
No presente exercício, procuramos verificar como o Banco Central reage, por meio de mudanças na taxa básica de juros, a um choque na taxa de câmbio BRL/USD. Construímos todo o processo de coleta, tratamento de dados e construção do modelo usando o Python como ferramenta.
Na seção anterior, discutimos a relação entre o Índice de Volatilidade VIX e a taxa de câmbio BRL/USD. Verificamos que um choque naquele causa uma reação neste. De forma a complementar o entendimento do momento atual vivido pela economia brasileira, resolvemos verificar dessa vez como o Banco Central reage a um choque cambial. Mais especificamente, vamos verificar se o Banco Central reage a um choque na volatilidade da taxa de câmbio.
Segundo a teoria normativa de política monetária, Bancos Centrais sob regimes de câmbio flutuante devem reagir a choques cambiais^1. Ball (2002), por exemplo, propõe uma regra de Taylor na qual a taxa de juros reage a choques cambiais
![\[r = r_n + e(\pi - \pi^M) + f y + h \varepsilon_3\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-9d75f924c5f30a911a76c5dff31aff5f_l3.png "Rendered by QuickLaTeX.com")
onde  é um choque cambial e
é um choque cambial e  é um parâmetro positivo. Isto é, a taxa de juros deve reagir a choques cambiais temporários que incidem sobre a economia.
é um parâmetro positivo. Isto é, a taxa de juros deve reagir a choques cambiais temporários que incidem sobre a economia.
De modo a verificar se é este o caso em termos empíricos, resolvemos estimar um Modelo Vetor de Correção de Erros (VECM), extraindo do modelo as funções de impulso na volatilidade do câmbio, no desvio da inflação em relação à meta e no hiato do produto e a resposta na taxa de juros SELIC.
De forma a implementar o modelo, coletamos a taxa SELIC, a inflação acumulada em 12 meses medida pelo IPCA, o PIB mensal e a taxa de câmbio R$/US$ diretamente do Banco Central. Ademais, construímos a série de volatilidade do câmbio através da estimação de um modelo GARCH(1,1).
from bcb import sgs # Importar dados do SGS from bcb import Expectativas # Importar dados de Expectativas import pandas as pd # Manipulação de dados import numpy as np # Manipulação e cálculo de dados import statsmodels.api as sm import statsmodels.formula.api as smf from functools import reduce from arch import arch_model from statsmodels.tsa.vector_ar import vecm import seaborn as sns sns.set()
2. Coleta e Tratamento de dados
2.1 Selic
Abaixo, começamos importando a taxa básica de juros que é calibrada pelo Banco Central.
# Selic acumulada no mês anualizada base 252 - Freq. mensal - Unid. % a.a.
selic = sgs.get({'selic' : "4189"}, start = "1999-01-01")
# Trata os dados
selic_m = (
selic
.reset_index()
.assign(date = lambda x: pd.PeriodIndex(x['Date'], freq = 'M'))
.loc[:, ['date', 'selic']]
)
| date | selic | |
|---|---|---|
| 0 | 1999-01 | 31.19 |
| 1 | 1999-02 | 38.97 |
| 2 | 1999-03 | 43.25 |
| 3 | 1999-04 | 36.12 |
| 4 | 1999-05 | 27.11 |
| ... | ... | ... |
| 292 | 2023-05 | 13.65 |
| 293 | 2023-06 | 13.65 |
| 294 | 2023-07 | 13.65 |
| 295 | 2023-08 | 13.19 |
| 296 | 2023-09 | 12.97 |
297 rows × 2 columns
2.2 Criar desvio entre inflação esperada e meta de inflação
Vamos importar e tratar as expectativas e meta de inflação.
2.2.1 Expectativa de Inflação
# Instância a classe de Expectativas
em = Expectativas()
# Obtém o endpoint da Expectativa de Inflação Acumulada em 12 meses
exp_ipca_raw = em.get_endpoint('ExpectativasMercadoInflacao12Meses')
# Expectativa média do IPCA - tx. acumulada para os próximos 12 meses (Expectativas)
ipca_expec_12m_raw = (
exp_ipca_raw.query()
.filter(exp_ipca_raw.Suavizada == 'S',
exp_ipca_raw.baseCalculo == 0,
exp_ipca_raw.Indicador == 'IPCA')
.collect()
)
# Muda o tipo da coluna de data para date time e period, renomeia as colunas e seleciona a coluna dos valores
ipca_expec_12m = (
ipca_expec_12m_raw
.assign(date = lambda x: pd.PeriodIndex(x['Data'], freq = 'M'))
.loc[:, ['date', 'Mediana']]
.groupby(by = 'date')
.agg(ipca_exp_12m = ('Mediana', 'mean'))
.reset_index()
)
ipca_expec_12m
| date | ipca_exp_12m | |
|---|---|---|
| 0 | 2001-12 | 5.030000 |
| 1 | 2002-01 | 4.733636 |
| 2 | 2002-02 | 4.644737 |
| 3 | 2002-03 | 4.721500 |
| 4 | 2002-04 | 4.790000 |
| ... | ... | ... |
| 257 | 2023-05 | 4.928914 |
| 258 | 2023-06 | 4.328971 |
| 259 | 2023-07 | 4.194614 |
| 260 | 2023-08 | 4.150861 |
| 261 | 2023-09 | 4.078585 |
262 rows × 2 columns
2.2.2 Meta de Inflação
# Meta para a inflação - CMN - Freq. anual - %
meta = sgs.get({'meta' : "13521"}, start = "1999-01-01")
# Mensaliza a série
meta_m = (
meta
.loc[np.repeat(meta.index.values, 12)]
.reset_index()
.assign(date = lambda x: pd.date_range(start = x['Date'].iloc[0],
periods = len(x),
freq = 'M').to_period('M')
)
.loc[:, ['date', 'meta']]
)
# Expandindo amostra com dados de meta futura de inflação
new_rows = pd.DataFrame({
'date': pd.date_range(start = '2022-01-01', periods = 24*3, freq = 'M').to_period('M'),
'meta': np.repeat([3.5, 3.25, 3, 3, 3, 3], 12)
})
# Junta as metas
meta_inflacao = pd.concat([meta_m, new_rows]).drop_duplicates(subset = "date")
meta_inflacao
| date | meta | |
|---|---|---|
| 0 | 1999-01 | 8.0 |
| 1 | 1999-02 | 8.0 |
| 2 | 1999-03 | 8.0 |
| 3 | 1999-04 | 8.0 |
| 4 | 1999-05 | 8.0 |
| ... | ... | ... |
| 67 | 2027-08 | 3.0 |
| 68 | 2027-09 | 3.0 |
| 69 | 2027-10 | 3.0 |
| 70 | 2027-11 | 3.0 |
| 71 | 2027-12 | 3.0 |
348 rows × 2 columns
2.2.3 Hiato
O hiato do produto é uma medida que compara o Produto Interno Bruto (PIB) efetivo de uma economia com seu PIB potencial. Ele é usado para avaliar a diferença entre a produção real da economia e sua capacidade de produção a longo prazo. O hiato do produto pode ser expresso na seguinte equação:
![\[\text{Hiato do Produto} = \frac{(\text{PIB Efetivo} - \text{PIB Potencial})}{\text{PIB Potencial}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-30c90f0e494e630564fe5d7d5e6967fd_l3.png "Rendered by QuickLaTeX.com")
Onde:
- **PIB Efetivo**: Refere-se ao Produto Interno Bruto real ou observado da economia em um determinado período de tempo.
- **PIB Potencial**: É uma estimativa da produção máxima sustentável da economia a longo prazo. Representa a capacidade máxima de produção da economia quando todos os recursos estão plenamente empregados, sem gerar pressões inflacionárias.
O hiato do produto é uma medida importante, pois indica se a economia está operando acima ou abaixo de sua capacidade máxima. Um hiato positivo (quando o PIB efetivo está acima do PIB potencial) pode sugerir pressões inflacionárias, enquanto um hiato negativo (quando o PIB efetivo está abaixo do PIB potencial) pode indicar subutilização de recursos e desemprego.
Para obter o PIB Potencial, aplicamos um Filtro HP sobre a série do PIB Mensal da FGV.
# Coleta os dados do PIB Mensal (FGV)
pib = (
pd.read_csv("https://aluno.analisemacro.com.br/download/53783/?tmstv=1692063478",
sep = ";",
parse_dates = ["data"],
decimal = ',')
.assign(date = lambda x: pd.PeriodIndex(x['data'], freq = 'M'))
.drop(['data'], axis = 1)
)
# Calcula o filtro HP
filtro_hp = sm.tsa.filters.hpfilter(x = pib['pib'], lamb = 129600)
# Salva a tendência calculada
potencial_hp = filtro_hp[1] # posição 1 é a tendência (0=ciclo);
# Calcula o Hiato
pib["hiato"] = (pib["pib"] / potencial_hp - 1) * 100
# Seleciona as colunas
hiato = pib[['date', 'hiato']]
hiato
| date | hiato | |
|---|---|---|
| 0 | 2000-01 | 0.262123 |
| 1 | 2000-02 | 0.495858 |
| 2 | 2000-03 | 0.361250 |
| 3 | 2000-04 | -0.414069 |
| 4 | 2000-05 | 0.916502 |
| ... | ... | ... |
| 278 | 2023-03 | 4.740716 |
| 279 | 2023-04 | 3.823408 |
| 280 | 2023-05 | 1.193390 |
| 281 | 2023-06 | 1.612139 |
| 282 | 2023-07 | 1.091752 |
2.2.4 Volatilidade do Câmbio
Para a volatilidade do Câmbio, usamos um modelo GARCH(1,1).
Um modelo GARCH(1,1) (Generalized Autoregressive Conditional Heteroskedasticity) é uma forma de modelar a volatilidade condicional em séries temporais financeiras. A equação geral para um modelo GARCH(1,1) pode ser representada da seguinte forma:
![\[y_t = \mu + \epsilon_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-5c7fd4c89b4ccc55105bfd45b942d5e6_l3.png "Rendered by QuickLaTeX.com")
![\[\epsilon_t = \sigma_t \cdot z_t\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d377dcd34f4d8d7e7804d5eef7e3900d_l3.png "Rendered by QuickLaTeX.com")
![\[\sigma_t^2 = \alpha_0 + \alpha_1 \cdot \epsilon_{t-1}^2 + \beta_1 \cdot \sigma_{t-1}^2\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-4405e74c3564428a034773f21c54d8f5_l3.png "Rendered by QuickLaTeX.com")
Onde:
-  é o valor observado na data
é o valor observado na data  .
.
-  é a média condicional da série temporal.
é a média condicional da série temporal.
-  é o erro condicional na data , assumindo que é um ruído branco com média zero (
é o erro condicional na data , assumindo que é um ruído branco com média zero (![E[\epsilon_t] = 0](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-02a5c1c04985c747edc481becb07c9b6_l3.png "Rendered by QuickLaTeX.com") ).
).
-  é a volatilidade condicional na data .
é a volatilidade condicional na data .
-  é uma variável aleatória independente e identicamente distribuída com média zero e variância um (
é uma variável aleatória independente e identicamente distribuída com média zero e variância um ( ).
).
-  ,
,  , e
, e  são parâmetros do modelo GARCH(1,1) que precisam ser estimados.
são parâmetros do modelo GARCH(1,1) que precisam ser estimados.
As suposições e restrições típicas associadas a um modelo GARCH(1,1) incluem:
1. Séries Temporais Estacionárias: O modelo assume que a série temporal é estacionária, o que significa que a média e a variância condicionais são constantes ao longo do tempo. Se a série não for estacionária, pode ser necessário aplicar diferenciação ou transformações para torná-la estacionária.
2. Erros Condicionais Independentes e Identicamente Distribuídos: Os erros são assumidos como ruído branco, o que significa que são independentes entre si e têm a mesma distribuição, com média zero e variância constante.
3. Condições de Positividade: Os parâmetros , , e devem satisfazer condições de positividade para garantir que a volatilidade condicional seja não negativa.
4. Condição de Estacionariedade: Para que o modelo seja estável, é necessário que  . Isso garante que a série temporal seja estacionária no sentido fraco.
. Isso garante que a série temporal seja estacionária no sentido fraco.
Vamos aplicar o GARCH(1,1) para série de primeira diferença com transformação logarítmica do Câmbio R mensal.
mensal.
# Captura os dados
cambio = sgs.get({'cambio' : 3697}, start = '2000-01-01')
# Diferencia o log preço do câmbio
dcambio = np.log(cambio['cambio']).diff().dropna()
# Específica o GARCH(1,1) com média constante e distribuição normal
cambio_gm = arch_model(dcambio, p = 1, q = 1,
mean = 'constant', vol = 'GARCH', dist = 'normal')
# ajusta o modelo
cambio_result = cambio_gm.fit(disp = 'off')
# Cria df da volatilidade condicional
vol_cambio = (
pd.DataFrame(cambio_result.conditional_volatility)
.assign(date = lambda x: pd.PeriodIndex(x.index, freq = 'M'))
.reset_index(drop = True)
)
vol_cambio
| cond_vol | date | |
|---|---|---|
| 0 | 0.037455 | 2000-02 |
| 1 | 0.030393 | 2000-03 |
| 2 | 0.031025 | 2000-04 |
| 3 | 0.030221 | 2000-05 |
| 4 | 0.036525 | 2000-06 |
| ... | ... | ... |
| 278 | 0.028807 | 2023-04 |
| 279 | 0.038026 | 2023-05 |
| 280 | 0.028898 | 2023-06 |
| 281 | 0.033523 | 2023-07 |
| 282 | 0.029215 | 2023-08 |
283 rows × 2 columns
2.4 Reunir os dados
# lista de dataframes dados_list = [selic_m, ipca_expec_12m, meta_inflacao, hiato, vol_cambio] # reduz os dataframes pela chave 'date_quarter' com left join dados = reduce(lambda left, right: pd.merge(left, right, on = 'date', how = 'outer'), dados_list)
2.5 Cria desvio
# cria as colunas com os lags e leads dados['desvio'] = dados['ipca_exp_12m'] - dados['meta'].shift(-4) # remove as linhas com valores ausentes dados = dados.drop(['ipca_exp_12m', 'meta'], axis = 1).dropna() dados
| date | selic | hiato | cond_vol | desvio | |
|---|---|---|---|---|---|
| 35 | 2001-12 | 19.05 | -0.572986 | 0.058307 | 1.530000 |
| 36 | 2002-01 | 19.05 | -0.453490 | 0.058082 | 1.233636 |
| 37 | 2002-02 | 18.97 | 0.883944 | 0.029587 | 1.144737 |
| 38 | 2002-03 | 18.72 | -1.353828 | 0.030819 | 1.221500 |
| 39 | 2002-04 | 18.38 | -0.632865 | 0.035092 | 1.290000 |
| ... | ... | ... | ... | ... | ... |
| 290 | 2023-03 | 13.65 | 4.740716 | 0.028491 | 2.188104 |
| 291 | 2023-04 | 13.65 | 3.823408 | 0.028807 | 1.958222 |
| 292 | 2023-05 | 13.65 | 1.193390 | 0.038026 | 1.678914 |
| 293 | 2023-06 | 13.65 | 1.612139 | 0.028898 | 1.078971 |
| 294 | 2023-07 | 13.65 | 1.091752 | 0.033523 | 0.944614 |
260 rows × 5 columns
Construindo o modelo
Utilizamos o teste de Johansen, por meio da função select_coint_rank. Em seus parâmetros, definimos as variáveis, o termo determinístico (-1 sem termo; 0 para constante; 1 para linear), o número de diferenças defasadas e o método a ser utilizado pelo teste, trace e maxeig.
O Teste vai determinar o número de vetores de cointegração ou relações de cointegração (r). O modelo VECM é utilizado quando os vetores de cointegração são maiores que 0 e menores que o número de variáveis no modelo (K).
0 < r < K; aplicar VECM
No nosso exemplo (onde K = 7), a aplicação do VECM é apropriada se o r seja o valor de 2, 3, 4, 5 e 6, pois isso satisfaz a condição acima 0 < r < K (ou seja, 0 < r < 7).
O teste pode ser realizado usando tanto a estatística de Traço (Trace statistic) quanto a estatística do Autovalor Máximo (Maximum Eigenvalue statistic) para testar as seguintes hipóteses:
- Hipótese Nula (H0): Não existe cointegração entre as variáveis (r = 0).
- Hipótese Alternativa (H1): Existe pelo menos uma relação de cointegração entre as variáveis (r > 0).
O teste de cointegração de Johansen avalia se a estatística de teste excede o valor crítico para rejeitar a hipótese nula e inferir a presença de cointegração entre as variáveis.
dados.set_index("date", inplace = True)
johansen_trace = vecm.select_coint_rank(dados, det_order = 0, k_ar_diff = 1, method = "trace")
johansen_maxeig = vecm.select_coint_rank(dados, det_order = 0, k_ar_diff = 1, method = "maxeig")
print(johansen_trace)
print(johansen_maxeig)
Código
Johansen cointegration test using trace test statistic with 5% significance level
=====================================
r_0 r_1 test statistic critical value
-------------------------------------
0 4 182.3 47.85
1 4 70.83 29.80
2 4 36.96 15.49
3 4 5.829 3.841
-------------------------------------
Johansen cointegration test using maximum eigenvalue test statistic with 5% significance level
=====================================
r_0 r_1 test statistic critical value
-------------------------------------
0 1 111.4 27.59
1 2 33.87 21.13
2 3 31.13 14.26
3 4 5.829 3.841
-------------------------------------
Cada linha da tabela resultante mostra um teste com:
- Hipótese nula: “O rank de cointegração é r_0”
- Hipótese alternativa: “O rank de cointegração é maior que r_0 e r_1”.
A última linha contém informações sobre o rank de cointegração a ser escolhido. Se a estatística de teste dessa linha for menor que o valor crítico correspondente, utiliza-se r_0 como o rank de cointegração. Caso contrário, utiliza-se r_1.
Essa informação é relevante para determinar o número de vetores de cointegração adequados para o modelo. Se o teste estatístico para r_0 for estatisticamente significativo, indica que o número de vetores de cointegração é pelo menos r_0. Por outro lado, se o teste para r_1 for significativo, indica que o número de vetores de cointegração é maior que r_0 e r_1.
A partir das tabelas acima, chegamos a conclusão que r_1 = 4. Isso pode ser obtido usando a propriedade rank.
johansen_trace.rank johansen_maxeig.rank
4
Determinado a ordem de cointegração, devemos obter a ordem de defasagem. Fazemos isso por meio da função select_order. Como parâmetros da função, temos os dados, o máximo de defasagens e o termo determínistico.
Entre as escolhas do último, temos:
“N” - sem termos determinísticos
“co” - constante fora da relação de cointegração
“ci” - constante dentro da relação de cointegração
“lo” - tendência linear fora da relação de cointegração
“li” - tendência linear dentro da relação de cointegração
lag_order = vecm.select_order(data = dados, maxlags = 4, deterministic = "ci") lag_order.selected_orders
Código
{'aic': 2, 'bic': 1, 'hqic': 2, 'fpe': 2}Para ajustar um modelo VECM aos dados, primeiro criamos um objeto VECM no qual definimos:
Os termos determinísticos
A ordem de defasagem (lag order)
O rank de cointegração
adicionamos possíveis dummies sazonais
vecm_modelo = vecm.VECM(dados, deterministic = "ci", k_ar_diff = lag_order.bic, # = 1 coint_rank = johansen_maxeig.rank, dates = dados.index) vecm_res = vecm_modelo.fit() print(vecm_res.summary())
Código
Det. terms outside the coint. relation & lagged endog. parameters for equation selic
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
L1.selic 0.7135 0.046 15.604 0.000 0.624 0.803
L1.hiato -0.0048 0.015 -0.314 0.754 -0.035 0.025
L1.cond_vol -0.6275 1.486 -0.422 0.673 -3.540 2.285
L1.desvio 0.1706 0.054 3.135 0.002 0.064 0.277
Det. terms outside the coint. relation & lagged endog. parameters for equation hiato
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
L1.selic 0.1065 0.186 0.574 0.566 -0.258 0.471
L1.hiato 0.1564 0.063 2.502 0.012 0.034 0.279
L1.cond_vol 4.5426 6.037 0.752 0.452 -7.290 16.375
L1.desvio 0.0584 0.221 0.264 0.792 -0.375 0.492
Det. terms outside the coint. relation & lagged endog. parameters for equation cond_vol
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
L1.selic 0.0036 0.002 1.823 0.068 -0.000 0.007
L1.hiato -0.0008 0.001 -1.185 0.236 -0.002 0.001
L1.cond_vol 0.1172 0.064 1.821 0.069 -0.009 0.243
L1.desvio 0.0007 0.002 0.288 0.774 -0.004 0.005
Det. terms outside the coint. relation & lagged endog. parameters for equation desvio
===============================================================================
coef std err z P>|z| [0.025 0.975]
-------------------------------------------------------------------------------
L1.selic 0.1592 0.048 3.291 0.001 0.064 0.254
L1.hiato 0.0096 0.016 0.592 0.554 -0.022 0.042
L1.cond_vol -0.5190 1.573 -0.330 0.741 -3.602 2.564
L1.desvio 0.4446 0.058 7.719 0.000 0.332 0.557
Loading coefficients (alpha) for equation selic
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0091 0.004 -2.130 0.033 -0.017 -0.001
ec2 0.0247 0.010 2.556 0.011 0.006 0.044
ec3 1.7166 1.793 0.958 0.338 -1.797 5.230
ec4 0.0161 0.019 0.838 0.402 -0.022 0.054
Loading coefficients (alpha) for equation hiato
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0187 0.017 -1.077 0.282 -0.053 0.015
ec2 -0.2159 0.039 -5.493 0.000 -0.293 -0.139
ec3 -16.3386 7.283 -2.244 0.025 -30.612 -2.065
ec4 0.0159 0.078 0.203 0.839 -0.137 0.169
Loading coefficients (alpha) for equation cond_vol
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 6.325e-05 0.000 0.342 0.732 -0.000 0.000
ec2 -0.0007 0.000 -1.604 0.109 -0.001 0.000
ec3 -0.7582 0.078 -9.765 0.000 -0.910 -0.606
ec4 0.0001 0.001 0.180 0.857 -0.001 0.002
Loading coefficients (alpha) for equation desvio
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 0.0069 0.005 1.530 0.126 -0.002 0.016
ec2 0.0146 0.010 1.426 0.154 -0.005 0.035
ec3 3.5379 1.897 1.865 0.062 -0.181 7.256
ec4 -0.1039 0.020 -5.112 0.000 -0.144 -0.064
Cointegration relations for loading-coefficients-column 1
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 1.0000 0 0 0.000 1.000 1.000
beta.2 -1.672e-17 0 0 0.000 -1.67e-17 -1.67e-17
beta.3 -6.331e-16 0 0 0.000 -6.33e-16 -6.33e-16
beta.4 3.902e-16 0 0 0.000 3.9e-16 3.9e-16
const -11.3453 1.989 -5.705 0.000 -15.243 -7.448
Cointegration relations for loading-coefficients-column 2
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 1.921e-17 0 0 0.000 1.92e-17 1.92e-17
beta.2 1.0000 0 0 0.000 1.000 1.000
beta.3 3.366e-16 0 0 0.000 3.37e-16 3.37e-16
beta.4 -1.168e-16 0 0 0.000 -1.17e-16 -1.17e-16
const 0.0108 0.308 0.035 0.972 -0.593 0.615
Cointegration relations for loading-coefficients-column 3
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 -8.837e-20 0 0 0.000 -8.84e-20 -8.84e-20
beta.2 6.682e-19 0 0 0.000 6.68e-19 6.68e-19
beta.3 1.0000 0 0 0.000 1.000 1.000
beta.4 8.144e-19 0 0 0.000 8.14e-19 8.14e-19
const -0.0371 0.001 -33.734 0.000 -0.039 -0.035
Cointegration relations for loading-coefficients-column 4
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 -5.207e-18 0 0 0.000 -5.21e-18 -5.21e-18
beta.2 -1.211e-17 0 0 0.000 -1.21e-17 -1.21e-17
beta.3 1.882e-16 0 0 0.000 1.88e-16 1.88e-16
beta.4 1.0000 0 0 0.000 1.000 1.000
const -0.7770 0.264 -2.938 0.003 -1.295 -0.259
==============================================================================Função Impulso Resposta
Agora precisamos verificar o choque de uma unidade do desvio padrão da volatilidade do câmbio sobre a taxa selic. Para tanto, utilizamos a função de impulso resposta e verificamos o resultado na figura abaixo.
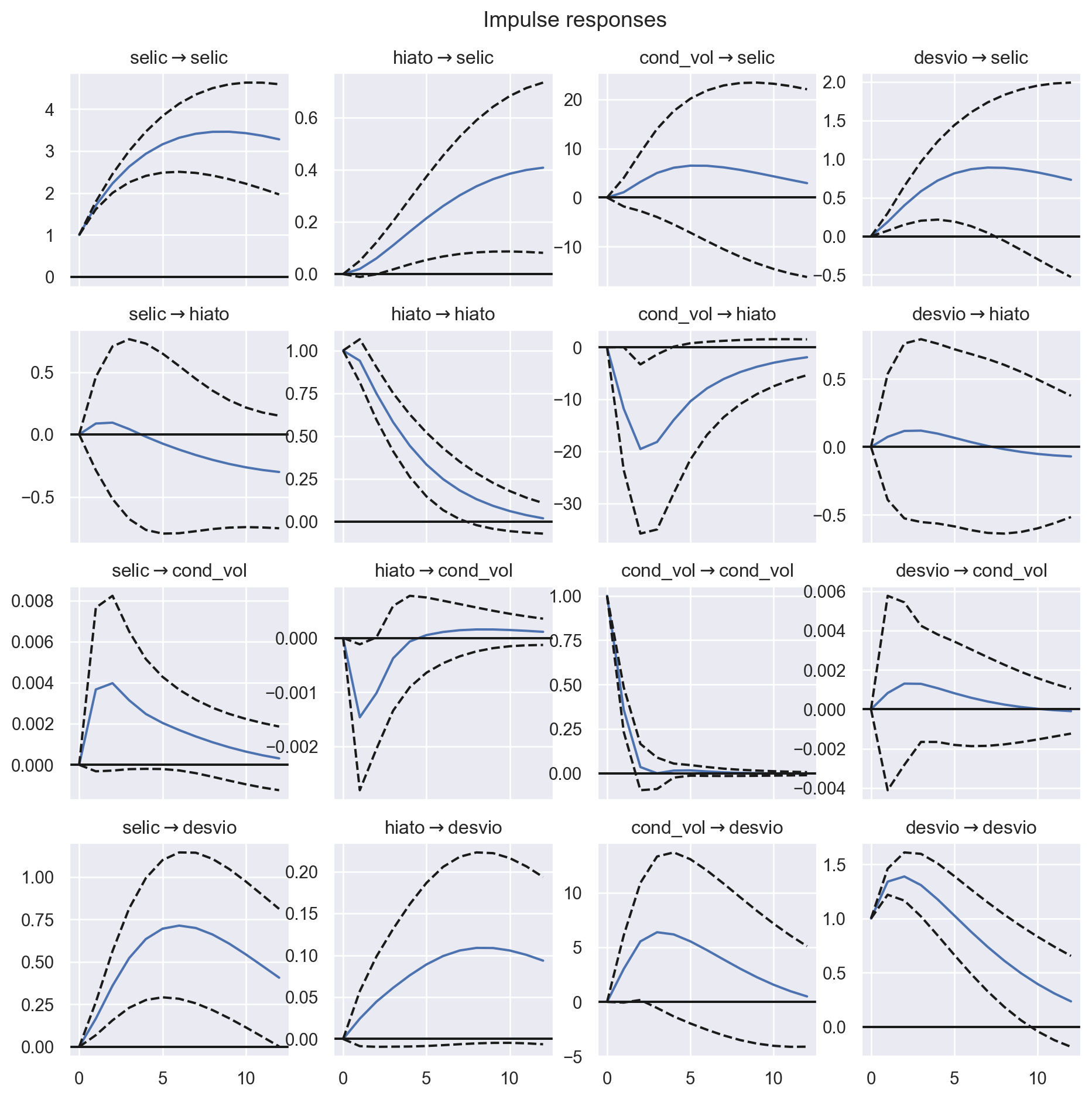 Temos que um choque na volatilidade condicional do câmbio afeta positivamente o valor da Selic.
Temos que um choque na volatilidade condicional do câmbio afeta positivamente o valor da Selic.
Referências
Notas de rodapé
- Ver, por exemplo, Licha (2015) e Obstfeld e Rogoff (1995).
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

