A Volatilidade é uma medida que visa avaliar o risco de séries financeiras. Esse indicador, estudado por muitos anos, é não observável, ou seja, é necessário que haja meios de estimar os seus valores. Para tanto, modelos do tipo GARCH são úteis para obter a volatilidade de séries de ações. No post de hoje, mostramos como é possível estimar um GARCH (1,1) através do Python utilizando como exemplo a série de Retornos diários da PETR4.
Já tratamos sobre os fatos e características de volatilidade de séries financeiras em dois post anteriores: Aplicações de modelos de volatilidade no R e Volatilidade e modelos ARCH e GARCH. Salientamos aqui algumas questões importantes sobre a volatilidade.
- A volatilidade é alta em certos períodos e baixa em outros, configurando o que a literatura
chama de volatility cluster; - A volatilidade evolui de maneira contínua, de modo que saltos não são comuns;
- A volatilidade costumar variar em um intervalo fixo (isso significa que a volatilidade é estacionária);
- A volatilidade costuma reagir de forma diferente a um aumento muito grande nos preços e a um decréscimo igualmente muito grande, com o último representando maior impacto.
Modelos do tipo GARCH consideram que ao obter retornos de uma série financeira estaríamos lidando com uma série que aparenta ser um ruído branco com caudas pesadas. Ao elevarmos o valor dos erros da previsão média do retorno ao quadrado (tomando a média como zero, ou seja, a variância seria igual a estes erros ao quadrado), obteríamos uma série de heterocedasticidade condicional, portanto, a variância não é constante ao longo do tempo, e os seus valores passados afetam o valor presente. Com isso, obtemos um modelo que captura esses componentes.
![$$\mu_t = E[R_t | I_{t-1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-c34837c7fc5271c5f7c5db5656f1e760_l3.png "Rendered by QuickLaTeX.com")
Com os erros da previsão sendo

Com base nas informações no tempo  , também é possível calcular a variância:
, também é possível calcular a variância:
![$$\sigma^2 = E[(R_t - \mu_t)^2 | I_{t-1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-3a3886349da339216983f61a81db4e8f_l3.png "Rendered by QuickLaTeX.com")
![$$ = E[e^2_t |I_{t_1}]$$](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-b5cef7ef9509a346edcc56f13905cfa5_l3.png "Rendered by QuickLaTeX.com")
Ao realizar a estimação da previsão média dos retornos, podemos realizá-la tanto através de média móvel dos retornos, calculada a partir de:

quanto a partir de um processo ARMA.
O que nos permitirá ter o modelo:
GARCH(1,1)

Volatilidade da PETR4
Feito a introdução, utilizaremos a série de retornos contínuos da PETR4 para estimar a volatilidade da ação e realizar uma previsão 5 períodos a frentes utilizando o Python.
Obtemos os preços ajustados da PETR utilizando a função get_data_yahoo(). Veja que utilizamos dados após 2018-01-01. Em seguida, calculamos os log retornos dos preços diários e retiramos os dados faltantes.
Com a série em mãos, agora é necessário especificar o modelo utilizando arch_model. Além da série de retornos, escolhemos a ordem de p e q como 1, pois utilizaremos um GARCH(1,1). A média será constante e tomaremos a distribuição dos resíduos padronizados como normal.
Escolhido as configurações do modelo, "rodamos" ele com o método fit() e obtemos os resultados utilizando métodos e atributos do objeto. Através de params, obtemos os valores dos parâmetros estimados. Caso queiramos ver todos os valores produzidos, utilizamos summary().
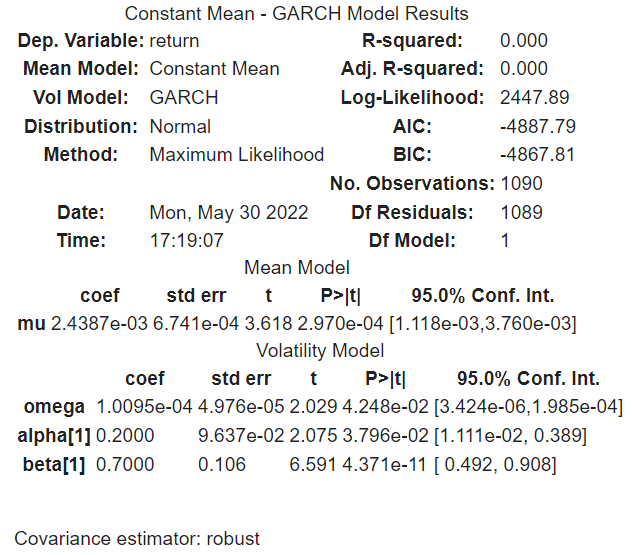
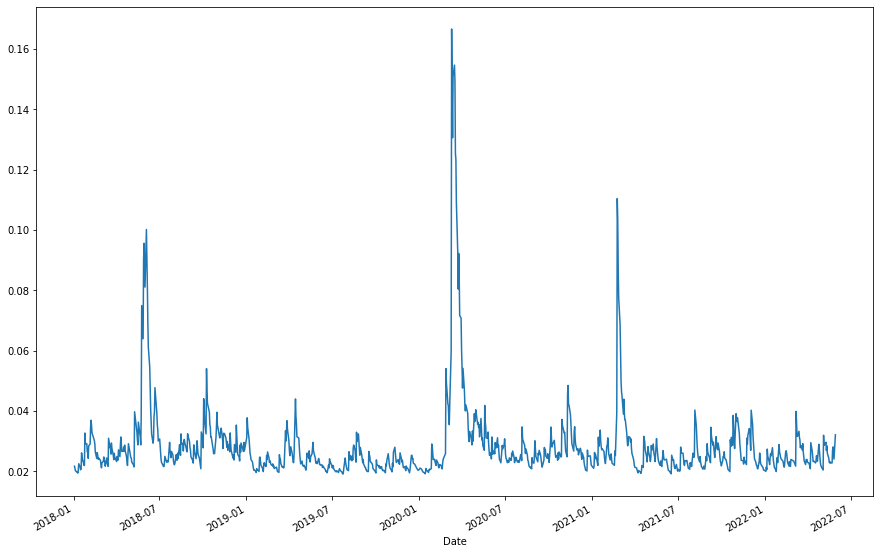
Também é intereressante visualizar o resultado da volatilidade da série. Retiramos os valores estimados da volatilidade com o atributo conditional_volatility e plotamos.
Por fim, é possível realizar a previsão da variância utilizando o método forecast().

_______________________
Quer saber mais?
Veja nossos cursos da trilha de Finanças Quantitativas.

