Introdução
Vamos dar continuidade à construção do assistente de pesquisa com LangGraph, um sistema que integra geração de conteúdo, análise especializada e múltiplas perspectivas para produzir relatórios completos e bem estruturados.
Partiremos do exercício anterior, "Criando Personas de Analistas com LangGraph", e avançaremos para a implementação de um fluxo capaz de gerar relatórios a partir de conversas entre analistas e experts, explorando também a criação paralelizada de conteúdo com base em fontes como Wikipedia e buscas na web.
O sistema é desenhado para:
-
Criar personas de analistas econômicos com diferentes perfis de especialização;
-
Conduzir entrevistas com um especialista fictício, extraindo insights relevantes;
-
Produzir relatórios técnicos a partir das informações obtidas, combinando dados factuais e análises qualitativas.
A execução combina LLMs, ferramentas de busca na web e Wikipedia, além de pontos de interação humana para refinar os resultados.
O fluxo segue uma orquestração por etapas, que vai desde a definição das personas até a produção das seções do relatório, garantindo relevância, precisão e transparência nas informações.
O código é organizado em blocos lógicos, cada um correspondendo a uma etapa específica do pipeline, interligados por nós e transições no grafo de estados do LangGraph, permitindo um controle claro do processo e facilitando ajustes ou expansões futuras.
Arquitetura do Sistema
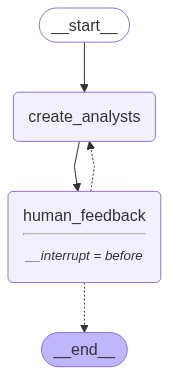
A estrutura foi dividida em três componentes principais:
- Agente Gerador de Perspectivas
- Utiliza um modelo de linguagem para criar um conjunto inicial de personas analíticas, cada uma com foco específico sobre o tema.
- Feedback Humano
- O fluxo pausa para que um usuário revise e, se necessário, solicite ajustes nas personas criadas, garantindo alinhamento com os objetivos da pesquisa.
- Compilação Final
- O sistema reúne todas as perspectivas aprovadas para criar um relatório final com múltiplos pontos de vista.
Fluxo de Trabalho
O assistente segue a seguinte sequência:
- O usuário fornece o tema de pesquisa.
- O sistema cria personas analistas com diferentes perfis.
- O usuário revisa e ajusta as personas.
- O assistente finaliza o relatório com base nas perspectivas validadas.
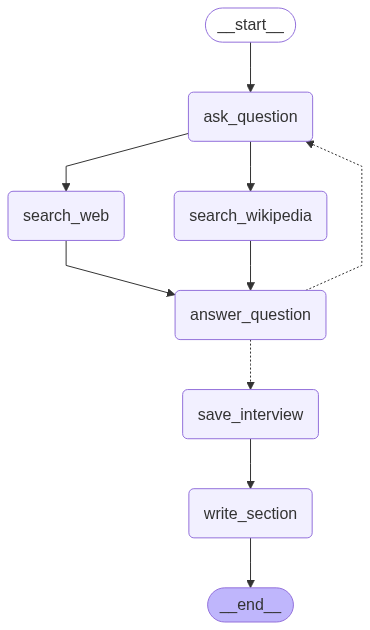
O primeiro grafo é responsável por gerar diferentes personas de analistas, cada uma com um perfil e visão específicos. Essas personas são utilizadas para conduzir entrevistas distintas com um especialista, criando uma base rica e variada de informações. O material coletado nessas entrevistas serve como insumo para que o editor desenvolva o texto final, etapa que será tratada no próximo grafo.
 O segundo grafo é encarregado de elaborar o relatório simples a partir da reflexão conjunta dos agentes do sistema, combinando as análises das personas com as contribuições dos especialistas, resultando em um conteúdo mais completo e consistente.
O segundo grafo é encarregado de elaborar o relatório simples a partir da reflexão conjunta dos agentes do sistema, combinando as análises das personas com as contribuições dos especialistas, resultando em um conteúdo mais completo e consistente.
 Resultado
Resultado
A partir do primeiro grafo, desenvolvemos personas voltadas para a análise econômica, com o objetivo de elaborar relatórios sobre política monetária. O agente gerou diferentes personas fictícias, entre elas:
Afiliação: Banco Central do Brasil Papel: Modelagem Econométrica Descrição: Focado na modelagem econométrica dos canais de crédito e taxa de juros, buscando otimizar a eficácia da política monetária para controle da inflação. -------------------------------------------------- Nome: Carlos Eduardo Oliveira Afiliação: Startup de Tecnologia Financeira Papel: Inovação Financeira e PMEs Descrição: Interessado no impacto da política monetária no acesso ao crédito para pequenas empresas e no desenvolvimento de novos produtos financeiros digitais. -------------------------------------------------- Nome: Mariana Costa Afiliação: Universidade de São Paulo Papel: Economia Keynesiana e Investimento Público Descrição: Especialista em economia keynesiana, investigando o papel dos gastos do governo e do investimento na transmissão da política monetária em cenários de crise. --------------------------------------------------
Após a definição das personas, cada analista conduz uma entrevista simulada com um especialista. O sistema gera perguntas alinhadas aos objetivos e à persona, buscando informações na Wikipedia e busca de notícias, através de um WebSearch. O fluxo alterna entre perguntas e respostas até atingir um número definido de interações ou até que o entrevistador encerre voluntariamente a conversa.
Otimizando a Política Monetária: Canais de Crédito e Taxa de Juros no Brasil
Resumo
A eficácia da política monetária no controle da inflação depende crucialmente da compreensão dos seus mecanismos de transmissão, com destaque para os canais de crédito e taxa de juros. A literatura tradicional enfatiza esses canais como vetores principais na transmissão da política monetária [1]. No contexto brasileiro, a dinâmica entre os indicadores do mercado de crédito, a política monetária e a atividade econômica tem sido objeto de estudo, buscando entender as relações existentes [2]. Uma revisão da literatura focada nos canais de transmissão da política monetária no Brasil oferece um panorama geral desses mecanismos [3].
Fontes
[1] https://www.scielo.br/j/rbe/a/S6Kz6f94H3h8cvcKj5V8Rrm/?format=html [2] https://www.ie.ufrj.br/images/IE/PPGE/teses/2019/T%C3%A2nia%20Aparecida%20Gomes%20%20Paes.pdf [3] https://www.econ.puc-rio.br/uploads/adm/trabalhos/files/Mono_23.2_Julia_Figueiredo_de_Abreu.pdf
Conclusão
Integrar LangGraph com um processo iterativo de geração e refinamento de conteúdo permite criar assistentes de pesquisa robustos e adaptáveis.
Essa abordagem é ideal para organizações e profissionais que precisam de relatórios confiáveis, produzidos com múltiplos pontos de vista e supervisionados por humanos.
Quer aprender mais?
Conheça nossa Formação do Zero à Análise de Dados Econômicos e Financeiros usando Python e Inteligência Artificial. Aprenda do ZERO a coletar, tratar, construir modelos e apresentar dados econômicos e financeiros com o uso de Python e IA.

