[et_pb_section bb_built="1" admin_label="section"][et_pb_row admin_label="row" background_position="top_left" background_repeat="repeat" background_size="initial"][et_pb_column type="1_2"][et_pb_text text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" background_position="top_left" background_repeat="repeat" background_size="initial" _builder_version="3.17.5"]
Na seção 14 do nosso curso de Construção de Cenários e Previsões usando o R, ensinamos os alunos a construir previsões combinadas de diversos modelos. É bastante consensual na literatura de que previsões combinadas tendem a ser melhores do que previsões individuais, uma vez que elas podem incorporar as características de diversos modelos. Com base nesse pressuposto, na edição 53 do Clube do Código construímos uma previsão combinada para a taxa de desemprego brasileira, medida pela PNAD Contínua, com base no EQM de três modelos: SARIMA, Filtro de Kalman e BVAR. Os resultados encontrados corroboram com a literatura, como resumo nesse post.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image src="https://analisemacro.com.br/wp-content/uploads/2019/03/cursosder.png" url="https://analisemacro.com.br/cursos-de-r/" align="center" use_border_color="off" _builder_version="3.17.5"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row" background_position="top_left" background_repeat="repeat" background_size="initial"][et_pb_column type="4_4"][et_pb_text text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" background_position="top_left" background_repeat="repeat" background_size="initial" _builder_version="3.17.5"]
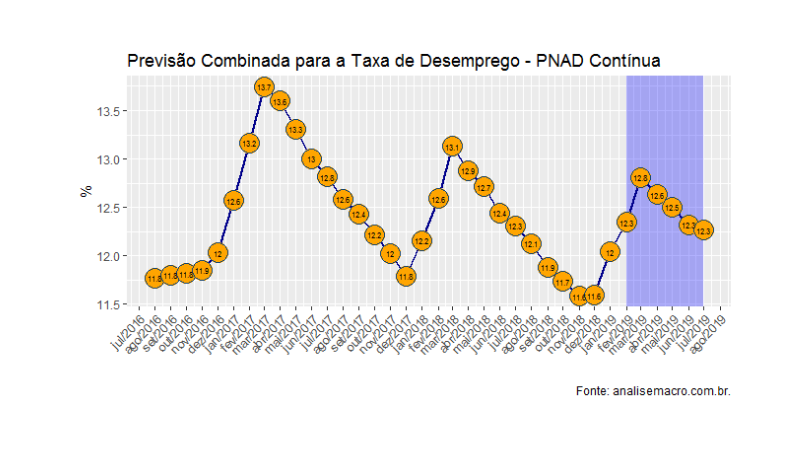
Para o exercício, pegamos uma amostra que vai de março de 2013 a janeiro de 2019. De forma a construir o EQM, dividimos a amostra em duas, uma para gerar os modelos e outra para o gerar as previsões. Abaixo uma tabela que compara algumas métricas de avaliação dos três modelos estimados.
| ME | RMSE | MAE | MPE | MAPE | ACF1 | Theil's U | |
|---|---|---|---|---|---|---|---|
| SARIMA | 0.28 | 0.38 | 0.28 | 2.41 | 2.41 | 0.51 | 1.70 |
| Kalman | -0.11 | 0.17 | 0.15 | -0.95 | 1.26 | 0.42 | 0.70 |
| BVAR | 0.22 | 0.42 | 0.24 | 1.86 | 1.98 | 0.25 | 1.89 |
| Combinada | -0.07 | 0.17 | 0.16 | -0.56 | 1.33 | 0.40 | 0.71 |
De fato, as previsões combinadas são as que possuem os menores erros, por praticamente todas as métricas de avaliação. Abaixo, para ilustrar, colocamos as previsões para seis meses dos três modelos e a combinação entre eles feita pelo inverso do EQM.
| SARIMA | Kalman | BVAR | Combinada | |
|---|---|---|---|---|
| 2019 Feb | 12.6 | 12.4 | 11.9 | 12.3 |
| 2019 Mar | 13.1 | 13.0 | 11.8 | 12.8 |
| 2019 Apr | 12.9 | 12.8 | 11.8 | 12.6 |
| 2019 May | 12.6 | 12.6 | 11.7 | 12.5 |
| 2019 Jun | 12.3 | 12.4 | 11.5 | 12.3 |
| 2019 Jul | 12.1 | 12.4 | 11.4 | 12.3 |
O exercício está disponível no repositório privado do Clube do Código no github.
_____________________________________
Conheça nossos Cursos Aplicados de R e aprenda a coletar, tratar, analisar e apresentar dados com o R!
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]

