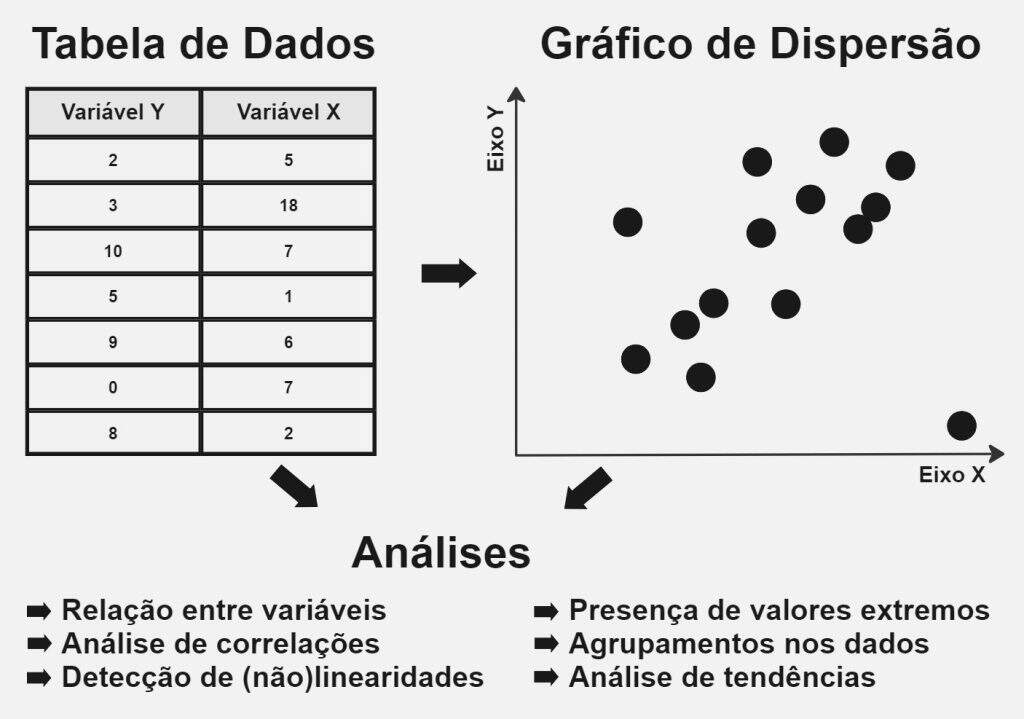
Entender a origem dos dados e suas principais características é fundamental para produzir análises ou previsões úteis na ciência de dados. As estatísticas descritivas ajudam muito nesse sentido e sumarizam informações relevantes sobre as variáveis, mas às vezes isso não é suficiente. Para obter uma visão geral dos dados é importante explorar também os métodos de visualização.
A visualização de dados é a sua exibição visual, através de representações tabulares, gráficas ou por diagramas, como forma de comunicar alguma informação. É um processo que aplica conjuntamente matemática, estatística, artes gráficas e comunicação, portanto é uma das tarefas menos automatizáveis da análise e ciência de dados, sendo dificilmente substituível por máquinas no curto prazo. Nesse sentido, em tempos de Inteligência Artificial, robôs e Big Data, a visualização de dados é uma habilidade importante para se ter no currículo, principalmente se usada em conjunto com técnicas de data storytelling.
Naturalmente, existem diversas formas de visualizar dados através de gráficos, desde as mais simples até as mais complexas. Exemplos comuns que vemos no nosso cotidiano são os gráficos de barras, linhas, colunas, de pizza, etc., que são simples de entender e podem ser usados para propósitos diferentes. No entanto, quando o objetivo é analisar os dados em seu estado “cru”, o gráfico de dispersão é uma ótima opção. É um tipo de gráfico que é fácil de produzir e interpretar.
Análise de dados possíveis com gráficos de dispersão
O gráfico de dispersão permite diversos tipos de análise de dados que são úteis em alguns contextos. Em geral, eles são amplamente utilizados para identificar padrões, tendências e correlações entre os dados. Algumas das análises possíveis com gráficos de dispersão incluem:
- Relacionar duas ou mais variáveis
- Analisar correlações
- Detectar linearidades ou não-linearidades nos dados
- Verificar a presença de valores extremos
- Visualizar a densidade das observações em um espaço cartesiano
Essas são aplicações interessantes do gráfico de dispersão para o dia a dia da análise de dados, mas também é importante saber quando ele não é aplicável. O exemplo mais evidente é o de inferência de causalidade: os gráficos de dispersão raramente possuem informação suficiente para afirmações causais entre variáveis. Tome cuidado com esse tipo de análise (isso é um erro comum), pois correlação não implica, necessariamente, em causalidade!
O que é um gráfico de dispersão?
Um gráfico de dispersão, chamado de scatter plot no inglês, é um tipo de visualização de dados que mostra a relação entre duas ou mais variáveis. É um gráfico que plota a intersecção dos pontos de um conjunto de dados no plano cartesiano, onde cada ponto representa os valores das variáveis para uma observação específica ou ponto de dados.
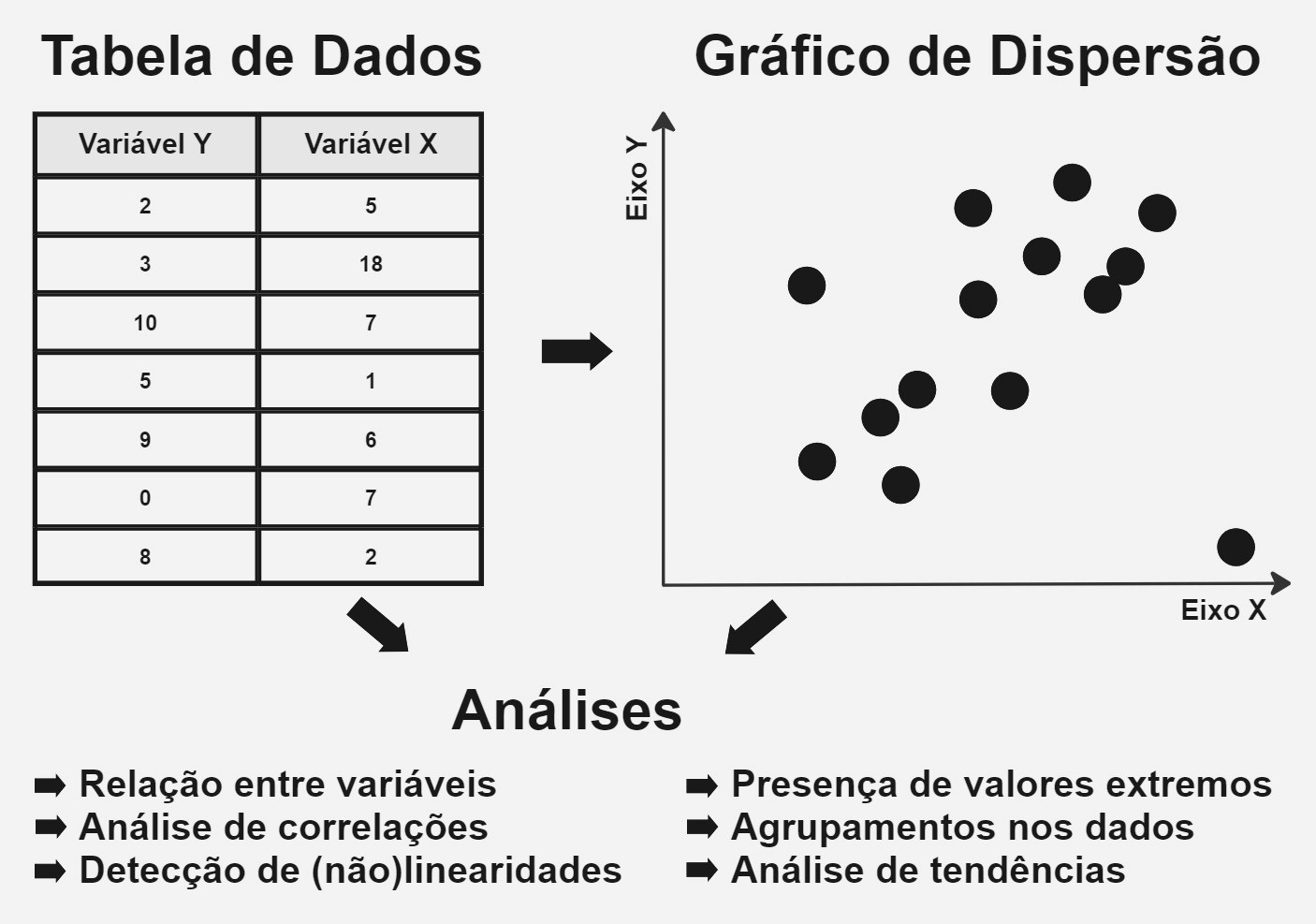
No caso mais comum, de um gráfico bidimensional ou com apenas duas variáveis, o eixo horizontal representa uma das variáveis, geralmente chamada de variável independente ou eixo X, enquanto o eixo vertical representa a outra variável, conhecida como variável dependente ou eixo Y. Cada ponto de dados é plotado na interseção de seus valores correspondentes de X e Y.
Os gráficos de dispersão são frequentemente acompanhados por uma linha de regressão ou outras técnicas de ajuste para estimar a relação de melhor ajuste entre as variáveis e facilitar a análise.
Como gerar gráficos de dispersão?
Em análise e ciência de dados podemos gerar gráficos de dispersão de maneira fácil usando linguagens de programação, como R e Python. A vantagem de usar linguagens de programação para visualizar dados é a possibilidade de customização, flexibilidade para visualizações estáticas ou interativas e a integração com o restante do fluxo de análise ou ciência de dados. Além disso, existem pacotes que possibilitam gerar visualizações com poucos ou um único comando/função, como os famosos ggplot2, matplotlib, plotly, plotnine e outros.
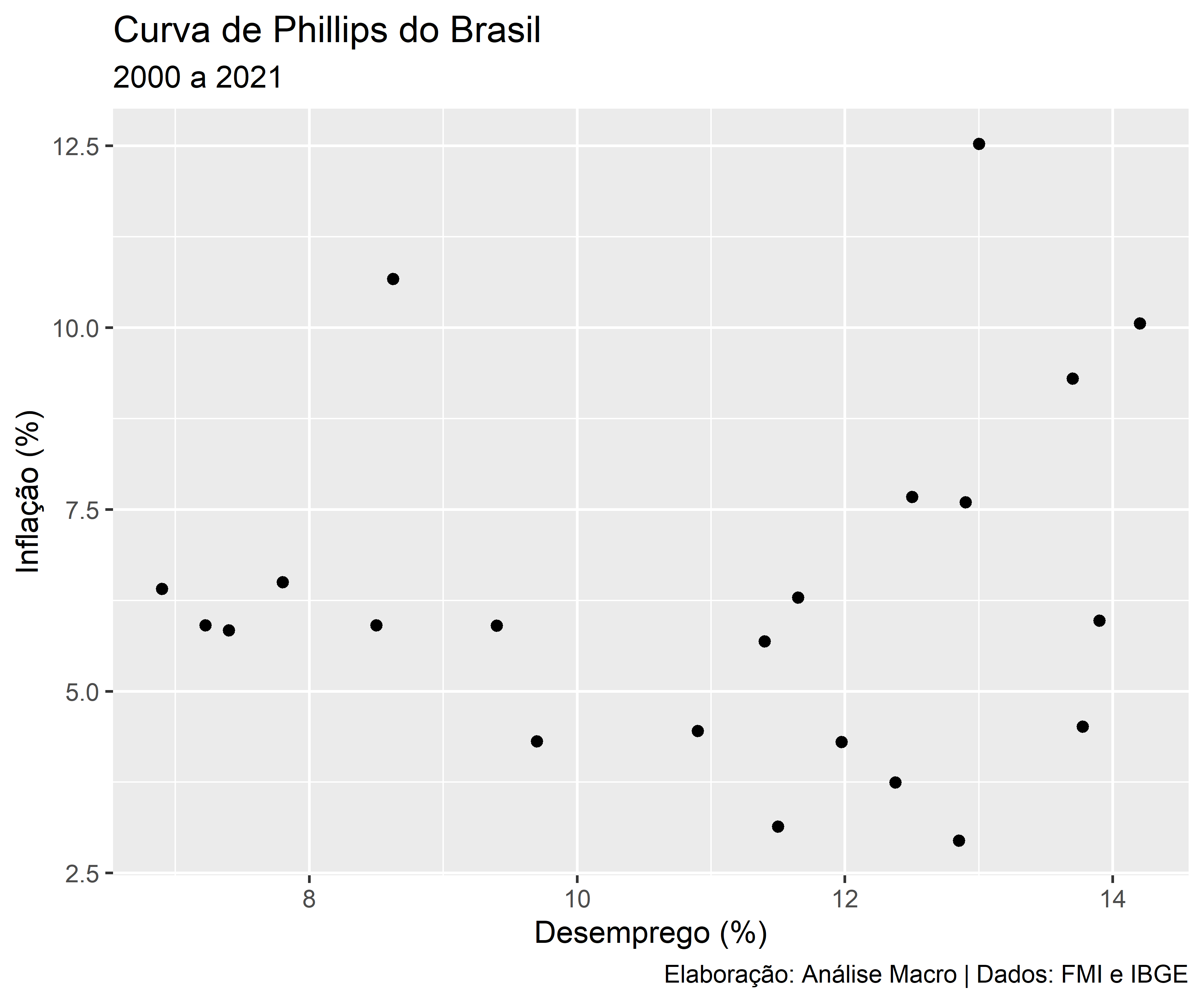
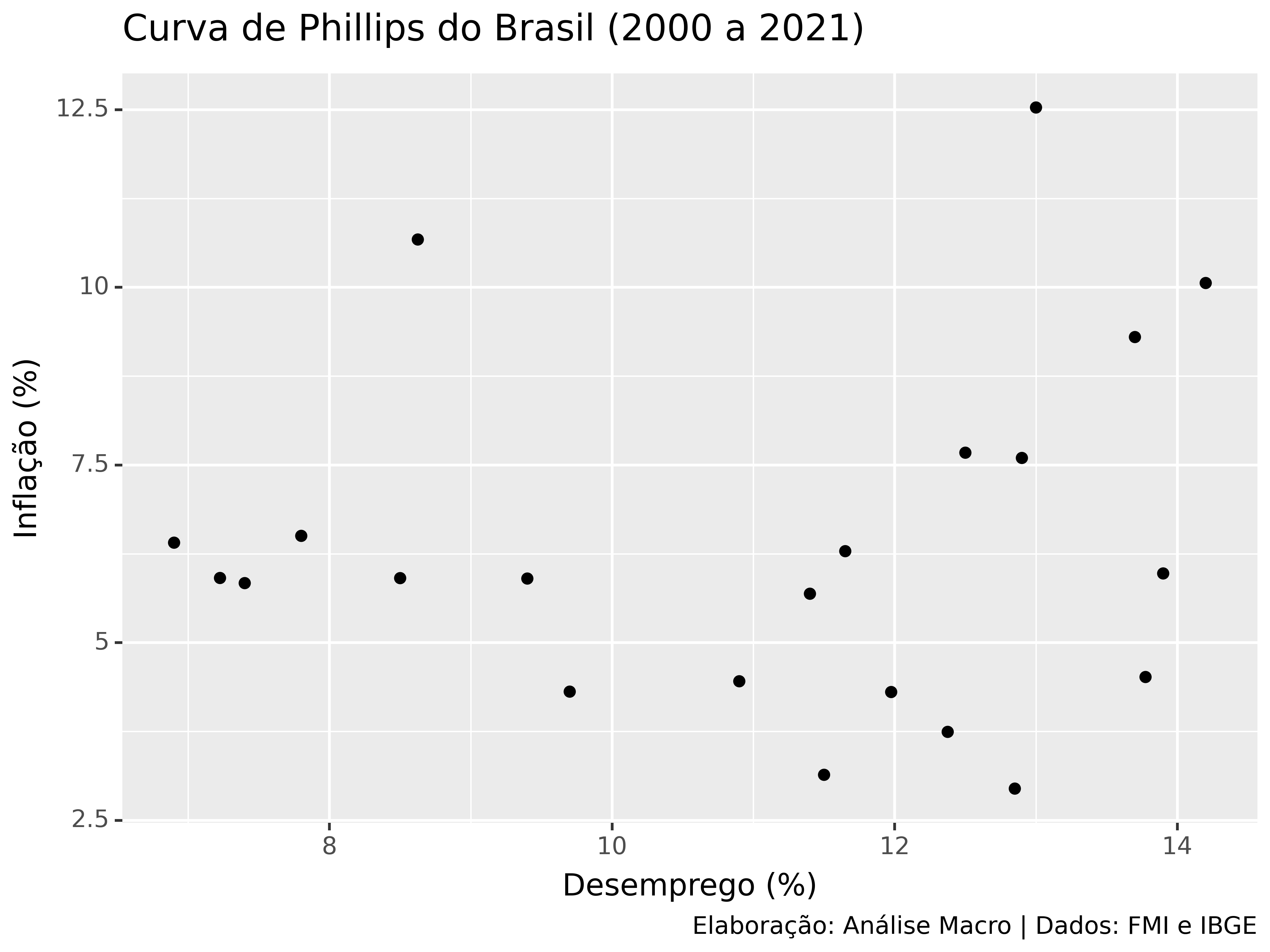
Abaixo mostramos um exemplo de gráfico de dispersão com as variáveis “taxa de desemprego” e “taxa de inflação” da economia brasileira, que é um gráfico conhecido como “curva de Phillips” pelos economistas. Os dados são do período de 2000 até 2021, fim de período, e as fontes são o FMI e o Sidra/IBGE.
R
Código
Python
Código
Conclusão
Visualização de dados é uma habilidade fundamental em análise e ciência de dados, o que inclui a exploração das variáveis através de gráficos, como o de dispersão. Neste artigo vimos sua importância, as principais aplicações e um exemplo prático, permitindo análises rápidas e intuitivas de duas ou mais variáveis.
Saiba mais
Se você se interessa por análise e ciência de dados e quiser adquirir os conhecimentos e habilidades destacados neste artigo, dê uma olhadinha nessa formação especial que a Análise Macro preparou:
E para obter os códigos completos deste exercício e de vários outros, dê uma olhada no Clube AM da Análise Macro, onde publicamos exercícios de ciência de dados toda semana em R e Python.
Referências
Friendly, M., & Denis, D. (2005). The early origins and development of the scatterplot. Journal of the History of the Behavioral Sciences, 41(2), 103-130.
Phillips, A. W. (1958). The relation between unemployment and the rate of change of money wage rates in the United Kingdom, 1861-1957. Economica, 25(100), 283-299.

