Introdução
Nos últimos anos, a Recuperação Aumentada por Geração (RAG) tornou-se uma técnica fundamental para sistemas de IA que combinam busca de informações e geração de texto. Mas, quando adicionamos elementos “agentic”, ou seja, a capacidade do sistema decidir de forma autônoma como buscar, filtrar e processar dados, entramos no universo do Agentic CRAG (Corrective RAG), uma abordagem que combina recuperação, avaliação e correção dinâmica das respostas.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Neste artigo, exploramos como foi possível implementar um Agentic CRAG usando LangGraph e documentos reais das atas do COPOM.
O que é o CRAG?
O CRAG (Corrective Retrieval-Augmented Generation) é uma evolução do RAG tradicional, criado para lidar com um problema recorrente: documentos irrelevantes ou incorretos recuperados na busca.
Enquanto o RAG simplesmente pega os documentos encontrados e envia ao modelo de linguagem (LLM) para gerar uma resposta, o CRAG adiciona um mecanismo de autocorreção. Esse mecanismo avalia a qualidade das informações antes de usá-las.
Se o material recuperado não for confiável, o sistema pode:
-
Corrigir a consulta para melhorar a busca.
-
Buscar novas fontes, como resultados da web.
-
Filtrar informações irrelevantes antes de enviá-las ao LLM.
Isso reduz a chance de alucinações (respostas inventadas) e aumenta a precisão, especialmente em áreas sensíveis, como finanças, saúde ou direito.
Como o CRAG funciona na prática
O processo do CRAG pode ser dividido em quatro etapas principais:
-
Avaliação da recuperação
-
Um “avaliador leve” (geralmente um modelo como T5) mede a relevância de cada documento em relação à pergunta do usuário.
-
-
Classificação da confiança
-
Dependendo da pontuação, o resultado é classificado como:
-
Correct: documentos relevantes, prontos para uso.
-
Incorrect: documentos irrelevantes; o sistema descarta e busca na web.
-
Ambiguous: incerteza sobre a qualidade; combina busca interna + web.
-
-
-
Refinamento da informação
-
Os documentos relevantes passam pelo método decompose-then-recompose:
-
Decompose: quebra o conteúdo em “tiras de conhecimento”.
-
Recompose: reconstrói a informação sem trechos inúteis.
-
-
-
Busca complementar na web
-
Se necessário, a pergunta é reescrita para otimizar os resultados externos.
-
As informações da web também passam pelo refinamento antes de chegar ao LLM.
-
O sistema de classificação do CRAG é o que torna sua abordagem mais inteligente e adaptativa:
-
Correct (Correto)
Pelo menos um documento é altamente relevante. O CRAG usa o conteúdo após o refinamento. -
Incorrect (Incorreto)
Nenhum documento recuperado é útil. O sistema reescreve a consulta e aciona uma busca na web para obter dados melhores. -
Ambiguous (Ambíguo)
O avaliador não tem confiança suficiente para dizer que os resultados são bons ou ruins. Nesse caso, o CRAG combina o melhor das fontes internas com resultados da web, garantindo maior cobertura de informação.
Esse processo evita que documentos irrelevantes contaminem a resposta final e permite que o LLM trabalhe com material de maior qualidade.
Vantagens do Agentic CRAG
-
A adoção do CRAG oferece vantagens claras em relação ao RAG tradicional:
-
Maior precisão: filtra documentos inúteis antes que cheguem ao modelo.
-
Menos alucinações: garante que a geração seja baseada em informações relevantes.
-
Flexibilidade: integra busca local e web, adaptando-se a diferentes cenários.
-
Escalabilidade: pode ser aplicado a qualquer domínio, de macroeconomia a saúde.
-
Transparência: permite rastrear exatamente quais documentos embasaram a resposta.
Na prática, isso significa que, se um cliente ou analista pedir para validar a origem de uma resposta, você pode mostrar as fontes usadas e explicar como a decisão foi tomada.
-
Integração com LangGraph
O projeto em Python utiliza LangGraph para estruturar o fluxo do agente, onde cada nó representa uma etapa do processo:
- Recuperação: busca de trechos das atas do COPOM a partir de um repositório vetorial criado com Chroma e embeddings do Google Generative AI.
- Avaliação: uso de um LLM para classificar se o documento é relevante ou não.
- Geração: construção da resposta final com base apenas nos documentos relevantes.
- Correção: reescrita da pergunta para otimizar buscas adicionais.
- Busca externa: se não houver informações suficientes, o agente realiza pesquisas na web.
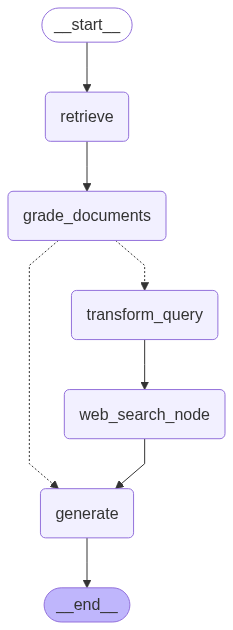
Fluxo de Trabalho do Agentic CRAG
O fluxo segue o conceito de Agentic RAG, mas com a adição do passo corretivo:
Pergunta do usuário → Recuperação de documentos → Avaliação de relevância → (Se necessário) Busca externa → Geração da resposta final
Esse ciclo se repete até atingir a melhor resposta possível, combinando automação, curadoria e inteligência contextual.
Exemplo com as Atas do COPOM
No exercício implementado, carregamos as últimas atas do COPOM diretamente do site do Banco Central, processamos os PDFs e os transformamos em uma base vetorial. Ao perguntar, por exemplo, “Qual foi a avaliação do COPOM em julho de 2025 sobre o cenário inflacionário global?”, o agente:
- Recupera os documentos relevantes;
- Filtra apenas os trechos que falam sobre inflação global;
- Gera uma resposta resumida, precisa e apoiada em evidências.
Conclusão
O Agentic CRAG representa um passo à frente na criação de assistentes inteligentes, especialmente em áreas onde a precisão e a confiabilidade são cruciais, como análise econômica e política monetária.
Combinando RAG, LangGraph e técnicas de correção automática, criamos sistemas que não apenas respondem, mas também pensam estrategicamente para fornecer a melhor informação possível.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

