O que é SQL?
SQL é o acrônimo para Structured Query Language - Linguagem de Consulta Estruturada - e é utilizada para acessar, manipular e consultar dados de objetos, ou seja, uma linguagem criada para se comunicar com bases de dados.
Diferente de outras linguagens de propósito geral, como C ou Python, o SQL não pode construir Web Apps e performar diferentes tarefas, entretanto, é extremamente útil para trabalhar com dados em bancos de dados e realizar aplicações de trabalhos para a análise de dados.
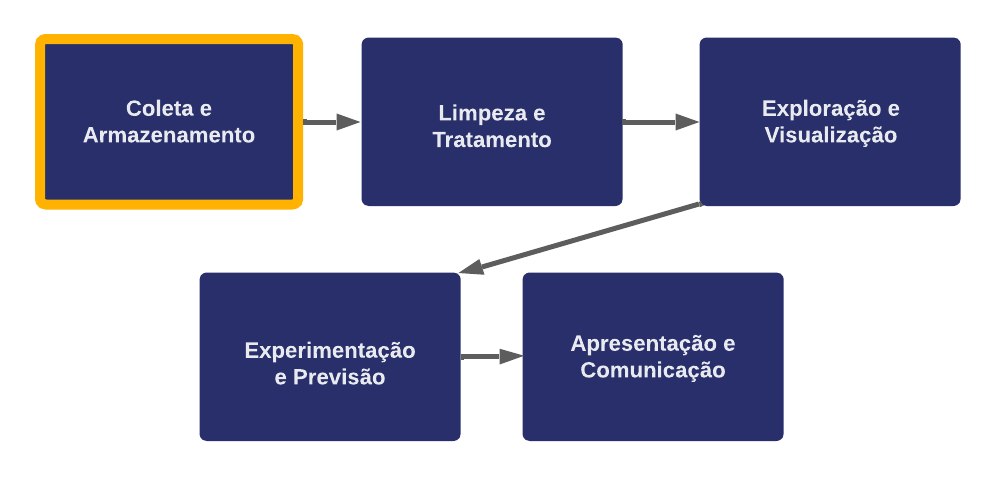
Obviamente, nas técnicas e etapas do processo de análise de dados, o SQL se concentra na primeira, de coleta e armazenamento.
Para utilizar o SQL, é necessário que se tenha um banco de dados criado, se não houver, é necessário a criação de um. A questão, é que mesmo com esse ponto, a linguagem pode ser benéfica para uma empresa ou organização.
Benefícios do SQL
O SQL pode ser útil para uma empresa pelos seguintes motivos:
- A maioria dos dados disponíveis podem estar em base de dados, e mesmo que não esteja, carregar dados em um pode ser extremamente benéfico por possuir vantagens de armazenamento e computação, especialmente se comparar com planilhas eletrônicas.
- Nos últimos anos, a tecnologia melhorou significativamente, e bancos de dados seguiram o mesmo caminho, portanto, tirando vantagem do acesso e manipulação de grandes volumes de dados de forma extremamente rápida.
- SQL é o método padrão para interagir e recuperar dados de bases de dados. Portanto, softwares de planilhas, de visualização de BI, linguagens como R e Python se conectam com base de dados com SQL.
- SQL é relativamente fácil de apresentar, com pouca quantidade de sintaxe necessária de se entender. É possível aprender os comandos e estruturas básicas e então praticar com o tempo em uma variedade de conjunto de dados.
SQL - R - Python
SQL é uma linguagem popular para a análise de dados, porém, R e Python são altamente populares e também utilizadas para o mesmo objetivo.
R é uma linguagem criada para estatística e criação de gráficos, enquanto Python é uma linguagem de propósito geral. Ambas são open source, e possuem comunidades desenvolvendo pacotes ou extensões que possibilitam melhorar as análises.
A diferença principal está onde o código “roda”. SQL sempre “roda” no servidor de um banco de dados, ganhando vantagem de todos os recursos computacionais. Diferente do R e do Python, no qual "rodam" localmente na máquina do usuário.
Outra diferença está em como os dados estão armazenados e organizados. Bancos de dados relacionais sempre organizam dados em linhas e colunas em tabelas, então o SQL segue essa estrutura em toda consulta. R e Python possuem diversas formas de armazenar dados, aumentando a flexibilidade, porém, a um custo de aumento de aprendizado.
Considerações
Apesar dessas diferenças, há pontos a se considerar ao utilizar SQL, R e Python, como por exemplo, se os dados já estão disponíveis em uma base de dados ou se é necessário funções estatísticas sofisticadas para a análise.
De certa forma, a utilização do SQL em linguagens como R e Python podem trazer ganhos enormes para as organizações.
Com os dados em empresas e também no mundo crescendo exponencialmente, é necessário que se tenha profissionais capazes de os utilizarem. Esse é o ponto onde SQL entra como um meio de facilitar o acesso de dados de forma significativa e fornecer insights úteis para os negócios.
____________________________________________________
Quer aprender mais?
Veja nosso curso de SQL para Economia e Finanças, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.

