Iniciar uma nova análise de dados é quase sempre como caminhar no deserto: é difícil saber exatamente onde você vai chegar no final da jornada. No entanto, logo nas primeiras etapas do ciclo de análise de dados, especialmente após coletar os dados, já fica claro uma coisa muito importante: as variáveis com as quais lidamos no dia a dia de análise de dados podem ser de diversos tipos.
Variáveis numéricas, categóricas, binárias, contínuas, discretas são apenas alguns dos termos que são utilizados para distinguir o tipo do dado. Como são muitos termos, além de serem termos técnicos, é normal que ocorra confusão quando se fala em tipos de variáveis em ciência de dados.
Portanto, nesse artigo vamos entender do que se tratam os principais tipos de variáveis (quantitativas e qualitativas), de forma a ter uma definição clara para servir de referência. Também mostraremos exemplos, com dados disponíveis publicamente, desses tipos de variáveis, assim fica mais fácil associar o termo técnico com um exemplo prático. Por fim, vamos mostrar algumas ferramentas de análise exploratória de dados que se aplicam conforme o tipo de variável, o que permite um trabalho mais assertivo.
O que é uma variável quantitativa?
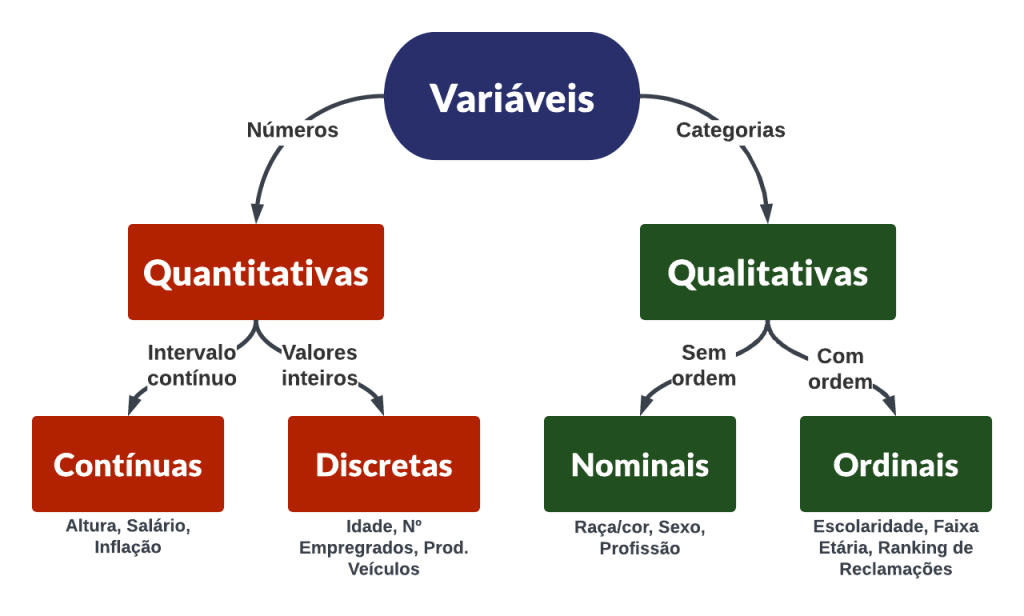
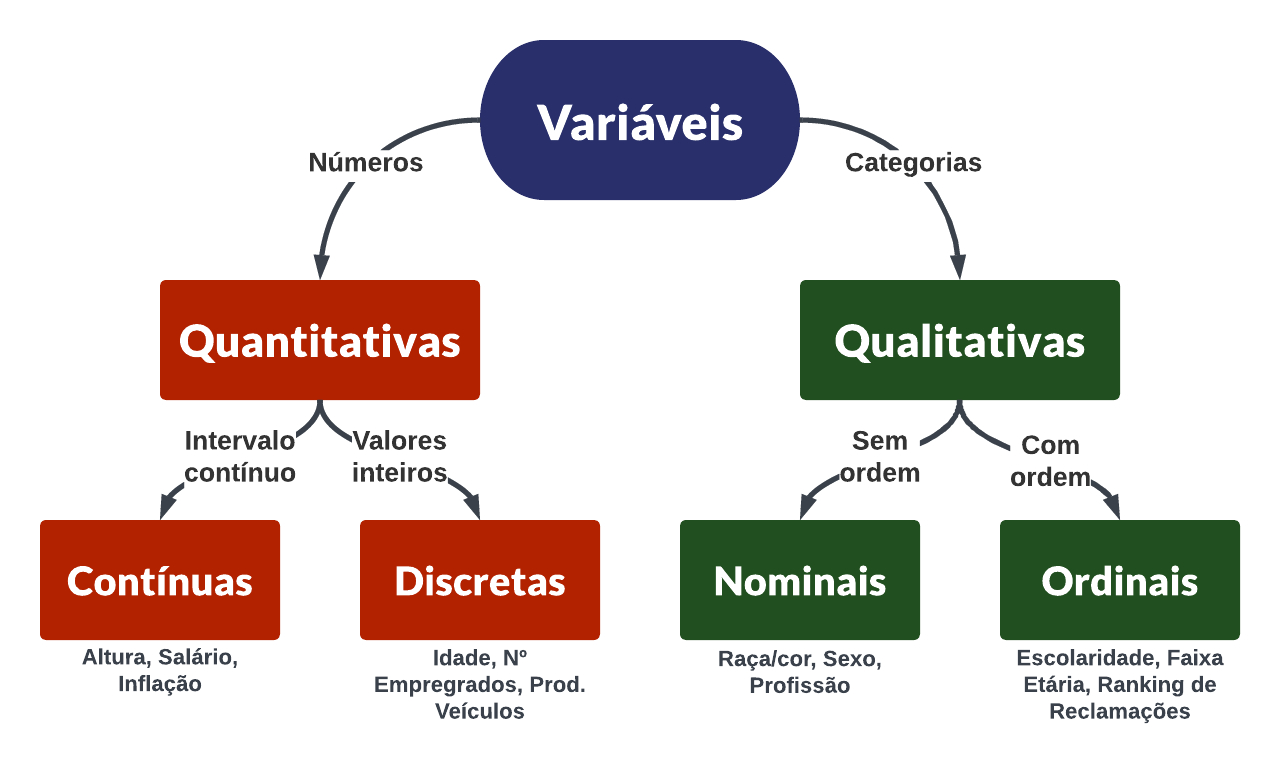
As variáveis quantitativas são aquelas que podem ser medidas numericamente e expressam uma quantidade ou magnitude. Elas podem ser contínuas, quando assumem valores em um intervalo contínuo (por exemplo: 1.2, 0.5, -3.1), ou discretas, quando assumem apenas valores inteiros (por exemplo: 1, -5, 7). As variáveis quantitativas são importantes na análise de dados, pois permitem realizar operações matemáticas como média, desvio padrão, correlação e regressão, que possibilitam a identificação de padrões e relações entre variáveis.
Existem diversos exemplos de dados quantitativos disponíveis publicamente no Brasil, como dados demográficos, econômicos, de saúde e de educação. Alguns exemplos incluem:
- Renda (PNADC/IBGE)
- Taxa de inflação (IPCA/IBGE)
- Índice de desenvolvimento humano (IDH/PNUD)
- Taxa de mortalidade infantil (DATASUS)
- Número de matrículas em escolas públicas (MEC)
Para realizar a análise exploratória de dados de variáveis quantitativas existem diversas ferramentas disponíveis. Algumas delas são:
- Histograma: permite visualizar a distribuição dos valores da variável e identificar a presença de outliers ou valores extremos.
- Boxplot: também é uma ferramenta útil para identificar valores extremos e comparar a distribuição de diferentes grupos.
Além disso, a análise de correlação e regressão pode ser utilizada para identificar relações entre variáveis e prever valores futuros. O uso dessas ferramentas pode ajudar a entender melhor os dados quantitativos e extrair insights úteis para a tomada de decisão.
O que é uma variável qualitativa?
As variáveis qualitativas são aquelas que não podem ser medidas numericamente, mas sim descritas ou categorizadas de acordo com suas características. Elas podem ser de dois tipos: nominais, quando não existe uma ordem natural entre as categorias (por exemplo: profissão, sexo), ou ordinais, quando existe uma ordem natural entre as categorias (por exemplo: escolaridade, ranking). As variáveis qualitativas são importantes na análise de dados, pois permitem identificar padrões e tendências entre as diferentes categorias.
Existem diversos exemplos de dados qualitativos disponíveis publicamente no Brasil, como dados de características pessoais, localidade ou enquadramento jurídico. Alguns exemplos incluem:
- Raça/cor (Censo Demográfico/IBGE)
- Região geográfica (PNAD/IBGE)
- Porte da empresa (RAIS/MTE)
Para realizar a análise exploratória de dados de variáveis qualitativas, existem diversas ferramentas disponíveis. Algumas delas são:
- Tabela de frequências: permite contabilizar a frequência de cada categoria e identificar a proporção de cada uma em relação ao total.
- Gráfico de barras também é uma ferramenta útil para visualizar a distribuição das categorias e comparar a frequência entre elas.
Além disso, a análise de associação entre variáveis qualitativas pode ser realizada por meio de testes estatísticos, como o teste qui-quadrado. O uso dessas ferramentas pode ajudar a entender melhor os dados qualitativos e extrair insights úteis para a tomada de decisão.
Exemplo prático
Agora que entendemos os conceitos de variáveis quantitativas e qualitativas, vamos fixar o conhecimento com um exemplo prático de uma tabela de dados que possui estes tipos de variáveis. A tabela abaixo mostra os dados do campeonato Brasileirão (série A), referente aos anos de 2020/2021 (dados de Transfermarkt):
R
Código
Rows: 380
Columns: 36
$ ano_campeonato <int> 2020, 2020, 2020, 2020, 2020, 2020, 2020, 202…
$ data <date> 2020-08-09, 2020-08-09, 2020-08-09, 2020-08-…
$ horario <chr> "12:30", "02:00", "09:00", "09:00", "12:00", …
$ rodada <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, …
$ estadio <chr> "Estádio Major Antônio Couto Pereira", "Estád…
$ arbitro <chr> "Bruno Arleu de Araújo", "Edina Alves Batista…
$ publico <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, …
$ publico_max <int> 37182, 35000, 78838, 20120, 60540, 60326, 469…
$ time_man <chr> "Coritiba FC", "Sport Recife", "Flamengo", "S…
$ time_vis <chr> "Internacional", "Ceará SC", "Atlético-MG", "…
$ tecnico_man <chr> "Eduardo Barroca", "Daniel Paulista", "Domène…
$ tecnico_vis <chr> "Eduardo Coudet", "Guto Ferreira", "Jorge Sam…
$ colocacao_man <int> 18, 3, 16, 8, 5, 19, 15, 12, 20, 9, 7, 2, 11,…
$ colocacao_vis <int> 6, 14, 7, 11, 17, 2, 4, 13, 1, 10, 12, 20, 15…
$ valor_equipe_titular_man <int> 6430000, 7000000, 76200000, 28450000, 2535000…
$ valor_equipe_titular_vis <int> 21250000, 6180000, 20500000, 10700000, 209800…
$ idade_media_titular_man <dbl> 28.1, 27.2, 29.0, 27.5, 30.1, 29.9, 26.6, 28.…
$ idade_media_titular_vis <dbl> 27.8, 29.8, 24.5, 25.2, 27.4, 25.9, 29.1, 26.…
$ gols_man <int> 0, 3, 0, 1, 1, 0, 1, 0, 0, 1, 3, 2, 1, 3, 1, …
$ gols_vis <int> 1, 2, 1, 1, 0, 2, 2, 0, 3, 1, 2, 1, 1, 0, 0, …
$ gols_1_tempo_man <int> 0, 3, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 2, 1, …
$ gols_1_tempo_vis <int> 0, 1, 1, 0, 0, 2, 1, 0, 1, 1, 2, 1, 0, 0, 0, …
$ escanteios_man <int> 2, 0, 9, 4, NA, 3, 8, 4, 2, 6, 8, 0, 11, 11, …
$ escanteios_vis <int> 6, 1, 2, 2, NA, 4, 5, 7, 9, 3, 4, 0, 3, 5, 8,…
$ faltas_man <int> 5, 1, 12, 10, NA, 12, 18, 18, 16, 19, 19, 0, …
$ faltas_vis <int> 13, 3, 24, 19, NA, 7, 14, 12, 19, 11, 11, 0, …
$ chutes_bola_parada_man <int> 11, 2, 21, 19, NA, 7, 14, 10, 18, 11, 11, 0, …
$ chutes_bola_parada_vis <int> 5, 1, 10, 9, NA, 11, 14, 18, 16, 17, 18, 0, 1…
$ defesas_man <int> 3, 0, 4, 5, NA, 3, 2, 5, 3, 2, 2, 0, 2, 3, 3,…
$ defesas_vis <int> 0, 0, 2, 3, NA, 3, 1, 4, 3, 2, 10, 0, 7, 4, 4…
$ impedimentos_man <int> 3, 1, 2, 4, NA, 1, 0, 4, 0, 0, 3, 0, 1, 2, 1,…
$ impedimentos_vis <int> 2, 0, 3, 2, NA, 1, 1, 2, 1, 2, 1, 0, 1, 1, 5,…
$ chutes_man <int> 1, 4, 17, 10, NA, 10, 15, 12, 9, 14, 25, 2, 2…
$ chutes_vis <int> 8, 2, 10, 18, NA, 13, 12, 17, 15, 12, 7, 1, 9…
$ chutes_fora_man <int> 1, 0, 10, 5, NA, 4, 8, 8, 4, 7, 9, 0, 12, 5, …
$ chutes_fora_vis <int> 3, 0, 2, 8, NA, 4, 7, 7, 6, 5, 2, 0, 6, 3, 8,…Python
Código
Downloading: 0%| | 0/380 [00:00<?, ?rows/s]
Downloading: 100%|##########| 380/380 [00:00<00:00, 814.08rows/s]
Downloading: 100%|##########| 380/380 [00:00<00:00, 812.34rows/s]Código
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 380 entries, 0 to 379
Data columns (total 36 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ano_campeonato 380 non-null Int64
1 data 380 non-null dbdate
2 horario 380 non-null object
3 rodada 380 non-null Int64
4 estadio 380 non-null object
5 arbitro 380 non-null object
6 publico 380 non-null Int64
7 publico_max 380 non-null Int64
8 time_man 380 non-null object
9 time_vis 380 non-null object
10 tecnico_man 367 non-null object
11 tecnico_vis 367 non-null object
12 colocacao_man 380 non-null Int64
13 colocacao_vis 380 non-null Int64
14 valor_equipe_titular_man 367 non-null Int64
15 valor_equipe_titular_vis 367 non-null Int64
16 idade_media_titular_man 367 non-null float64
17 idade_media_titular_vis 367 non-null float64
18 gols_man 380 non-null Int64
19 gols_vis 380 non-null Int64
20 gols_1_tempo_man 380 non-null Int64
21 gols_1_tempo_vis 380 non-null Int64
22 escanteios_man 374 non-null Int64
23 escanteios_vis 374 non-null Int64
24 faltas_man 374 non-null Int64
25 faltas_vis 374 non-null Int64
26 chutes_bola_parada_man 374 non-null Int64
27 chutes_bola_parada_vis 374 non-null Int64
28 defesas_man 374 non-null Int64
29 defesas_vis 374 non-null Int64
30 impedimentos_man 374 non-null Int64
31 impedimentos_vis 374 non-null Int64
32 chutes_man 374 non-null Int64
33 chutes_vis 374 non-null Int64
34 chutes_fora_man 374 non-null Int64
35 chutes_fora_vis 374 non-null Int64
dtypes: Int64(26), dbdate(1), float64(2), object(7)
memory usage: 116.6+ KBNessa tabela há diversas informações sobre os jogos que aconteceram no campeonato Brasileirão no período indicado: times disputantes, local, data, resultado do jogo, características dos jogadores e estatísticas da partida. Agora vamos tentar identificar pelo menos um exemplo de cada tipo de variável nessa tabela.
Abaixo classificamos algumas das variáveis disponíveis na tabela de exemplo:
Variáveis quantitativas:
- Gols do time mandante (
gols_man): discreta; - Idade média da equipe titular do time mandante (
idade_media_titular_man): contínua.
Variáveis qualitativas:
- Time mandante (
time_man): nominal; - Data da partida (
data): ordinal.
Note que algumas variáveis podem ser rapidamente identificadas de forma intuitiva (como o nº de gols de um time na partida), mas outras exigem um pouco de raciocínio. Por exemplo, a variável idade_media_titular_man informa a idade dos jogadores sumarizada em uma estatística. Acima mencionamos que a idade é uma variável quantitativa discreta, mas isso é válido para quando ela é expressa em anos inteiros. No caso dessa tabela de dados ela é expressa em valores contínuos, por ter sido calculado a estatística média dos dados. A mesma atenção é válida para variáveis de tempo (que é uma medida contínua), mas que em alguns casos podem ser “discretizadas” ou transformadas em rótulos/categorias com ordem, como é o caso da coluna data.
Conclusão
Aprender a diferenciar os tipos de variáveis encontradas em tabelas de dados é fundamental no dia a dia de trabalho em ciência de dados. Essa distinção torna mais assertivo o trabalho da análise exploratória de dados, que possui diversas técnicas e ferramentas interessantes e aplicáveis conforme o tipo do dado. Nesse artigo vimos as definições e os exemplos de variáveis quantitativas e qualitativas, além de termos classificado as variáveis de um conjunto de dados real para aprender na prática as diferenças.
Saiba mais
Se você se interessa por análise e ciência de dados e quiser adquirir os conhecimentos e habilidades destacados neste artigo, dê uma olhadinha nessa formação especial que a Análise Macro preparou:
E para obter os códigos completos deste exercício e de vários outros, dê uma olhada no Clube AM da Análise Macro, onde publicamos exercícios de ciência de dados toda semana em R e Python.

