A mineração de dados (text mining) é um tópico interessante que vem sendo bastante explorado no mundo da ciência de dados. Na Análise Macro já exploramos, por exemplo, a mineração de textos de política monetária, a sumarização de textos, classificação de spam, dentre outros. Neste artigo, exploraremos o uso da mineração de textos para o problema de detecção de plágio entre dois ou mais textos, usando como exemplo um evento repercutido nos anos recentes envolvendo o ex-Ministro da Educação, Carlos Decotelli.
Para contextualizar, e para quem não teve conhecimento do evento em questão, em junho de 2020 houveram apontamentos de que a dissertação de mestrado do então Ministro da Educação, Carlos Decotelli, continha indícios de plágio. Muitas notícias foram vinculadas na época e após o “escândalo” o Ministro entregou uma carta de demissão.
Dados os atores envolvidos e repercussão deste evento, é natural aos cientistas de dados se perguntarem se o plágio pode ser verificado de forma mais empírica. Neste artigo faremos um exercício aplicado de Python para tentar responder essa questão.
O Python serve muito bem ao propósito deste exercício, pois fornece um conjunto de funções para medir a similaridade entre documentos de texto e detectar passagens que foram reutilizadas. Para realizar essa mensuração existem algumas possibilidades, entre elas o Índice de Jaccard - também conhecido como coeficiente de similaridade de Jaccard - que oferece uma estatística para medir a similaridade entre conjuntos amostrais, expresso conforme abaixo:
![\[J(A, B) = \frac{ | A \cap B | }{ | A \cup B | }\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-447111aa61edbaaa9aea75681378b73b_l3.png "Rendered by QuickLaTeX.com")
O Índice de Jaccard é muito simples quando queremos identificar similaridade entre textos, sendo os coeficientes expressos como números entre 0 e 1. Dessa forma, quanto maior o número, mais semelhantes são os textos (conjuntos amostrais).
Dados
Os dados utilizados são os documentos que queremos comparar a similaridade. O principal documento é a dissertação de mestrado de Carlos Decotelli, e os demais são documentos indicados por Thomas Conti de onde os trechos teriam sido copiados. Nos links à seguir você pode baixar os originais de cada documento:
- Dissertação Carlos Decotelli: https://bibliotecadigital.fgv.br/dspace/handle/10438/3726
- Relatório CVM - The Internet Archive: http://web.archive.org/web/20200629224030/https://ri.banrisul.com.br/banrisul/web/arquivos/Banrisul_DFP2007b_port.pdf
- “A Abordagem Institucional na Administração” de Alexandre Rosa e Cláudia Coser: https://twiki.ufba.br/twiki/bin/viewfile/PROGESP/ItemAcervo241?rev=&filename=Abordagem_institucional_na_administracao.pdf
- “Mudança e estratégia nas organizações” de Clóvis L. Machado-da-Silva et al.: http://anpad.org.br/admin/pdf/enanpad1998-orgest-26.pdf
Para analisar a similaridade destes documentos precisamos transformá-los para o formato de texto (extensão .txt). Existem formas de fazer isso por meio de pacotes no Python, no entanto, para simplificar eu usei ferramentas online que fazem esse serviço, tomando o cuidado de remover as páginas pré ou pós textuais (capa, sumário, referências, etc.) antes da conversão, já que o objetivo é comparar os textos do corpo dos documentos propriamente ditos.
Ferramenta online para converter de PDF para TXT: https://pdftotext.com/pt/
Após esse tratamento/conversão teremos 4 arquivos de texto para realizar a análise. Disponibilizei os arquivos neste link para quem se interessar em reproduzir. Na sequência importamos os arquivos e aplicamos uma simples tokenização:
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
| tokens | |
|---|---|
| clovis-páginas-1-13.txt | [mudança, e, estratégia, nas, organizações, pe... |
| cvm-páginas-23-62.txt | [serviço, público, federal, uso, empresa, p, s... |
| decotelli-páginas-9-83.txt | [–, introdução, a, moeda, é, sem, dúvida, a, p... |
| rosa-páginas-1-13.txt | [a, abordagem, institucional, na, administraçã... |
Índice de Jaccard
Com os dados preparados, podemos obter a estatística do Índice de Jaccard para medir a similaridade entre os textos, usando a função indice_jaccard() que definimos, comparando um texto A com um texto B. Queremos fazer isso já para os 4, portanto usamos a função auxiliar apply() que aplica o cálculo da estatística de cada documento comparando ao texto do Decotelli:
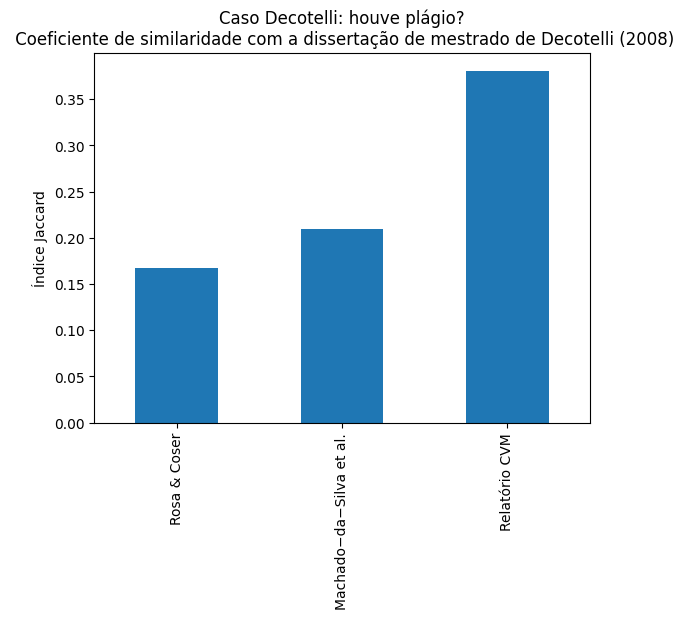
clovis-páginas-1-13.txt 0.209028
cvm-páginas-23-62.txt 0.380921
decotelli-páginas-9-83.txt 1.000000
rosa-páginas-1-13.txt 0.167092
Name: Similaridade Jaccard com texto de Decotelli, dtype: float64O resultado de destaque mostra que o texto da dissertação de mestrado de Carlos Decotelli (decotelli-páginas-9-83.txt) comparado com o texto do relatório da CVM (cvm-páginas-23-62.txt) obteve um coeficiente de 0.38 (o valor máximo vai até 1), bem superior aos demais. Esse resultado dialoga com o que foi indicado por Thomas Conti em junho de 2020.
Vale frisar que existem outros métodos de comparação e funcionalidades que os pacotes de mineração de textos oferecem.
Por fim, vamos criar uma visualização dos resultados:
Referências
Recomenda-se consultar a documentação dos pacotes utilizados para entendimento aprofundado sobre as funcionalidades.
- Jure Leskovec, Anand Rajaraman, and Jeff Ullman, Mining of Massive Datasets (Cambridge University Press, 2011).
Conclusão
Como usar linguagem de programação e técnicas de mineração de textos para detectar plágio? Neste artigo exploramos as técnicas de análise de similaridade para dados textuais.
Tenha acesso ao código e suporte desse e de mais 500 exercícios no Clube AM!
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte do Clube AM, clicando aqui.

