No post anterior, resolvi abrir a caixa preta dos gastos e receitas primárias do governo central. Mostrei ao leitor como pegar os dados do Tesouro e levá-los diretamente para o R. Vimos que os gastos do governo crescem em média próximo a 6% ao ano, em termos reais, o que, se nada for feito, nos levará ao caos em pouco tempo. Ou seja, esse é o maior problema das contas públicas: o gasto não parou de crescer nas últimas décadas. Para continuar nossa análise, vamos aproveitar o script e abrir a despesa primária, olhando um pouco mais de perto como se comportaram os gastos do governo na amostra que temos disponível.
Lembre o leitor que temos um objeto criado no nosso environment do RStudio chamado real12, que traz 73 séries, deflacionadas (a preços de agosto de 2016) e acumuladas em 12 meses. Entre elas, 32 referem-se às despesas do governo central. Nessas despesas primárias estão quatro grandes grupos: gastos com previdência (INSS), gastos com pessoal, outras despesas obrigatórias e despesas discricionárias. Podemos querer saber quanto cada um desses grupos toma em média da despesa primária total e apresentar em termos gráficos. Para isso, rodamos o código abaixo.
despesa <- real12[,c(36:38, 61)]/real12[,35]*100
colnames(despesa) <- c('Previdência', 'Pessoal',
'Outras Despesas Obrigatórias',
'Despesas Discricionárias')
pie(colMeans(despesa), col=c('darkblue', 'red', '367', 'blue'),
main='Distribuição dos gastos do governo central (%)')
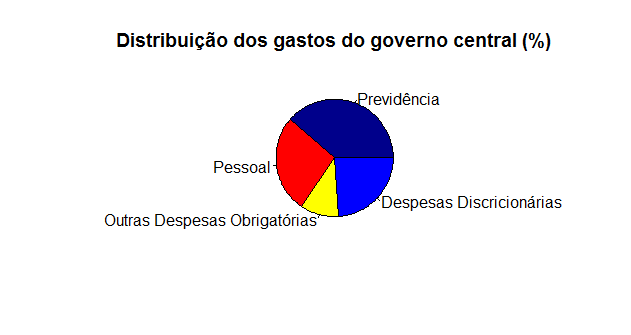
Somados, os gastos do governo central com previdência e pessoal somam, em média, 65.47% da despesa primária total. As outras despesas obrigatórias somam 10.48% e as despesas discricionárias, 24.03%. Ou seja, leitor, a maior parte do gasto do governo central é engessado, i.e., ele não pode simplesmente cortar, caso, por exemplo, a receita de um determinado ano resolva cair, em função do baixo crescimento do PIB.
Nós podemos, inclusive, verificar como esses grandes grupos de despesa primária evoluíram ao longo da nossa amostra. Para tal, vamos ver primeiro a evolução do gasto real, acumulado em 12 meses, dessas rubricas. Estou usando a função autoplot para quem se interessar e o pacote ggthemes para tornar o gráfico um pouco mais apresentável.
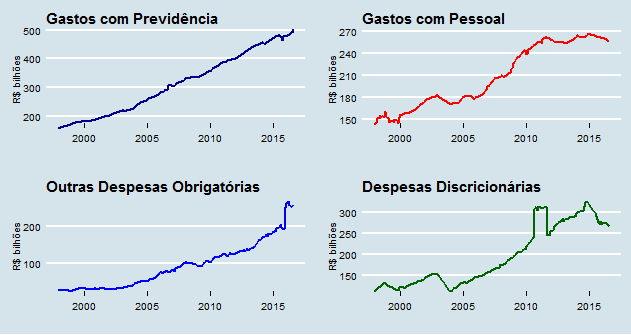
Gastos com previdência e outras despesas obrigatórias mantém uma tendência positiva de crescimento como se não houvesse amanha. Os gastos com pessoal têm se estabilizado no período recente, enquanto a parte que o governo tem algum poder (a tal discricionalidade), parece ser o grande resíduo. Em agosto de 2016, os gastos com previdência somaram R$ 500,9 bilhões, as despesas com pessoal, R$ 256,5 bilhões, as demais despesas obrigatórias, R$ 253,8 bilhões e as despesas discricionárias, R$ 267,3 bilhões.
Podemos agora controlar essa evolução do gasto pelo PIB. Isso é colocado abaixo.
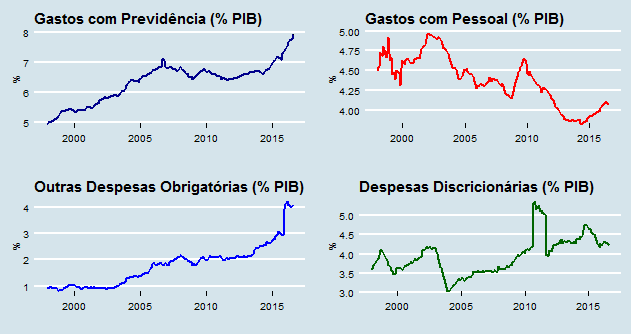
No período recente, influenciado pela forte queda do PIB, previdência, outras despesas obrigatórias e gasto com pessoal apresentam forte elevação. As despesas discricionárias, onde o governo pode fazer algo no curto prazo, há uma queda. Nesse grupo, estão situados gastos de investimento, como o PAC e o Minha Casa Minha Vida. Em outras palavras, leitor, a maior parte do gasto do governo está engessada. Toda vez que o governo se encontra em dificuldades, ele corta justamente em investimento, onde tem algum grau de liberdade.
Significa dizer que, o segundo passo, pós-aprovação da PEC 241, será enfrentar esse engessamento. Será preciso conter o avanço dos gastos com previdência e demais gastos obrigatórios. Ou seja, leitor, o que os dados dizem é que a PEC 241 é só o começo...
_______________________________________________
OBS: TODOS OS CÓDIGOS ESTARÃO DISPONÍVEIS NO CLUBE DO CÓDIGO.

