Quantificar o assunto discutido em um texto é uma questão central na mineração de textos. Dentre as possibilidades, a análise estatística pode ser utilizada para investigar a relevância de determinados termos. Apesar de soar muito difícil, este tipo de análise possui implementação e cálculos simples. Neste artigo mostramos um exemplo com as atas do COPOM usando o Python.
Análise de frequência de termos
Uma medida de quão importante é uma palavra ou token em um texto é a frequência do mesmo, ou seja, o número de vezes em que o mesmo aparece no documento. Em mineração de texto, esse tipo de análise se chama term-frequency (TF) e nos ajuda a revelar os termos mais usados em um documento, possibilitando rankeamento e visualizações de dados.
![\[\text{tf}_{t,d}=\frac{\text{Nº de vezes que o token }\textit{t}\text{ aparece no documento }\textit{d}}{\text{Nº total de tokens no documento }\textit{d}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c25499d60e77a4762887f7f387a7d0f8_l3.png "Rendered by QuickLaTeX.com")
['a',
'atualização',
'da',
'conjuntura',
'econômica',
'e',
'do',
'cenário',
'do',
'copom']Em seguida, calculamos a frequência de cada token, o total de tokens e a estatística TF. Quais são as palavras mais comumente utilizadas pelos diretores do COPOM na ata em questão?
| n | total | tf | doc | |
|---|---|---|---|---|
| de | 227 | 2756 | 0.082366 | 264 |
| a | 98 | 2756 | 0.035559 | 264 |
| e | 90 | 2756 | 0.032656 | 264 |
| o | 84 | 2756 | 0.030479 | 264 |
| da | 72 | 2756 | 0.026125 | 264 |
| ... | ... | ... | ... | ... |
| contribuem | 1 | 2756 | 0.000363 | 264 |
| suavizar | 1 | 2756 | 0.000363 | 264 |
| fomentar | 1 | 2756 | 0.000363 | 264 |
| perseguir | 1 | 2756 | 0.000363 | 264 |
| conselho | 1 | 2756 | 0.000363 | 264 |
827 rows × 4 columns
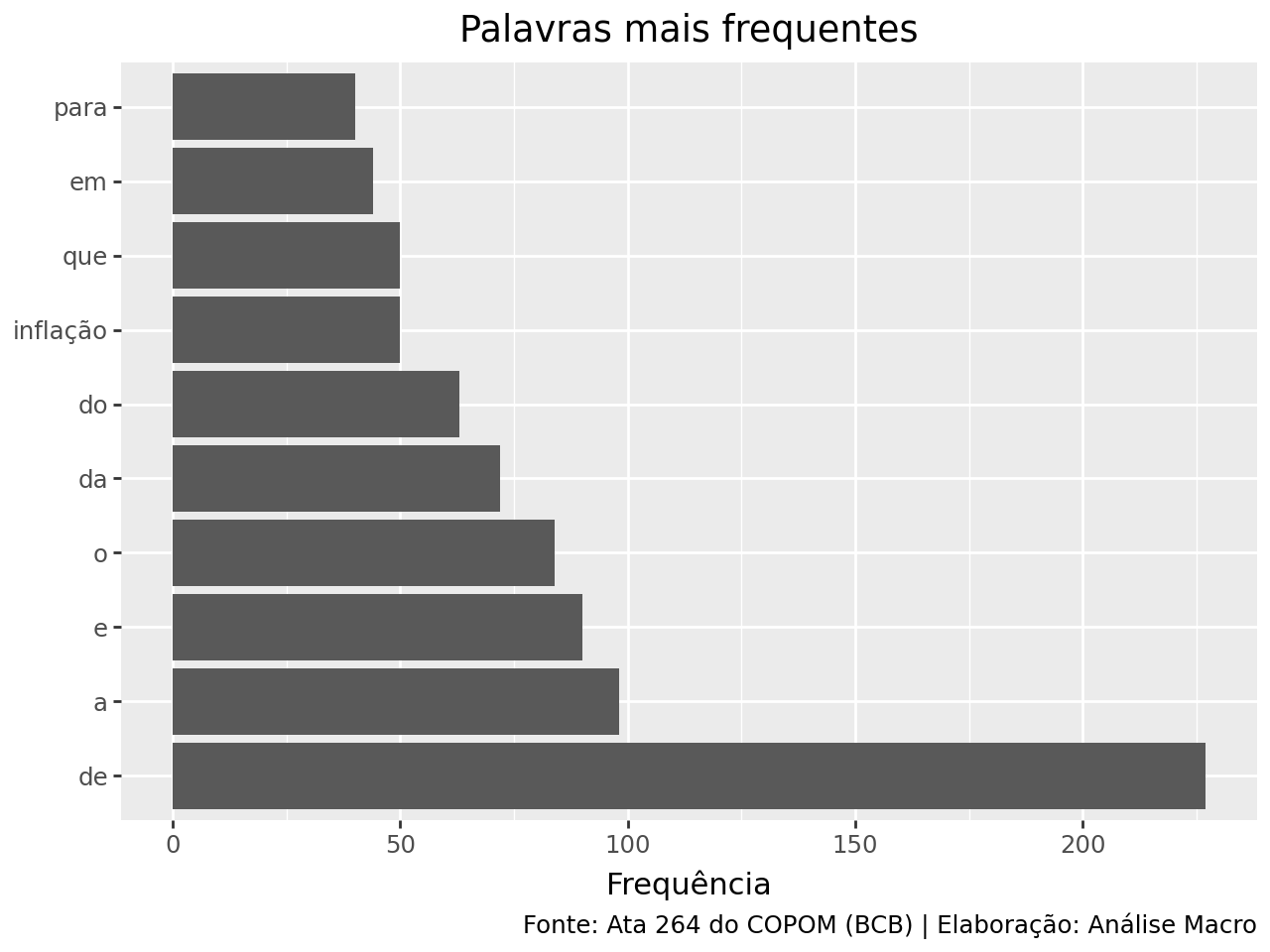
Na tabela acima, o índice das linhas armazena os tokens, a coluna n é o total de vezes que o token aparece no texto e a coluna total é o número total de tokens no mesmo texto. Como é esperado, as chamadas stop words são as mais utilizadas no texto, como “de”, “a”, “e”, “que”, etc.
Podemos visualizar isso facilmente através de um gráfico com as 10 palavras mais frequentes:
Podemos analisar a distribuição da coluna n/total, o número de vezes que uma palavra aparece dividido pelo número total de palavras, ou seja, a definição de frequência dos termos pela estatística TF. O gráfico abaixo mostra esta distribuição:
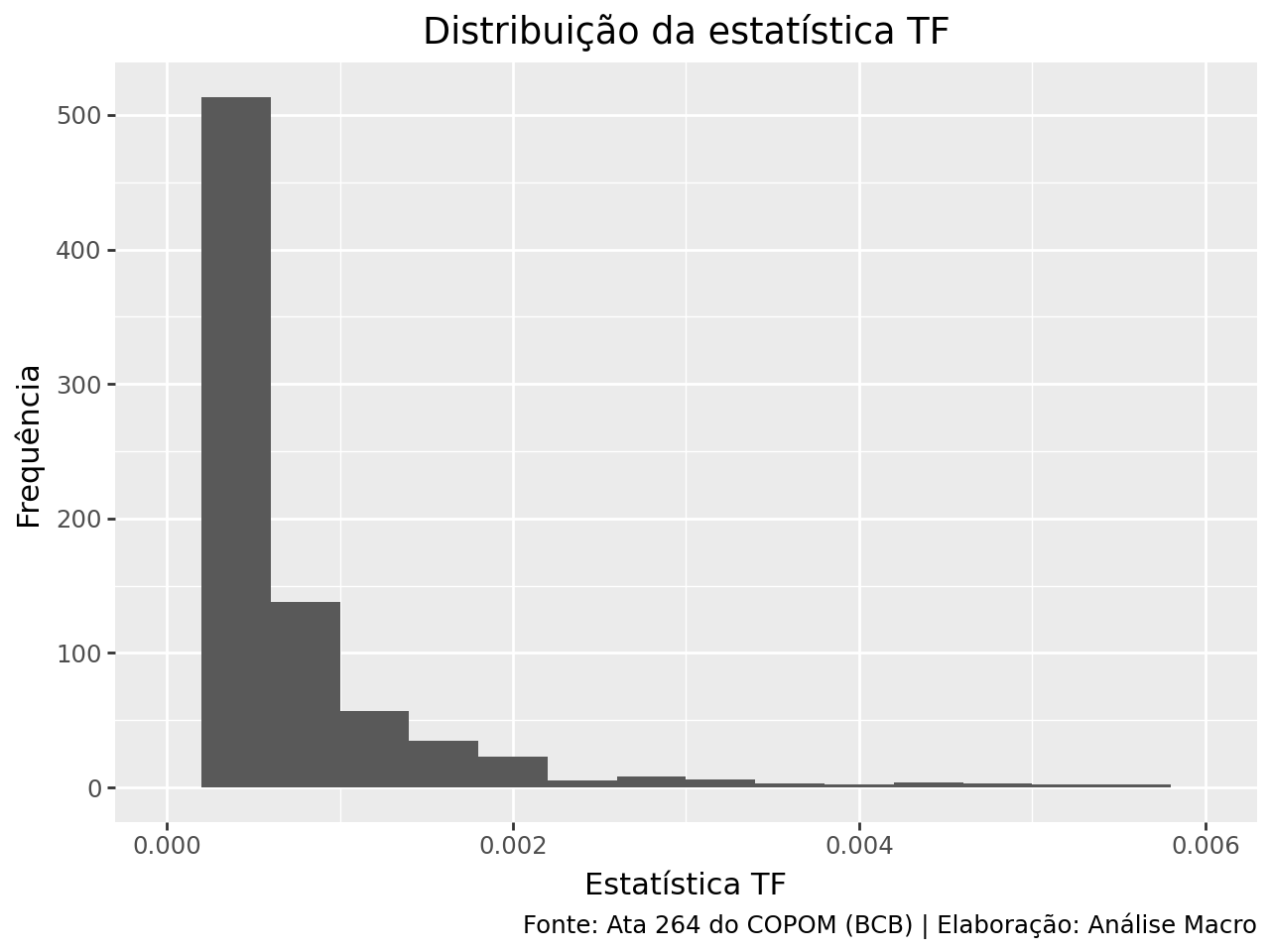
O gráfico possui uma cauda bastante longa para a direita, que é a estatística TF das palavras que aparecem relativamente pouco no texto, enquanto que à esquerda, concentram-se a estatística TF das palavras mais comuns no texto (em geral, stop words).
Lei de Zipf
Esse formato de distribuição visto no gráfico acima é costumeiro na linguagem. É tão comum que a relação entre a frequência que uma palavra é utilizada e sua posição no ranking já foi objeto de estudo por um linguista americano, dando origem ao que se chama de Lei de Zipf.
A lei de Zipf diz que a frequência em que uma palavra aparece em um texto é inversamente proporcional ao seu ranking. O ranking é apenas uma sequência numérica indicando a ordem das palavras, após ordenar os termos pela frequência.
A lei de Zipf costuma ser analisada através de um gráfico com o ranking no eixo X e a estatística TF no eixo Y, em escala logarítmica, o que vai gerar uma relação negativa.
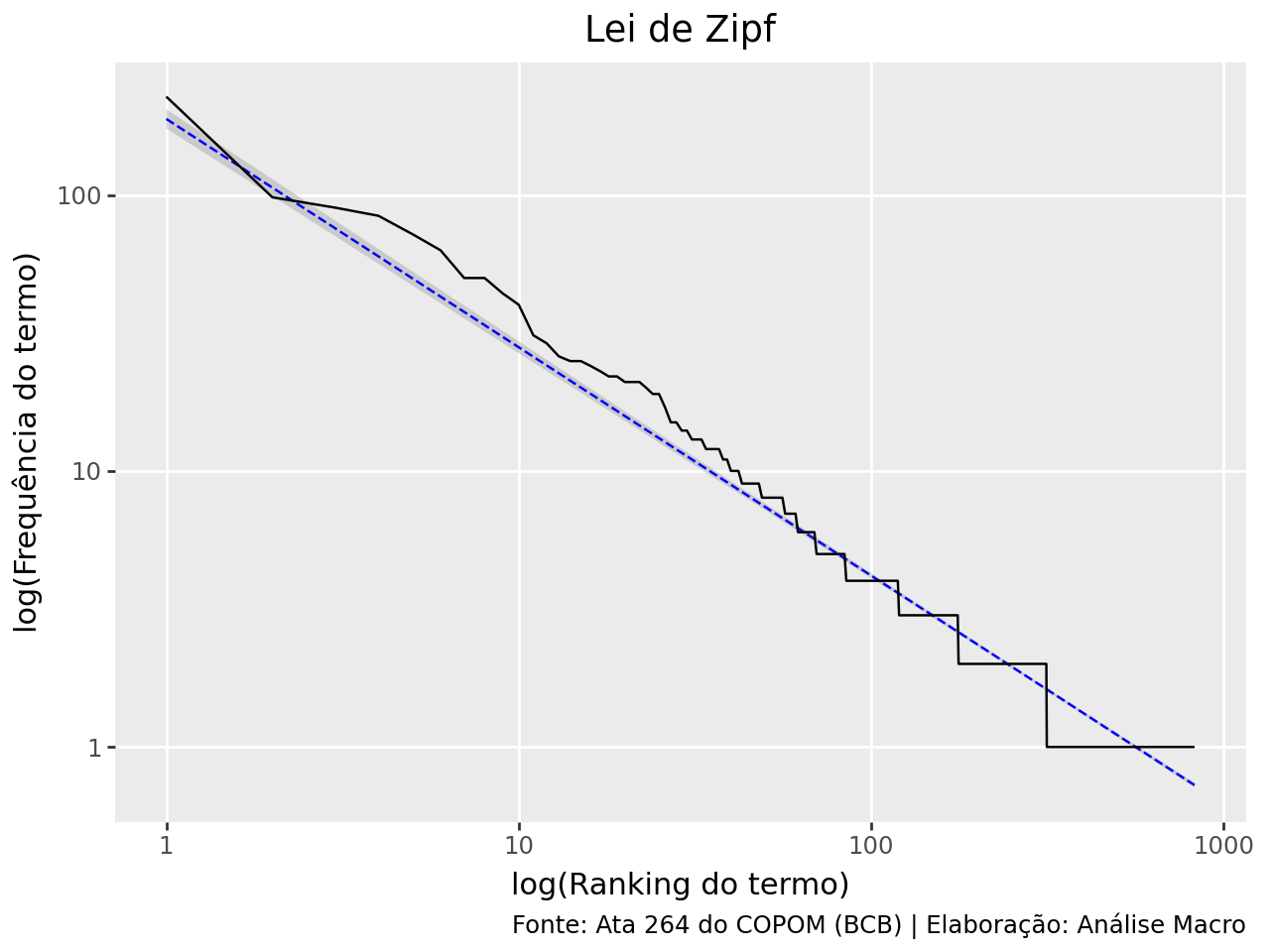
Apesar da relação ser negativa, ela não é constante quando comparada a uma aproximação perfeita (linha azul) da lei. Mesmo assim, os desvios não são exagerados.
Análise do inverso da frequência do documento
Na mineração de textos, a análise do inverso da frequência do documento, inverse document frequency (IDF) no inglês, é uma medida de quão importante uma palavra é para um documento/texto em um conjunto de documentos. Esta estatística diminui o peso de palavras muito frequentes e aumenta o peso de palavras não muito utilizadas.
A estatística IDF pode ser, então, combinada com a estatística TF, multiplicando uma pela outra, para ajustar a frequência de uma palavra pelo quão raramente ela é utilizada.
![\[\text{idf}_{t,c}=\ln \left ( \frac{\text{Nº total de documentos no conjunto }\textit{c}}{\text{Nº de documentos contendo o token }\textit{t}} \right )\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-6752c92edcd9fdf594abe799e1781834_l3.png "Rendered by QuickLaTeX.com")
A ideia desta estatística é encontrar palavras importantes para o conteúdo do texto diminuindo o peso de palavras muito frequentes e aumentando o peso de palavras pouco frequentes. Um conjunto de documentos, nos nossos exemplos, seria um conjunto de atas do COPOM.
Para exemplificar, adicionamos a ata 263 do COPOM e um nova coluna em nossa tabela com o cálculo da estatística IDF:
| token | n | total | tf | doc | idf | |
|---|---|---|---|---|---|---|
| 0 | a | 98 | 2756 | 0.035559 | 264 | 0.0 |
| 1 | a | 92 | 2635 | 0.034915 | 263 | 0.0 |
| 2 | aa | 1 | 2756 | 0.000363 | 264 | 0.0 |
| 3 | aa | 1 | 2635 | 0.000380 | 263 | 0.0 |
| 4 | abertomarcelo | 1 | 2756 | 0.000363 | 264 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... |
| 1685 | – | 9 | 2635 | 0.003416 | 263 | 0.0 |
| 1686 | “ | 1 | 2756 | 0.000363 | 264 | 0.0 |
| 1687 | “ | 1 | 2635 | 0.000380 | 263 | 0.0 |
| 1688 | ” | 1 | 2756 | 0.000363 | 264 | 0.0 |
| 1689 | ” | 1 | 2635 | 0.000380 | 263 | 0.0 |
1690 rows × 6 columns
Note que a estatística IDF é igual a zero para palavras muito frequentes, ou seja, nesse caso o logarítmo natural de 2/2 é zero.
Por sua vez, podemos multiplicar as estatísticas TF e IDF para obter a estatística TF-IDF, o que nos diz a frequência de uma palavra ajustada por quão raramente ela aparece:
| token | n | total | tf | doc | idf | tf_idf | |
|---|---|---|---|---|---|---|---|
| 14 | acompanhamento | 5 | 2756 | 0.001814 | 264 | 0.693147 | 0.001258 |
| 429 | debate | 4 | 2635 | 0.001518 | 263 | 0.693147 | 0.001052 |
| 793 | grande | 4 | 2635 | 0.001518 | 263 | 0.693147 | 0.001052 |
| 508 | diferentes | 4 | 2635 | 0.001518 | 263 | 0.693147 | 0.001052 |
| 509 | diligente | 4 | 2756 | 0.001451 | 264 | 0.693147 | 0.001006 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 628 | esmorecimento | 1 | 2635 | 0.000380 | 263 | 0.000000 | 0.000000 |
| 627 | esmorecimento | 1 | 2756 | 0.000363 | 264 | 0.000000 | 0.000000 |
| 626 | esforço | 1 | 2635 | 0.000380 | 263 | 0.000000 | 0.000000 |
| 625 | esforço | 1 | 2756 | 0.000363 | 264 | 0.000000 | 0.000000 |
| 1689 | ” | 1 | 2635 | 0.000380 | 263 | 0.000000 | 0.000000 |
1690 rows × 7 columns
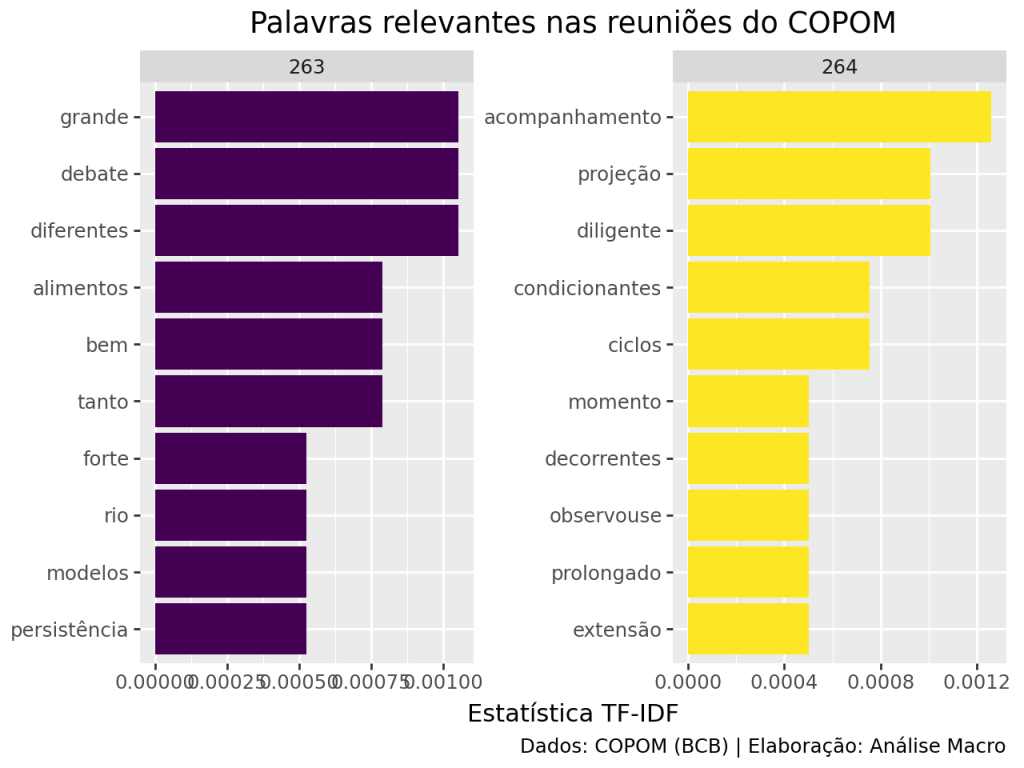
A estatística TF-IDF será muito próxima de zero para palavras que aparecem em vários documentos em um conjunto de documentos e será maior para palavras que aparecem poucas vezes nos documentos. Pela tabela podemos verificar propriamente as verdadeiras preocupações dos diretores do COPOM nas reuniões (termos como “alimentos”, “persistência”, “rio [grande do sul]”, etc).
Por fim, vamos gerar uma visualização destas estatísticas TF-IDF de maior valor para ambas as atas:
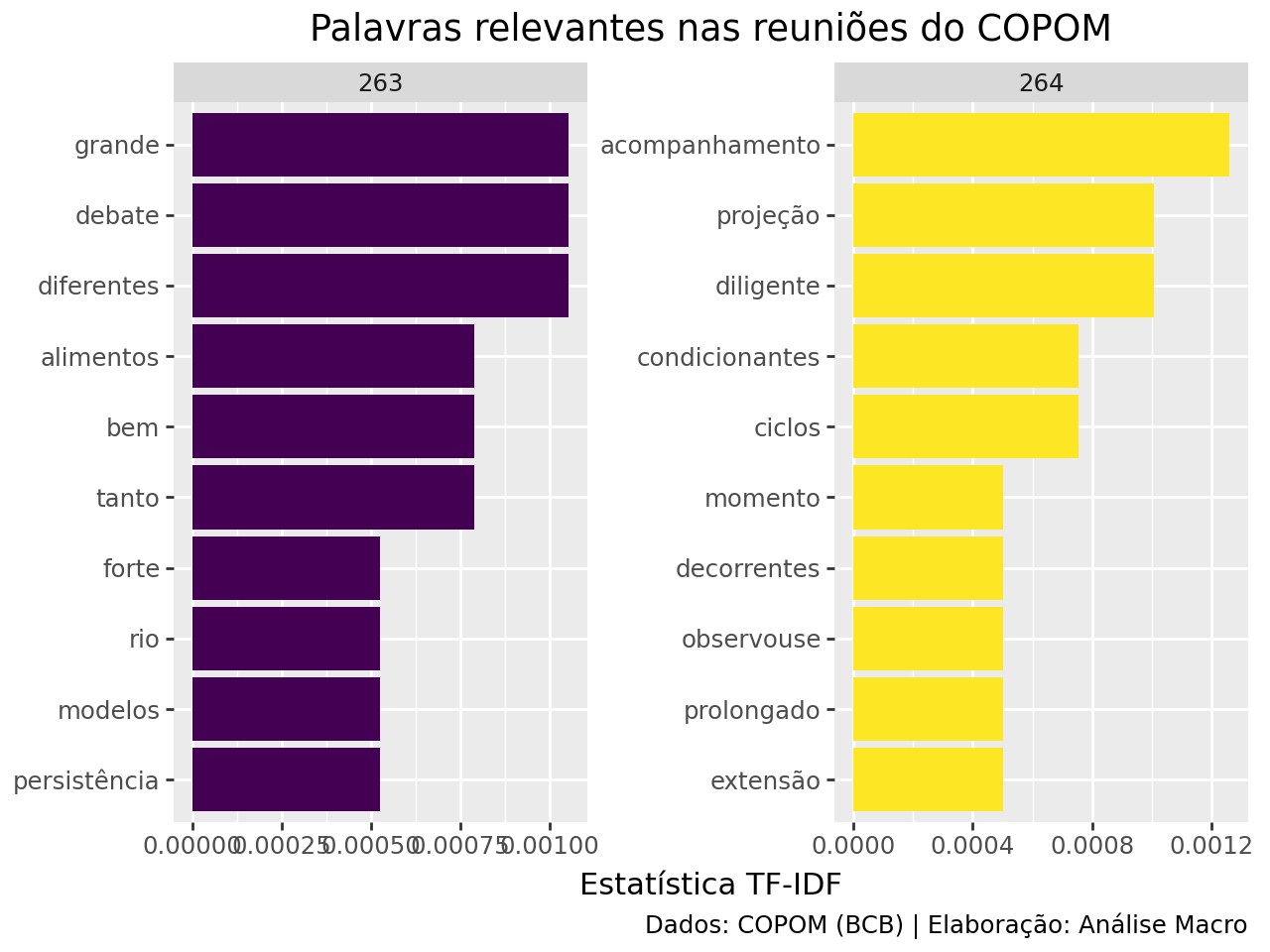
Conclusão
Como quantificar sobre o que se trata um texto? Que tipo de informação podemos obter a partir destes dados? Como identificar a relevância das palavras? Neste artigo exploramos técnicas estatísticas de frequência de tokens para extrair informação de dados textuais.
Quer aprender mais?
Quer o código desse e de mais de 500 exercícios de análise de dados com ideias validadas por nossos especialistas em problemas reais de análise de dados do seu dia a dia? Além de acesso a vídeos, materiais extras e todo o suporte necessário para você reproduzir esses exercícios? Então, fale com a gente no Whatsapp e veja como fazer parte da nossa Comunidade clicando aqui.

