Em ciência de dados, a interpretação de resultados é fundamental para alcançar os objetivos da modelagem preditiva. Mas como analisar os modelos? Olhar as métricas de erros é suficiente? O melhor modelo é o que tem a maior acurácia? É necessário escolher um modelo? Neste artigo vamos discutir sobre estas e outras considerações no processo de tomada de decisão de modelos preditivos.
Para aprender mais e ter acesso a códigos confira o curso de Modelagem e Previsão usando Python ou comece do zero em análise de dados com a formação Do Zero à Análise de Dados com Python.
Revisitando o ciclo de análise de dados
O ciclo de análise de dados é uma metodologia de trabalho para resolver problemas com soluções analíticas baseadas em dados. Ao todo, são 6 etapas a serem percorridas:
- Definir o problema e objetivos;
- Identificar e coletar os dados;
- Processar e analisar os dados;
- Desenvolver uma solução baseada em dados;
- Validar a solução;
- Interpretar resultados e tomar decisão.
A interpretação de resultados e a tomada de decisão é a última etapa do ciclo de análise de dados. Em outras palavras, a modelagem preditiva não acaba após calcular os erros do modelo para validar a solução.
Um modelo preditivo é uma solução baseada em dados dentro de um contexto, visando resolver problemas específicos e alcançar objetivos definidos. Isso significa que números sozinhos dificilmente podem levar a uma tomada de decisão assertiva. Para encerrar este ciclo de análise de dados é necessário considerar as etapas anteriores e, dentre elas, o contexto.
Neste espaço já tivemos oportunidades de caminhar por todas estas etapas anteriores, explorando o funcionamento e as nuances com exercícios práticos. Hoje vamos fazer o mesmo com a etapa final para encerrar o ciclo!
Quais são os resultados de modelos preditivos?
Modelos preditivos podem ter múltiplos resultados de interesse para serem analisados. Para qualquer tomada de decisão é necessário primeiro entender que tipo de informação pode ser retirada de cada resultado do modelo. A seguir descrevemos os principais resultados para a maioria das tarefas de modelagem preditiva:
- Previsões: é um valor pontual resultante do modelo, expressando uma estimativa numérica ou uma classificação categórica sobre um determinado evento de interesse.Exemplo: “modelo prevê que a inflação encerre o ano em 5%” e “modelo classifica que o cliente é mau pagador de empréstimos”.
- Intervalos de confiança: é uma faixa de valores resultante do modelo, expressando um intervalo sobre o qual o valor verdadeiro de um determinado evento de interesse pode se encontrar.Exemplo: “modelo prevê que a inflação encerre o ano entre 4,5% e 5,5%”
- Probabilidades: é um valor pontual resultado do modelo, expressando o quão provável é a ocorrência de um determinado evento de interesse, entre 0 e 1.Exemplo: “modelo prevê que a probabilidade de a inflação encerrar o ano acima da meta é de 75%”.
Definir qual é o resultado de interesse em um modelo preditivo é importante para não se desviar do objetivo final. Imagine que, por exemplo, intervalos de confiança sejam fundamentais na previsão de eleições presidenciais. Por consequência, um modelo que entrega apenas previsões pontuais terá pouca utilidade.
Como avaliar os resultados de modelos preditivos?
Para cada resultado possível de um modelo, há métricas de desempenho correspondentes. Entender como calcular e interpretar as métricas é fundamental para tomar boas decisões. Em geral, o objetivo é quantificar o erro de um determinado modelo preditivo. A seguir listamos as principais métricas disponíveis.
Métricas de desempenho para tarefas de regressão:
- ME
- MAE
- RMSE
Métricas de desempenho para tarefas de classificação:
- Sensibilidade
- Especificidade
- Acurácia
Saiba mais sobre as fórmulas e o significado destas métricas através deste link.
Como interpretar o desempenho de modelos preditivos?
As métricas de desempenho servem para analisar quantitativamente o erro do modelo preditivo, mas podem ser enganosas. Um exemplo clássico é o caso de dados categóricos desbalanceados: modelos de classificação tendem a errar bastante as observações da classe minoritária, ao mesmo tempo que métricas, como a acurácia, reportarão “bons” números por influência das observações da classe majoritária. Nem sempre um alto valor de acurácia é desejável, especialmente se o evento de interesse é raro, como no exemplo.
Métodos de visualização gráfica podem trazer uma nova perspectiva na avaliação de modelos preditivos. Um simples gráfico de dispersão entre valores observados e valores previstos pode revelar padrões que podem ser difíceis de captar apenas usando tabelas numéricas de estatísticas e métricas. Imagine que você comparou 5 modelos preditivos para um variável numérica, medida em R$, e viu que o modelo B apresentou o menor erro, medido pelo RMSE. Em seguida você plotou os dados e viu que o modelo está errando na casa dos milhões de R$. Provavelmente este ainda não é o melhor modelo e por isso é importante visualizar os dados antes de tomar uma decisão final.
Em suma, é importante utilizar as métricas de desempenho e as visualizações gráficas para avaliar os resultados de modelos preditivos, mas sempre considerando o contexto do trabalho.
Tomada de decisão técnica
O objetivo da modelagem preditiva é encontrar uma solução analítica com o menor erro ou maior acurácia possível. Nesta busca, é comum desenvolver o trabalho utilizando um modelo simples para base de comparação e outros modelos, em graus variados de complexidade, para teste. Este esquema possibilita o rankeamento dos modelos de acordo com o menor erro ou maior acurácia, conforme uma métrica de desempenho de escolha.
A escolha técnica do modelo preditivo costuma ser o modelo que performou melhor na métrica de desempenho escolhida, mas isso não significa que a solução final precise ser apenas um modelo. É possível, e muitas vezes vantajoso, utilizar uma combinação de modelos. Em determinados casos, pode-se alcançar resultados melhores em relação a modelos individuais.
Nesta etapa é útil criar uma tabela rankeando modelos preditivos por métricas de desempenho, como no exemplo abaixo:
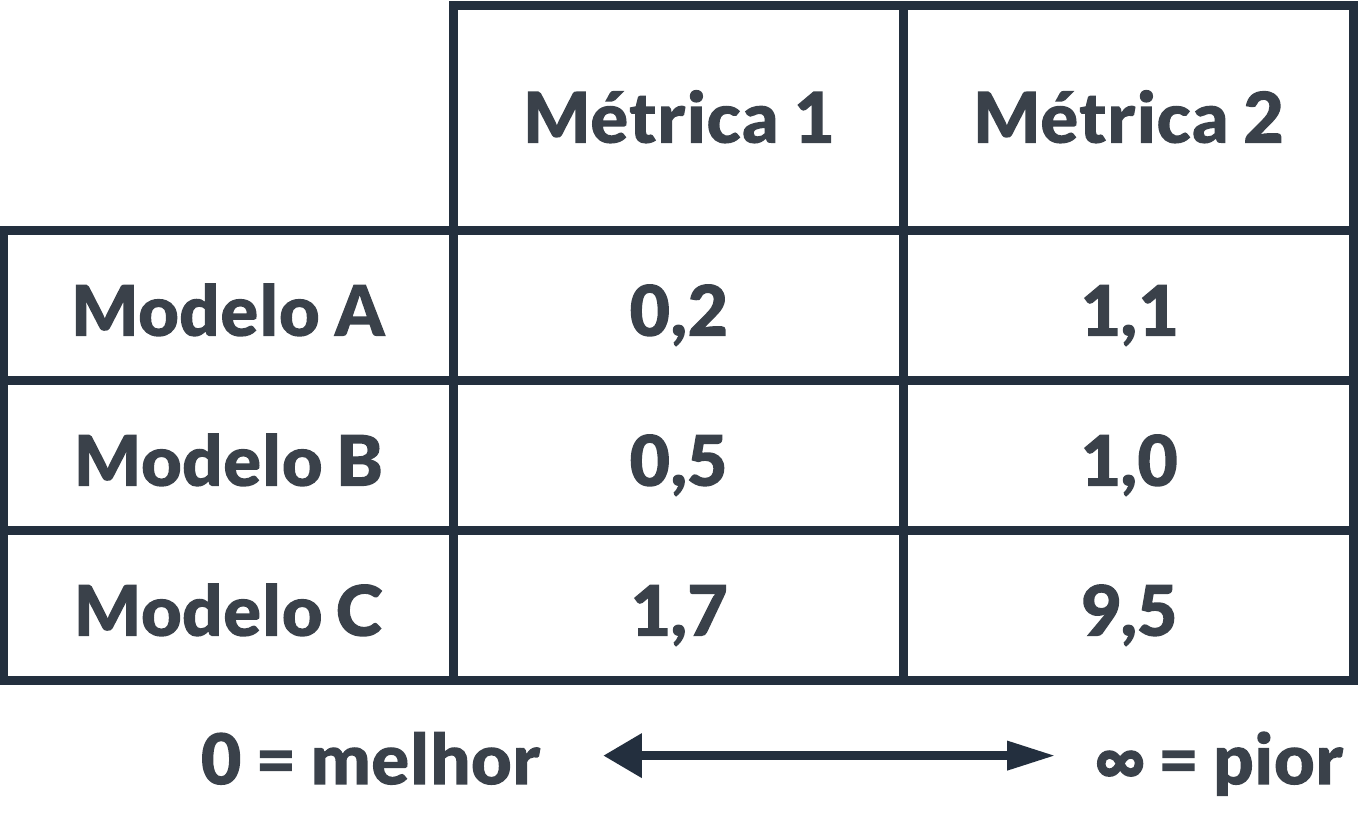
- Primeiro escolher a métrica e depois escolher o modelo, se houver clareza sobre a métrica, sua interpretação e objetivos;
- Escolher n modelos e trabalhar com uma solução combinada, se não houver clareza sobre a métrica, sua interpretação e objetivos.
A escolha do caminho a ser percorrido vai depender, mais uma vez, do contexto da modelagem preditiva. Em geral, procura-se minimizar riscos e vieses que os modelos podem trazer. Frisa-se que há outros caminhos a considerar, mas que não discutiremos nesta oportunidade.
Tomada de decisão de negócios
A escolha de negócio do modelo preditivo tem o objetivo de maximizar lucro. Nem sempre, ou quase nunca, cientistas e analistas de dados consideram este objetivo no desenvolvimento do seu trabalho. E é por este motivo que pode acontecer de uma tomada de decisão de negócios se sobrepor a uma tomada de decisão técnica.
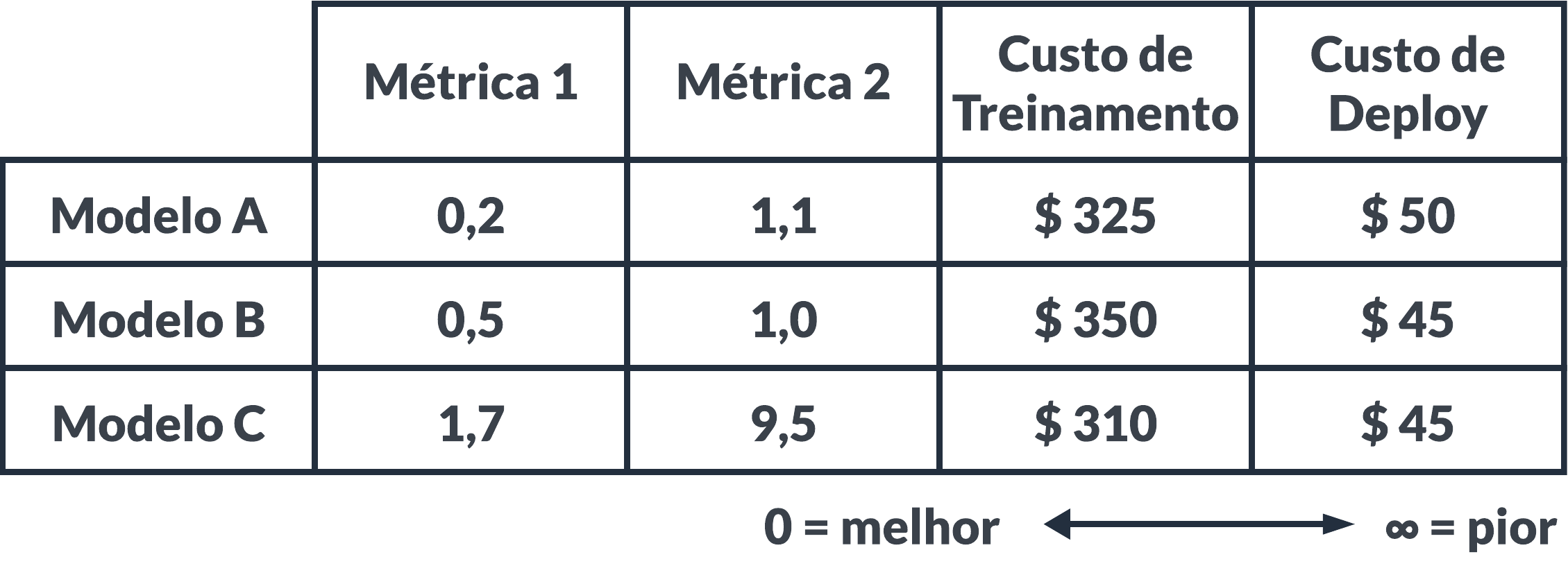
Acrescentando informações relevantes de negócios na tabela de rankeamento de modelos preditivos, poderíamos chegar no seguinte cenário:
Conclusão
Em ciência de dados, a interpretação de resultados é fundamental para alcançar os objetivos da modelagem preditiva. Mas como analisar os modelos? Olhar as métricas de erros é suficiente? O melhor modelo é o que tem a maior acurácia? É necessário escolher um modelo? Neste artigo discutimos sobre estas e outras considerações no processo de tomada de decisão de modelos preditivos.
Quer aprender mais?
Clique aqui para fazer seu cadastro no Boletim AM e baixar o código que produziu este exercício, além de receber novos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas diretamente em seu e-mail.

