Uma das questões que têm intrigado analistas e economistas de mercado é a desconexão entre o Índice Bovespa e a economia real. A despeito do IBOV ter flertado com o nível histórico de 100 mil pontos, a economia real tem patinado nesse início de 2019, como pode ser avaliado a partir de indicadores de alta frequência como o IBC-Br. Olhando para os dados, como poderíamos encaminhar essa questão? É o que vemos nesse post da Análise Macro - para aprender a fazer análises como essa, não deixe de conhecer o nosso curso de Análise de Conjuntura usando o R.
Antes de mais nada, precisamos pegar os dados. Vamos utilizar o pacote quantmod para ter acesso ao índice Bovespa. O código abaixo puxa os dados da base do yahoo finance diretamente para o RStudio.
# IBOVESPA
library(quantmod)
library(xts)
env <- new.env()
getSymbols("^BVSP",src="yahoo",
env=env,
from=as.Date('2001-01-01'))
ibovespa = env$BVSP[,4]
ibovespa = ibovespa[complete.cases(ibovespa)]
ibovespa = apply.quarterly(ibovespa, FUN=mean)
ibovespa = ts(ibovespa, start=c(2001,01), freq=4)
De posse dos dados do IBOV, qual seria a melhor proxy para a economia real? Pensei aqui em pegar o número índice da FBCF, depois a variação interanual desse índice, para ver se há alguma correlação com o IBOV. O código abaixo usa o pacote sidrar e operacionaliza isso.
# FBCF library(sidrar) fbcf = get_sidra(api="/t/1620/n1/all/v/all/p/all/c11255/93406/d/v583%202") fbcf = fbcf$Valor fbcf = ts(fbcf, start=c(1996,01), freq=4) dfbcf = (fbcf/lag(fbcf,-4)-1)*100
Agora que já temos os dados do Ibovespa e da variação interanual da FBCF, podemos ver um gráfico com as duas séries. Como, naturalmente, elas estão em escalas diferentes, precisaremos colocar um no eixo principal e outra no eixo secundário.
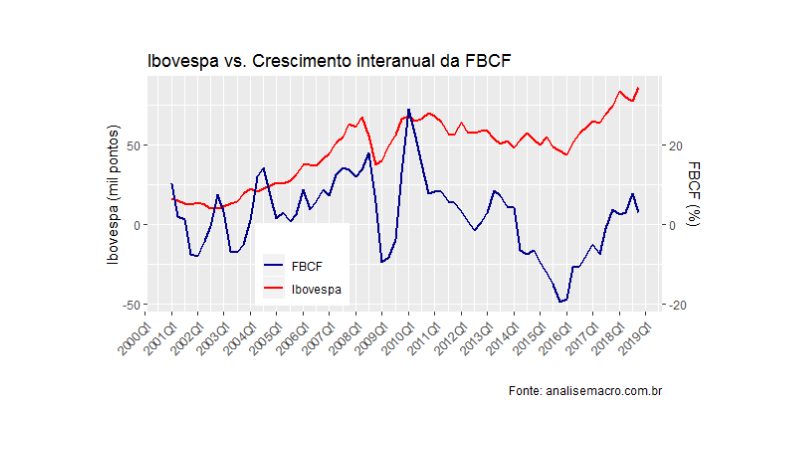
O gráfico acima sugere que exista de fato uma correlação entre elas, mas a relação parece ter se descolado de 2010 para frente. A correlação para toda a amostra é de 0,18, enquanto até 2010 a correlação é de 0,57. Ademais, pode ser interessante verificar a correlação entre as séries, defasando a variação da FBCF. Os gráficos abaixo ilustram até a terceira defasagem.
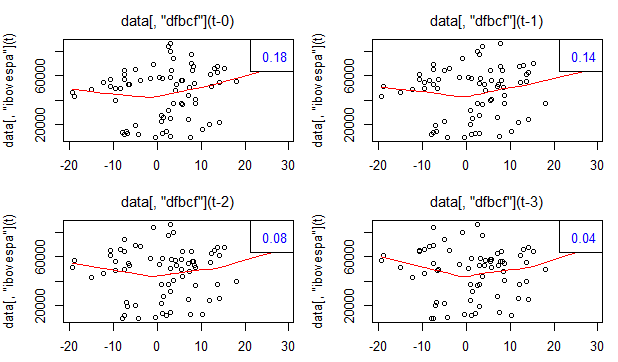
Como se pode ver, há um decaimento na correlação entre as variáveis, conforme aumentamos a defasagem da variação da FBCF.
O que isso tem a dizer? Por enquanto, nada. Observe que estamos fazendo apenas uma análise preliminar dos dados, tentando ver alguma relação entre o IBOV e uma proxy da economia real. Para nos aprofundarmos no assunto, teríamos que ver outros candidatos a proxy, bem como construir um modelo que avalie mais profundamente a relação entre as variáveis, como fazemos no nosso curso de Séries Temporais usando o R.
Outro ponto que precisa ser avaliado é que o IBOV reflete expectativas do mercado a cerca do que vai ocorrer com a economia doméstica e com o cenário externo ao longo do tempo. Isto é, para que as séries acima andem juntas é preciso "limpar" muita coisa.
Ao longo das próximas semanas, vamos construir um modelo para avaliar a relação entre as séries. Por enquanto, membros do Clube do Código têm acesso ao script completo desse comentário lá no repositório do github. Até lá!

