[et_pb_section admin_label="section"][et_pb_row admin_label="row"][et_pb_column type="1_2"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
A edição 51 do Clube do Código, titulada Tratando dados previdenciários com o R, que foi parcialmente publicada aqui no blog, ensina a coletar e tratar dados agregados de receita e despesa do INSS - é, a propósito, o tipo de coisa que fazemos em nosso Curso de Analise de Conjuntura usando o R. Lá também construímos um modelo univariado SARIMA de previsão para o gasto previdenciário, baseado na metodologia Box-Jenkins - saiba como construir modelos univariados em nosso Curso de Séries Temporais usando o R. O objetivo do exercício é ter uma ideia sobre a evolução do gasto previdenciário em 2019.
[/et_pb_text][/et_pb_column][et_pb_column type="1_2"][et_pb_image admin_label="Imagem" src="https://analisemacro.com.br/wp-content/uploads/2019/02/loteextra2.png" show_in_lightbox="off" url="https://analisemacro.com.br/cursos-de-r/" url_new_window="off" use_overlay="off" animation="off" sticky="off" align="center" force_fullwidth="off" always_center_on_mobile="on" use_border_color="off" border_color="#ffffff" border_style="solid"]
[/et_pb_image][/et_pb_column][/et_pb_row][et_pb_row admin_label="row"][et_pb_column type="4_4"][et_pb_text admin_label="Texto" background_layout="light" text_orientation="justified" text_font="Verdana||||" text_font_size="18" use_border_color="off" border_color="#ffffff" border_style="solid"]
Como vimos no post sobre tratamento de dados previdenciários, os gastos do INSS apresentam uma tendência positiva de crescimento ao longo do tempo, além de uma sazonalidade bastante pronunciada. Certamente, por suposto, não é um processo estacionário - veja mais aqui. O tratamento inicial, de acordo com a metodologia Box-Jenkins, é tornar a série estacionária, modelando a mesma em seguida.
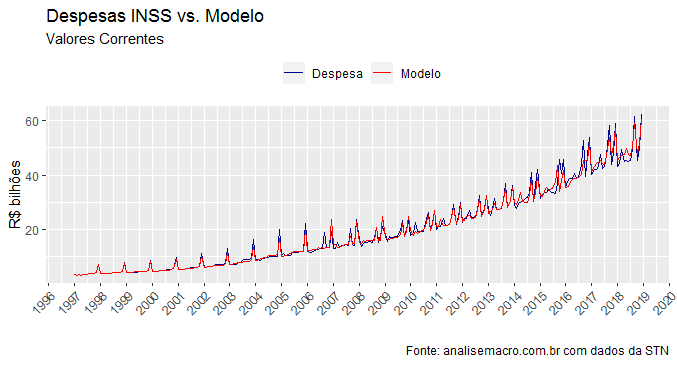
Na edição 51 do Clube do Código, por suposto, utilizamos a função auto.arima do pacote forecast de modo a gerar "o melhor modelo" univariado para o gasto previdenciário de acordo com critérios de informação. O resultado foi um modelo ![ARIMA(0,1,3)(0,1,1)[12]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-2bdee9d20f870a8551fda5b0aea6c06e_l3.png "Rendered by QuickLaTeX.com") . O gráfico abaixo compara o ajuste desse modelo com a série original.
. O gráfico abaixo compara o ajuste desse modelo com a série original.
Com base nesse modelo, geramos uma previsão para 2019. O gráfico abaixo ilustra para três diferentes intervalos de confiança.

As previsões médias do modelo indicam que o gasto previdenciário será de R$ 625,2 bilhões em 2019, variando entre R$ 583,1 bilhões e R$ 667,4 bilhões, ao considerar um intervalo de 95% de confiança. Em termos comparativos, o PLDO 2019 estima o gasto do INSS em R$ 635,4 bilhões. Em outras palavras, pelo nosso modelo, o gasto deve aumentar algo como R$ 38,9 bilhões esse ano, em valores correntes, se comparado a 2018, seguindo a trajetória ascendente.
Para terminar, uma provocação. Dissemos acima que o gasto previdenciário não performa como um processo estacionário. O que isso significa? Significa dizer que o gasto segue, pelo contrário, um processo explosivo de crescimento. Isto é, a tendência é que ele cresça indefinidamente ao longo do tempo, caso nada seja feito - saiba mais em nosso Curso de Séries Temporais usando o R. Justamente por isso é importante que seja feita alguma reforma no sistema de previdência, caso contrário essa rubrica avançará sobre todos os outros gastos do governo ao longo do tempo.
O pdf completo estará disponível no Clube do Código na próxima semana!
_____________________________________
Conheça nossos Cursos Aplicados de R e aprenda a coletar, tratar, analisar e apresentar dados com o R!
[/et_pb_text][/et_pb_column][/et_pb_row][/et_pb_section]

