Reflexo da era da informação, atualmente não se faz mais política monetária sem uma boa dose de comunicados, atas, entrevistas, conferências, etc. Os chamados central bankers atuam, sobretudo, como comunicadores e qualquer pequena nuance em sua comunicação (futuros passos da política monetária) pode ser um sinal para alvoroço nos "mercados".
Nesse sentido, uma área da literatura econômica que vem prosperando busca investigar o chamado canal informacional (de transmissão) da política monetária, propiciando uma intersecção entre métodos econométricos e de machine learning. Como exemplo, Lucca e Trebbi (2009) exploram a relação entre mudanças nos comunicados (statements) do Federal Open Market Committee (FOMC) com variáveis macroeconômicas, como taxas de juros, mostrando que há poder preditivo no conteúdo informacional dos comunicados. De forma similar, Ferreira (2022) expande um modelo VAR usando fatores textuais extraídos dos comunicados do FOMC, mostrando que a técnica (denominada VAR-teXt) é útil para finalidade de previsão.
Mais informalmente, neste espaço da Análise Macro já exploramos a extração de sentimentos e de tópicos latentes dos comunicados do Banco Central do Brasil (BCB). De forma a avançar mais nessa área, no exercício de hoje exploramos, de forma similar a Ferreira (2022), a utilidade de tópicos latentes extraídos dos comunicados do FOMC, por um modelo LDA, na previsão da inflação norte-americana, medida pelo CPI. O objetivo é comparar um modelo econométrico simples, tal como um AR-GAP de Faust e Wright (2013), em especificações com e sem os fatores textuais.
Para aprender mais confira o curso de Modelagem e Previsão usando Python ou comece do zero em análise de dados com a formação Do Zero à Análise de Dados com Python.
Uma visão geral
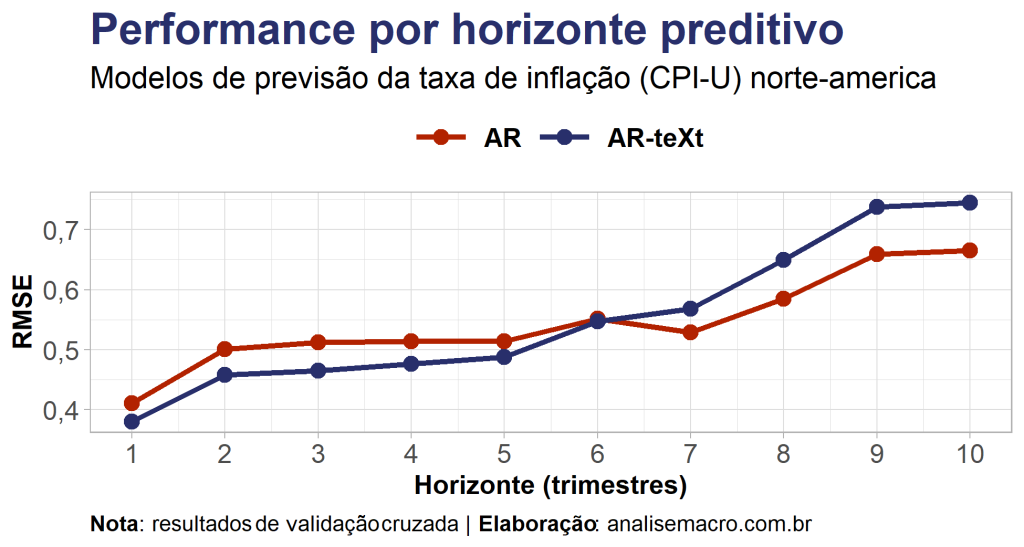
O exercício de previsão em questão consiste em extrair os dados de interesse das devidas fontes (FRED-MD e FOMC/FED), realizar o pré processamento e extração de fatores textuais e, por fim, treinar duas especificações de modelos simples para o CPI: AR e AR-teXt (i.e., um modelo autoregressivo com fatores textuais como variáveis exógenas). O diagrama abaixo ilustra os principais procedimentos:
Recomenda-se a leitura prévia dos textos a seguir, assim como referências correspondentes, para uma boa compreensão do exercício proposto:
- Análise das Atas do COPOM com text mining
- Topic Modeling: sobre o que o COPOM está discutindo? Uma aplicação do modelo LDA
Dados e especificação
Os modelos são estimados em frequência trimestral, onde a variável de interesse, o CPI, é medido como a variação percentual em relação ao trimestre imediatamente anterior.
As fontes de dados são:
- CPI (variável endógena) é proveniente do banco de dados FRED-MD (código CPIAUCSL), veja McCracken e NG (2016);
- Tópicos textuais (variáveis exógenas) são extraídos através do modelo LDA, tendo como origem os statements do FOMC/FED.
As especificações dos modelos são:
Partindo da construção de uma medida de tendência, τt, do CPI, πt, definimos o "gap" da inflação como gt = πt − τt e consideramos essa medida nos modelos abaixo, tal como em Faust e Wright (2013).
- AR(p): gt = α1 gt-1 + … + αpgt-p + ϵt
- AR-teXt(p,s): gt = α1 gt-1 + … + αpgt-p + βsxt-s + ϵt
onde αi e βi são coeficientes dos modelos, xt são as variáveis exógenas e ϵt é o erro do modelo.
Em nosso exercício geramos previsão 10 trimestres à frente (pseudo fora da amostra) e, então, adicionamos de volta a tendência, τt, para obter a previsão "final". A amostra utilizada é de 1998 até a observação mais recente do ano atual, 2022.
Visualização de dados
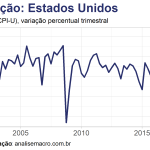
Abaixo plotamos um gráfico de linha da série de interesse, o CPI dos Estados Unidos em variação percentual trimestral:
E na imagem a seguir trazemos a estrutura textual de apenas um dos statements do FOMC/FED que foram extraídos (web scraping) de forma online para construção dos fatores textuais.
Vale pontuar que a estrutura textual dos comunicados pode variar consideravelmente no tempo.

Resultados
Os procedimentos brevemente descritos acima foram implementados através da linguagem R usando, para estimação, o pacote {fable} (veja um tutorial aqui)). Os modelos foram treinados usando validação cruzada, considerando uma janela amostral crescente, partindo de 60 observações iniciais e adicionando 1 observação a cada iteração. O cálculo de métricas de acurácia foi realizado por horizonte preditivo (1, 2, ..., 10 trimestres).
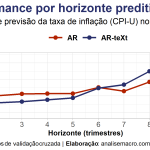
A seguir resumimos os resultados de acurácia em um gráfico que mostra o RMSE por horizonte de previsão dos dois modelos considerados:
Comentários
- Modelo com fatores textuais parece performar melhor no curto prazo em relação ao benchmark (AR);
- Os resultados apresentados estão em linha com o encontrado por Ferreira et al. (2020), que considera uma abordagem vetorial com diferente método de estimação (e aqui não aplicamos testes estatísticos para comparar previsões);
- Pontua-se que a performance do modelo proposto, AR-teXt, pode ser consideravelmente sensível a escolha do número de tópicos definidos, assim como ao tratamento dos dados textuais;
- O modelo de tópicos LDA é intensivo computacionalmente.
Códigos de R para replicação estão disponíveis para membros do Clube AM da Análise Macro.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.
Referências
Faust, J., & Wright, J. H. (2013). Forecasting inflation. In Handbook of economic forecasting (Vol. 2, pp. 2-56). Elsevier.
Ferreira, L. N. (2022). Forecasting with VAR-teXt and DFM-teXt Models: exploring the predictive power of central bank communication. BCB Working Paper Serie No. 559.
Lucca, D. O., & Trebbi, F. (2009). Measuring central bank communication: an automated approach with application to FOMC statements. National Bureau of Economic Research (No. w15367).
McCracken, M. W., & Ng, S. (2016). FRED-MD: A monthly database for macroeconomic research. Journal of Business & Economic Statistics, 34(4), 574-589.

