Ao realizar análises de conjuntura econômica, devemos ter em mente diversos indicadores em diferentes áreas, e o cenário externo deve ter um espaço especial nessas análises. O foco é acompanhar indicadores econômicos das principais economias internacionais, de forma a tirar conclusões sobre os seus efeitos sobre o Brasil e na economia mundial. No Relatório AM de hoje iremos mostrar como é possível acompanhar esses indicadores no R. Você também pode aprender a como realizar uma análise completa através do nosso Curso de Análise de Conjuntura com o R.
Pacotes
Para coletar, tratar e visualizar os dados, devemos utilizar alguns pacotes importantes. Utilizaremos o pacote {OECD} para retirar os dados de Economias Internacionais através da base de dados do site de OECD. Para tratamento, usaremos a família de pacotes do tidyverse.
library(tidyverse) library(OECD) library(lubridate)
Parâmetros da OECD
Retiramos os parâmetros dos dados através do site da OECD. Como exemplo, iremos utilizar dois indicadores, o PIB pela ótica da despesa e a Inflação de diversos países.
## Parâmetros e códigos para coleta de dados parametros <- list( # Contas Nacionais Trimestrais (código do dataset na OECD) dataset_qna = "QNA", # Main Economic Indicators - dataset com principais indicadores (código do dataset na OECD) dataset_mei = "MEI", # PIB - Ótica da despesa (lista de países e variáveis para filtro no dataset QNA) filter_gdp = "AUS+CHL+JPN+MEX+USA+EA19+CHN+IND+RUS+SAU.B1_GE.GYSA+GPSA.Q", # Taxa de Inflação (lista de países e variáveis para filtro no dataset MEI) filter_inflation = "AUS+CHL+JPN+MEX+USA+EA19+CHN+IND+RUS+SAU.CPALTT01.GPSA+GY.M" )
Coleta dos dados
Coletamos os indicadores através do pacote {OECD}.
# Coleta dos dados # PIB - Ótima da despesa str_gdp <- OECD::get_data_structure(parametros$dataset_qna) raw_gdp_oecd <- OECD::get_dataset( dataset = parametros$dataset_qna, filter = list(parametros$filter_gdp), pre_formatted = TRUE ) # Taxa de Inflação str_inflation <- OECD::get_data_structure(parametros$dataset_mei) raw_inflation_oecd <- OECD::get_dataset( dataset = parametros$dataset_mei, filter = list(parametros$filter_inflation), pre_formatted = TRUE )
Tratamento
Realizamos os tratamentos utilizando o universo do tidyverse para visualizarmos os dois indicadores.
## Tratamento dos dados
# PIB - Ótica da despesa
gdp_oecd <- raw_gdp_oecd %>%
dplyr::filter(FREQUENCY == "Q") %>%
dplyr::select(
date = obsTime,
location = LOCATION,
measure = MEASURE,
value = obsValue,
status = dplyr::contains("OBS_STATUS")
) %>%
dplyr::left_join(
str_gdp$LOCATION,
by = c("location" = "id")
) %>%
dplyr::mutate(
dplyr::across(
dplyr::any_of("status"),
~dplyr::recode(
status,
"E" = "Estimated value",
"P" = "Provisional value"
)
),
value = as.numeric(value),
measure = dplyr::recode(
measure,
"GPSA" = "% change from same quarter of previous year",
"GYSA" = "% change from previous quarter"
),
label = stringr::str_remove_all(label, " \ | \"),
date = lubridate::yq(date)
)
# Taxa de Inflação
inflation_oecd <- raw_inflation_oecd %>%
dplyr::select(
date = obsTime,
location = LOCATION,
measure = MEASURE,
value = obsValue,
status = dplyr::contains("OBS_STATUS")
) %>%
dplyr::left_join(
str_inflation$LOCATION,
by = c("location" = "id")
) %>%
dplyr::mutate(
date = paste0(date, "-01") %>% lubridate::as_date(format = "%Y-%m-%d"),
dplyr::across(
dplyr::any_of("status"),
~dplyr::recode(
status,
"E" = "Estimated value",
"P" = "Provisional value"
)
),
value = as.numeric(value),
measure = dplyr::recode(
measure,
"GY" = "Growth rate same period previous year"
),
label = stringr::str_remove_all(label, " \| \")
)
| \"),
date = lubridate::yq(date)
)
# Taxa de Inflação
inflation_oecd <- raw_inflation_oecd %>%
dplyr::select(
date = obsTime,
location = LOCATION,
measure = MEASURE,
value = obsValue,
status = dplyr::contains("OBS_STATUS")
) %>%
dplyr::left_join(
str_inflation$LOCATION,
by = c("location" = "id")
) %>%
dplyr::mutate(
date = paste0(date, "-01") %>% lubridate::as_date(format = "%Y-%m-%d"),
dplyr::across(
dplyr::any_of("status"),
~dplyr::recode(
status,
"E" = "Estimated value",
"P" = "Provisional value"
)
),
value = as.numeric(value),
measure = dplyr::recode(
measure,
"GY" = "Growth rate same period previous year"
),
label = stringr::str_remove_all(label, " \| \")
)


Visualização
Visualizamos os gráficos através do ggplot2
# Cores dos gráficos
colors <- c(
blue = "#282f6b",
red = "#b22200",
yellow = "#eace3f",
green = "#224f20",
purple = "#5f487c",
orange = "#b35c1e",
turquoise = "#419391",
green_two = "#839c56",
light_blue = "#3b89bc",
gray = "#666666"
)
# Gerar gráfico
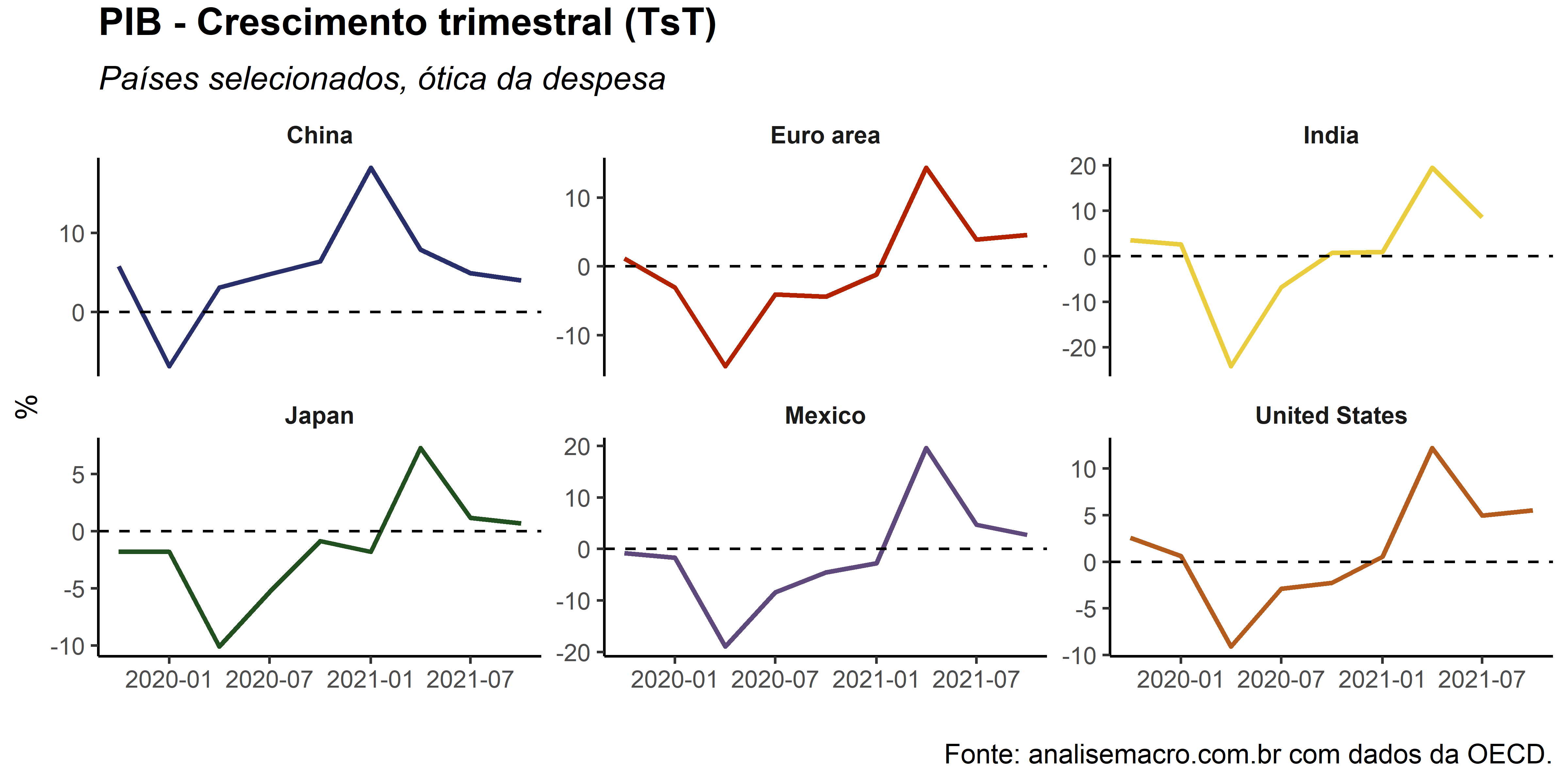
gdp_oecd %>%
dplyr::filter(
date >= max(date) %m-% lubridate::years(2),
measure == "% change from previous quarter",
!location %in% c("CHL", "RUS", "SAU", "AUS")
) %>%
ggplot(aes(x = date, y = value, colour = label))+
geom_line(size = .8)+
geom_hline(yintercept = 0, linetype = "dashed")+
ggplot2::scale_colour_manual(NULL, values = unname(colors))+
labs(x = "",
y = "%",
title = "PIB - Crescimento trimestral (TsT)",
subtitle = "Países selecionados, ótica da despesa",
caption = "Fonte: analisemacro.com.br com dados da OECD.")+
theme(
plot.title = ggplot2::element_text(size = 14, face = "bold", hjust = 0, vjust = 2),
plot.subtitle = ggplot2::element_text(size = 12, face = "italic", hjust = 0),
plot.caption = ggplot2::element_text(size = 10, hjust = 1),
panel.background = ggplot2::element_rect(fill = "white", colour = "white"),
axis.line.x.bottom = ggplot2::element_line(colour = "black"),
axis.line.y.left = ggplot2::element_line(colour = "black"),
legend.position = "top",
legend.direction = "horizontal",
strip.background = ggplot2::element_rect(fill = "transparent", colour = NA),
strip.text = ggplot2::element_text(face = "bold")
)+
facet_wrap(~label, scales = "free_y") +
ggplot2::theme(legend.position = "none")

# Gerar gráfico
inflation_oecd %>%
dplyr::filter(
date >= max(date) %m-% lubridate::years(2),
!location %in% c("CHL", "RUS", "SAU", "AUS")
) %>%
ggplot(aes(x = date, y = value, colour = label))+
geom_line(size = .8)+
geom_hline(yintercept = 0, linetype = "dashed")+
ggplot2::scale_colour_manual(NULL, values = unname(colors))+
labs(x = "",
y = "%",
title = "Inflação - Variação interanual (AsA)",
subtitle = "Países selecionados",
caption = "Fonte: analisemacro.com.br com dados da OECD.")+
theme(
plot.title = ggplot2::element_text(size = 14, face = "bold", hjust = 0, vjust = 2),
plot.subtitle = ggplot2::element_text(size = 12, face = "italic", hjust = 0),
plot.caption = ggplot2::element_text(size = 10, hjust = 1),
panel.background = ggplot2::element_rect(fill = "white", colour = "white"),
axis.line.x.bottom = ggplot2::element_line(colour = "black"),
axis.line.y.left = ggplot2::element_line(colour = "black"),
legend.position = "none",
legend.direction = "horizontal",
strip.background = ggplot2::element_rect(fill = "transparent", colour = NA),
strip.text = ggplot2::element_text(face = "bold")
)+
facet_wrap(~label, scales = "free_y")

Quer saber mais?
Veja nosso Curso de R para Economistas, e nosso Curso de Análise de Conjuntura com o R. A partir do conhecimento obtido com os cursos, você pode realizar análises completas sobre a economia nacional e internacional.


