O leitor desse espaço já deve ter percebido que o desemprego tem sido uma grande preocupação por aqui. Com a economia em ritmo de crescimento negativo, não é para menos, não é mesmo? Desse modo, temos produzido alguns posts sobre a situação no mercado de trabalho, para mostrar para você que as coisas não estão nada boas. Infelizmente. Hoje, vamos falar novamente de desemprego e aproveitar o R para automatizar o processo de previsão, dado um conjunto de cenários possíveis. Como? Criando uma função para isso. Interessante, né? Pois é, vamos, lá!
Há alguns meses, um dos autores desse post estava obstinado em tentar gerar previsões mais precisas sobre a taxa de câmbio. Logo ela que serve para humilhar os economistas! Com essa motivação, começamos a conversar sobre como construir possíveis cenários para fazer previsões condicionadas.
A partir daí, o autor viciado em R desse post [Ricardo Lima] decidiu entrar mais sério no assunto. O pacote forecast já possibilita fazer previsões automáticas e, através do input xreg você pode até utilizar variáveis exógenas e, usar novamente esta entrada para usar cenários que você construiu na hora da previsão(*). Já geramos previsão para o desemprego por aqui, inclusive, com esse procedimento.
Então, o processo que temos que seguir quando queremos fazer previsão de modelos ARMAX(**) usando o pacote forecast é o seguinte:
1. Estimar o modelo ARMAX (ou seja, assumimos uma variável endógena e o resto das variáveis entram pelo input xreg);
2. Criar trajetórias, ou cenários, para todas as variáveis exógenas;
3. Fazer a previsão dada as trajetórias que escolhemos;
Ok, simples, mas e aí ? Imagine agora então que eu tenha 12 cenários. Isto é, vou ter que repetir este processo 12 vezes. E se eu quiser ter uma noção de todas as previsões dados todos os cenários ao mesmo tempo, vou ter que salvar as 12 previsões e juntar tudo... Nossa, que bagunça!
Pois é. Como seria bom uma função que fizesse tudo isso e, no final, gerasse um único gráfico...
Foi com esse pensamento que o autor viciado em R desse post [Ricardo Lima] começou o trabalho. Muito, para ser mais precisos, até chegar a algo bastante simples. Os únicos inputs que a função precisa é uma matriz com os dados para a parte de estimação, uma matriz com os cenários para as variáveis exógenas e a ordem do modelo SARIMAX específico que você queira estimar. O resto é tudo automático.
A ordem lógica da função é basicamente essa:
1. Estimar modelo SARIMAX especificado pelo usuário;
2. Estimar modelo SARIMAX automático (função auto.arima);
3. Fazer previsões das variáveis exógenas pelo método loess;
4. Fazer previsões das variáveis exógenas usando auto.arima;
5. Fazer previsões do modelo SARIMAX especificado pelo usuário condicionado aos cenários;
6. Fazer previsões do modelo SARIMAX automático condicionado aos cenários do usuário;
7. Fazer previsões do modelo SARIMAX automático usando as previsões das variáveis exógenas geradas pelo método loess;
8. Fazer previsões do modelo SARIMAX automático usando as previsões das variáveis exógenas geradas pelo auto.arima;
E, para finalizar, gerar um gráfico(***).
A escolha de adicionar os métodos completamente automáticos foi simplesmente para aumentar a amostra de previsões. Isto porque muitas vezes a média de previsões é melhor que a previsão de um só modelo, mesmo que este modelo seja “muito bom”. Abaixo o início da função...
ARMAXscen <- function(data, scenarios,
order=c(0,0,0), seasonal=c(0,0,0),
ggplot=F,
plot.start, xlab, ylab){
Além disso, a função depende muito de como a entrada dos dados é feita. Logo, tenta-se evitar estes problemas de cara impondo algumas restrições. O mais importante sendo o fato de que o número de colunas na matriz de cenários dividido pelo número de variáveis exógenas tem que resultar em um número inteiro. Isto é, para cada cenário temos que ter o mesmo número de variáveis exógenas. Desta forma, tenta-se indicar de maneira clara onde o problema poderia estar.
if (is.ts(data)==FALSE){
return('Dataset not in ts format.')
}else{
if (sum(is.na(data))>0){
return('NA present in dataset.')
}else{
if (ceiling(ncol(scenarios)/ncol(data[,-1])) != floor(ncol(scenarios)/ncol(data[,-1]))){
return('Number of exogenous variables per scenario not right!')
}else{
Assume-se que o número de linhas na matriz de cenários é igual ao número de períodos para previsão (logo é menos uma coisa que o usuário tem que definir) e que a primeira coluna da matriz de dados seja a variável endógena. Logo, ajeita-se os dados para a função e estima-se o primeiro modelo.
N.prev <- nrow(scenarios)
endo <- data[,1]
xreg <- data[,-1]
colnames(xreg) <- colnames(data)[-1]
arimax.user <- Arima(endo,
order=order,
seasonal=seasonal,
xreg=xreg)
E faz-se isso para os demais modelos até que tenhamos um conjunto de previsões, dado um conjunto de cenários. Tudo automatizado. Bem legal, não é mesmo? Pois é. Aplicamos a função, então, para o desemprego dessazonalizado, com uma matriz contendo dois cenários: um razoavelmente otimista e outro nem tanto. Como variáveis exógenas, utilizamos o crescimento interanual da população ocupada e da população economicamente ativa. A tabela abaixo resume as previsões obtidas para os meses de abril a dezembro desse ano, com a última coluna representando a média dessas previsões.
| ETS | ARIMA | AUTO.S1 | AUTO.S2 | USER.S1 | USER.S2 | Mean | |
| Abr/15 | 5,73 | 5,80 | 5,59 | 5,85 | 5,64 | 5,89 | 5,75 |
| Mai/15 | 5,73 | 5,76 | 5,76 | 5,95 | 5,73 | 5,90 | 5,81 |
| Jun/15 | 5,62 | 5,63 | 5,42 | 6,02 | 5,51 | 6,08 | 5,72 |
| Jul/15 | 5,65 | 5,58 | 5,83 | 6,20 | 5,93 | 6,28 | 5,91 |
| Ago/15 | 5,69 | 5,57 | 5,72 | 6,36 | 5,72 | 6,33 | 5,90 |
| Set/15 | 5,59 | 5,49 | 5,61 | 6,37 | 5,63 | 6,36 | 5,84 |
| Out/15 | 5,52 | 5,43 | 5,45 | 6,41 | 5,50 | 6,41 | 5,79 |
| Nov/15 | 5,65 | 5,39 | 5,44 | 6,62 | 5,42 | 6,55 | 5,84 |
| Dez/15 | 5,53 | 5,24 | 5,54 | 6,56 | 5,57 | 6,55 | 5,83 |
E o gráfico...

Dá para ver que dois modelos indicam crescimento do desemprego em 2015, enquanto os demais modelos indicam redução ao longo do ano - no auto.s1 e user.s1 há alguma volatilidade nos meses iniciais da projeção. Os modelos que geram previsões mais pessimistas estão, claro, baseados no cenário pessimista para a população ocupada e para a população economicamente ativa. Um zoom sobre um desses modelos [auto.s2] que traz previsões mais pessimistas é feito abaixo, com os intervalos de confiança.
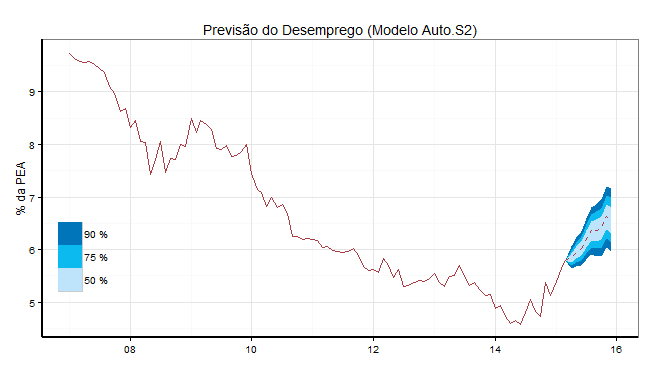
Continuaremos, em assim sendo, preocupados com o desemprego ao longo do ano e publicaremos atualizações das projeções. Com a nova ferramenta em mãos, o trabalho fica cada vez mais fácil, não é mesmo? 🙂
__________________________________________
* Isto porque a funcão só consegue fazer previsão automática da variável endógena.
** Note que, formalmente, não estimamos um modelo ARMAX. Na verdade estimamos um modelo ARMA com uma variável exógena e modelamos as inovações como um processo ARMA. O leitor interessado pode ler mais sobre o assunto neste post do Rob Hyndman.
*** Este foi na verdade o maior desafio dado que o Ricardo Lima colocou na cabeça que iria usar o pacote ggplot2.

