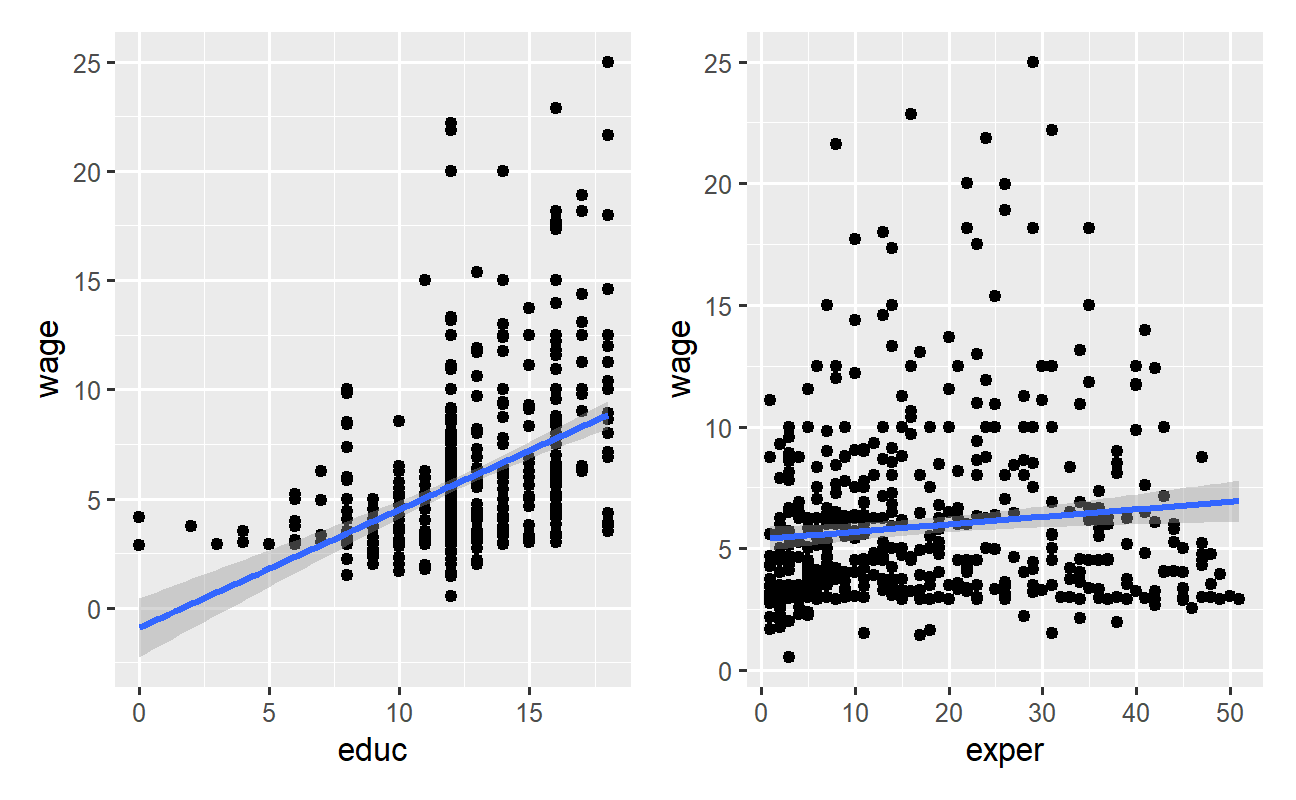
Estimar o modelo
Conforme dito, iremos estimar o modelo econométrico acima mas com algumas modificações: sem o fator e com transformação logarítmica na variável . Com estes ajustes, comuns em exercícios empíricos, chegamos a uma especificação como esta:
Ou seja, queremos saber a relação entre a escolaridade e experiência profissional dos trabalhares sobre os seus salários (em log). Dessa forma, devemos agora estimar os coeficientes que medem esses efeitos.
No R, estimamos este modelo de regressão com a função lm() especificando os termos por uma fórmula e o objeto com os dados:
Resultados do modelo
Para obter os resultados do modelo estimado use a função summary(), que é uma função genérica para obter resultados de diversas famílias de modelos:
A interpretação dos resultados deste modelo deve ser feita ceteris paribus e os parâmetros, neste caso, possuem uma intepretação percentual. Por exemplo, o coeficiente educ (escolaridade) com valor 0,097 significa que, mantendo exper (experiencia) constante, um ano adicional de escolaridade aumenta wage (salario) em 9,7%. É isso que os economistas querem dizer quando se referem ao “retorno a mais por um ano de educação”.
Pode ser mais fácil utilizar essa saída de resultados, especialmente para usuários do {tidyverse}, se a mesma for transformada em tabela. Para organizar dessa maneira o pacote {broom} possui excelentes funções:
Diagnóstico do modelo
Além disso, no R existem diversos pacotes focados em análise estatística. Por exemplo, com o pacote {performance} podemos facilmente investigar visualmente as hipóteses do modelo com um simples comando:

Reportando resultados
Para reportar estes resultados, seja em um artigo, em uma apresentação, etc., também existem diversas facilidades no R. Por exemplo, você pode construir a representação da equação, já em LaTeX, com base no objeto que contém o modelo estimado:
E essa expressão do LaTeX pode ser renderizada, com o R Markdown por exemplo, para:
Já com o pacote {report} é possível criar um texto (em inglês) com alguns parágrafos que já interpretam os resultados do modelo de forma automatizada:
Gerando:
We fitted a linear model (estimated using OLS) to predict wage with educ and exper (formula: log(wage) ~ educ + exper). The model explains a statistically significant and moderate proportion of variance (R2 = 0.25, F(2, 523) = 86.86, p < .001, adj. R2 = 0.25). The model's intercept, corresponding to educ = 0 and exper = 0, is at 0.22 (95% CI [3.52e-03, 0.43], t(523) = 2.00, p = 0.046). Within this model:
- The effect of educ is statistically significant and positive (beta = 0.10, 95% CI [0.08, 0.11], t(523) = 12.85, p < .001; Std. beta = 0.17, 95% CI [0.15, 0.20])
- The effect of exper is statistically significant and positive (beta = 0.01, 95% CI [7.29e-03, 0.01], t(523) = 6.65, p < .001; Std. beta = 0.09, 95% CI [0.06, 0.12])Standardized parameters were obtained by fitting the model on a standardized version of the dataset. 95% Confidence Intervals (CIs) and p-values were computed using the Wald approximation.
Para criar um tabela de resultados, usualmente presente em papers, use a variante *_table():
Por fim, gráficos de parâmetros do modelo também podem ser gerados facilmente:
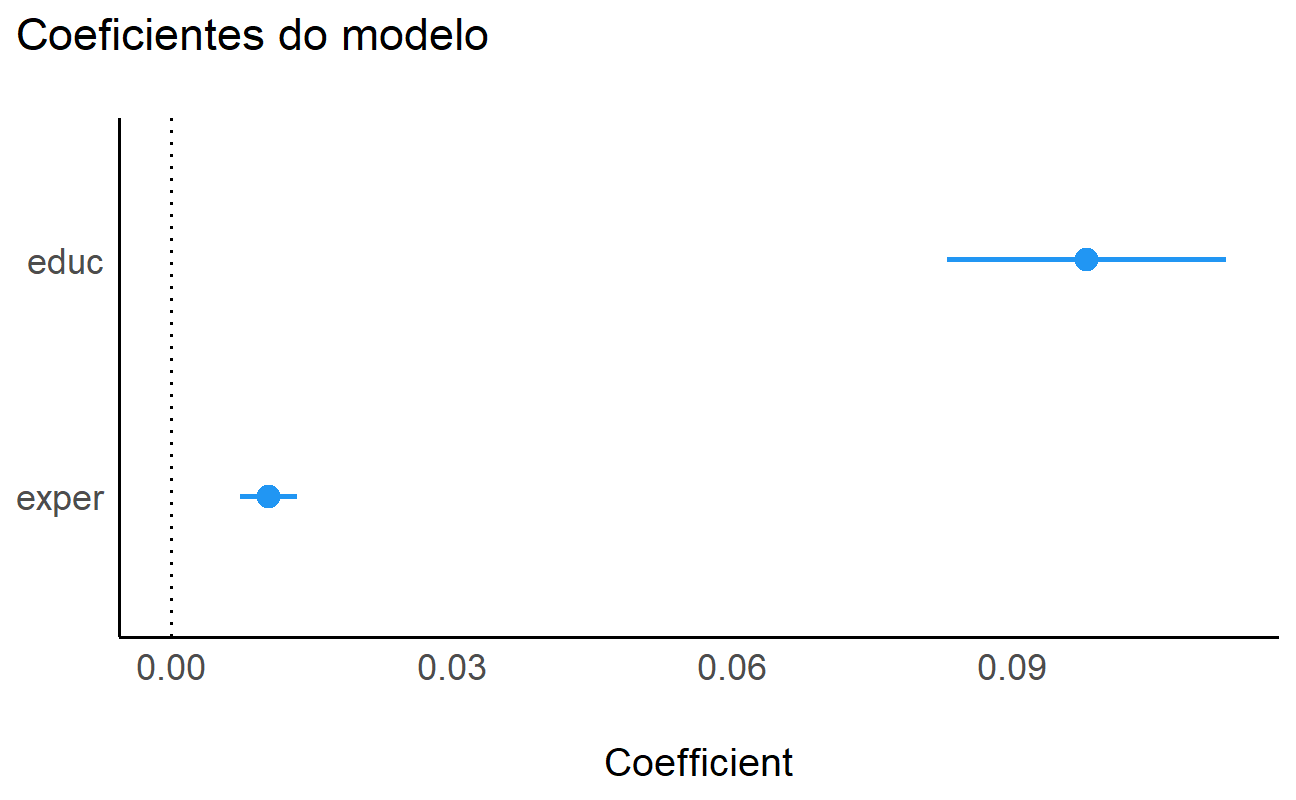
Saiba mais
Para saber mais e se aprofundar no assunto, confira o curso de Introdução à Econometria (em R e Python). Além disso, existem alguns materiais gratuitos sobre modelos disponíveis no blog:

