Introdução
A inflação é um dos principais indicadores da economia, afetando diretamente decisões de consumo, investimentos e políticas públicas. No Brasil, a métrica oficial utilizada é o IPCA (Índice de Preços ao Consumidor Amplo), calculado mensalmente pelo IBGE.
Prever a trajetória da inflação é uma tarefa desafiadora: exige não apenas conhecimento sobre modelos de séries temporais, mas também a capacidade de interpretar choques econômicos, políticas monetárias e fatores globais. Neste contexto, a combinação de Modelos de Linguagem (LLMs) com arquiteturas multiagentes baseadas no LangGraph surge como uma abordagem inovadora, que amplia a precisão e a interpretabilidade do processo de previsão.
LLMs e Previsões de Séries Temporais
Tradicionalmente, previsões de séries temporais em economia utilizam métodos estatísticos bem estabelecidos:
-
ARIMA e SARIMA: indicados para séries estacionárias, capturando tendência e sazonalidade.
-
VAR (Vetores Autorregressivos): capazes de modelar interdependências entre variáveis macroeconômicas, como inflação, juros e câmbio.
-
Modelos ETS (Erro, Tendência, Sazonalidade): úteis quando a série apresenta padrões estruturais bem definidos.
Nos últimos anos, técnicas de Machine Learning passaram a ser aplicadas, como:
-
XGBoost: forte em prever séries com múltiplas variáveis explicativas.
-
Redes neurais recorrentes (LSTM, GRU): eficazes em capturar padrões não lineares e de longo prazo.
O desafio, entretanto, é que não existe um modelo universalmente ótimo. Cada abordagem captura diferentes aspectos do comportamento da série, e muitas vezes a melhor solução é combinar múltiplas visões — algo que analistas humanos fazem intuitivamente.
É exatamente nesse ponto que entram os LLMs e os sistemas multiagentes criados com LangGraph. O exercício apresentado no código mostra essa integração de forma prática:
-
Uso de LLMs como coordenadores: no código, o modelo de linguagem não substitui os métodos estatísticos, mas atua como um supervisor, organizando o fluxo, criando personas e integrando os resultados de diferentes modelos.
-
Criação de personas analíticas: cada persona no exercício foi configurada para simular um analista com perfil específico — por exemplo, um economista tradicional focado em ARIMA, um cientista de dados aplicando ML (como XGBoost) e um especialista quantitativo que interpreta as previsões.
-
Validação sistemática: no código, os agentes realizam previsões sobre o IPCA, e os resultados são comparados em termos de erro médio absoluto (MAE). Esse processo imita a prática real de avaliação de modelos em equipes de pesquisa econômica.
-
Iteração e aprendizado: o LLM atua no papel de “editor” ou “economista chefe”, sintetizando os resultados e garantindo que a previsão final seja consistente, algo que vai além do simples ajuste de modelos estatísticos.
Esse exemplo evidencia que o papel dos LLMs não é apenas gerar texto, mas orquestrar fluxos de decisão em tarefas complexas, integrando métodos econométricos tradicionais e técnicas de machine learning em um sistema unificado.
Criação de Agentes com LangGraph
O LangGraph é um framework que permite estruturar fluxos de trabalho complexos em forma de grafos direcionados, com nós que representam ações e arestas que representam decisões. Isso é particularmente útil em sistemas multiagentes, pois garante:
-
Orquestração clara do processo – cada etapa é visualmente definida.
-
Flexibilidade – fácil adaptação para incluir novos agentes ou etapas.
-
Persistência de estado – memória e contexto preservados ao longo da execução.
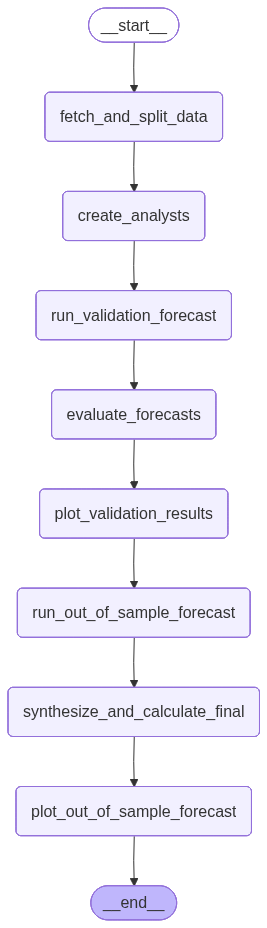
No exercício desenvolvido, o grafo foi estruturado em seis etapas principais:
-
Coleta dos dados: a série histórica do IPCA foi obtida via API do Banco Central.
-
Preparação da base: divisão em dados de treino e teste para validação.
-
Geração das personas: criação de três agentes analistas virtuais.
-
Execução das previsões: cada persona utilizou metodologias diferentes para prever a inflação.
-
Validação cruzada: cálculo do erro médio absoluto (MAE) em dados fora da amostra.
-
Síntese dos resultados: consolidação das previsões em um relatório final.
O grafo abaixo simplifica o processo.
Criação de Personas e Paralelização
Uma das inovações do exercício foi a criação de personas analíticas, ou seja, agentes virtuais com diferentes perfis e metodologias. As três personas criadas foram:
-
O Cientista de Dados: explorou métodos de machine learning, buscando capturar padrões não lineares.
-
O Estatístico/Econometrista: aplicou modelos clássicos de séries temporais, com ênfase em ARIMA e VAR.
-
O Economista Quantitativo: interpretou os resultados à luz da teoria econômica e dos dados macro.
Essas personas trabalharam em paralelo, gerando previsões independentes. Em seguida, os resultados foram comparados com os dados reais e avaliados em termos de erro.
Esse mecanismo de paralelização é extremamente valioso:
-
Reduz o risco de depender de um único modelo.
-
Permite identificar discrepâncias metodológicas.
-
Cria um “painel de previsões”, semelhante ao que bancos centrais e consultorias utilizam no mundo real.
Estudo de Caso: Sistema Multiagente para Previsão da Inflação
No estudo de caso realizado com a série do IPCA, os seguintes passos foram observados:
-
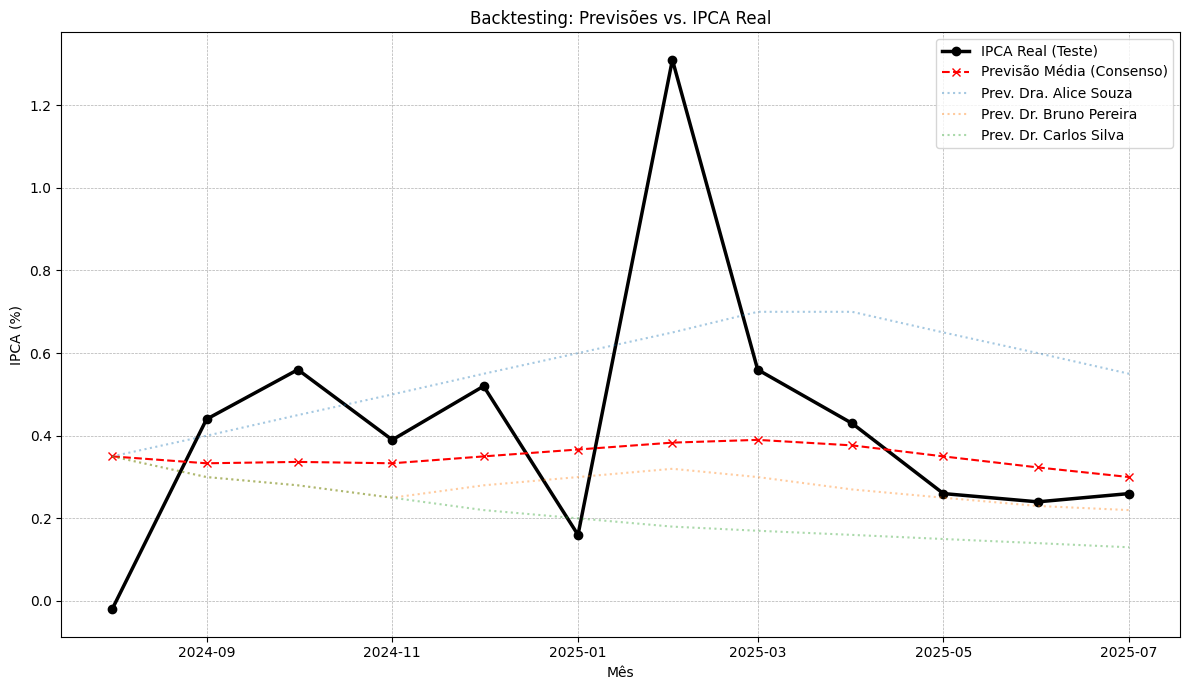
Backtesting: cada persona foi testada em dados de treino e validada em dados de teste, com cálculo do MAE.
-
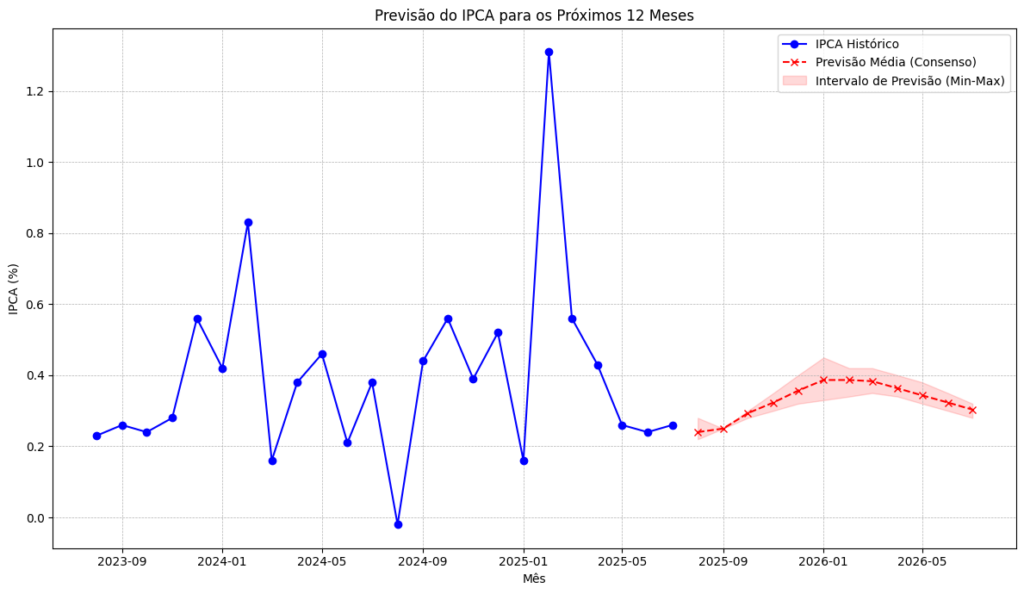
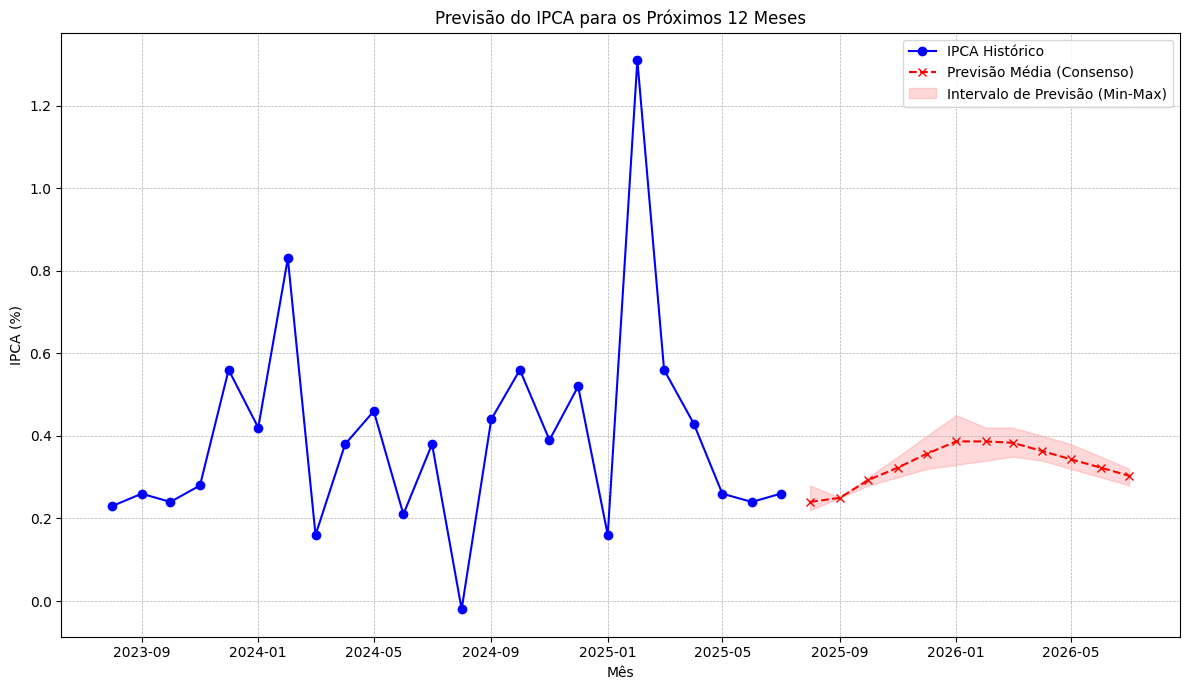
Previsões fora da amostra: foram geradas previsões para os 12 meses seguintes, permitindo comparar cenários de curto prazo.
-
Relatório executivo: um agente adicional, o Economista Chefe, sintetizou os resultados em uma análise final, discutindo não apenas os números, mas também o contexto econômico.
-
Visualização gráfica: foram produzidos gráficos comparando a série observada, as previsões individuais, a média de consenso e o intervalo de incerteza.
Esse processo resultou em uma análise quantitativa e qualitativa, simulando o trabalho de uma equipe de economistas.
O resultado do processo pode ser observado a seguir. É importante destacar que a atuação dos modelos de linguagem ainda apresenta limitações e, portanto, em um exercício simples como o deste exemplo, os resultados devem ser interpretados como uma demonstração metodológica. Para aplicações reais, seriam necessários ajustes adicionais e validações mais robustas.
Conclusão
A utilização do LangGraph em conjunto com LLMs e sistemas multiagentes mostrou-se uma estratégia poderosa para previsão de séries temporais. No caso do IPCA, foi possível:
-
Criar um sistema autônomo, capaz de coletar dados, rodar previsões e avaliar erros.
-
Explorar diferentes metodologias de forma paralela e comparativa.
-
Produzir relatórios explicativos, integrando números e interpretações.
Essa abordagem não substitui o trabalho de um analista humano, mas serve como um apoio fundamental, automatizando tarefas repetitivas e oferecendo múltiplas perspectivas de forma rápida.
No futuro, estruturas semelhantes poderão ser aplicadas não apenas a inflação, mas também a indicadores como desemprego, produção industrial, balança comercial e expectativas de mercado — ampliando o uso de IA como ferramenta estratégica em macroeconomia.
_____________
Saiba mais
Quer aprender a construir Agentes de IA que criam modelos para previsão macro? Participe da nossa mais nova Imersão Como Criar um Agente de IA Econometrista clicando aqui.

