Um forma de medir o desempenho ou performance de um ativo, normalmente um fundo de investimento, ou mesmo uma carteira de investimento se dá através do Índice de Sharpe. O índice tem como propósito medir o desempenho do ativo por unidade de risco, ou seja, a cada 1 ponto de risco, quanto é adicionado de retorno do ativo. No post de hoje iremos trabalhar em como calcular o índice de Sharpe no R.
O Índice de Sharpe mede os retornos excedentes por unidade de risco, tomando aqui como medida de risco o *desvio padrão*. A fórmula do IS pode ser dada como:
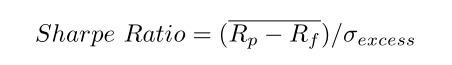
Ou seja, a diferença entre o retorno do ativo e o retorno do ativo livre de risco, dividido pelo desvio padrão do respectivo ativo.
library(quantmod) library(tidyquant) library(timetk) library(GetBCBData) library(tidyverse) library(xts)
Coletamos os preços dos ativos e calculamos o retorno do nosso portfólio.
# Define os ativos que irão ser coletados
tickers <- c("PETR4.SA", "ITUB4.SA", "ABEV3.SA", "JBSS3.SA")
# Define a data de início da coleta
start <- as.Date("2016-12-01")
# Realiza a coleta dos preços diários
prices <- getSymbols(tickers,
auto.assign = TRUE,
warnings = FALSE,
from = start,
src = "yahoo") %>%
map(~Cl(get(.))) %>%
reduce(merge) %>%
`colnames<-`(tickers)
# Transfroma os preços diários em mensais
prices_monthly <- to.monthly(prices,
indexAt = "lastof",
OHLC = FALSE)
# Calcula os retornos mensais
asset_returns <- Return.calculate(prices_monthly,
method = "log") %>%
na.omit()
# Define os pesos de cada ativo
w <- c(0.50, 0.27, 0.13, 0.10)
# Calcula o retorno do portfolio baseado no peso de cada ativo
portfolio_return <- Return.portfolio(asset_returns,
weights = w) %>%
`colnames<-`("port_returns")
Podemos então calcular o índice de Sharpe. Para fins didáticos, iremos utilizar a taxa SELIC anual de 9,15%, mensurando o IS no ano de 2021. Como os dados estão mensais, devemos transformar a taxa selic em mensal.
rf = 9.15/100 # Define a taxa livre de risco # Filtra os retornos para o ano de 2021 portfolio_return_2021 <- portfolio_return["2021"] # Calcula o índice de Sharpe SharpeRatio(R = portfolio_return_2021, Rf = rf/12, FUN = "StdDev")
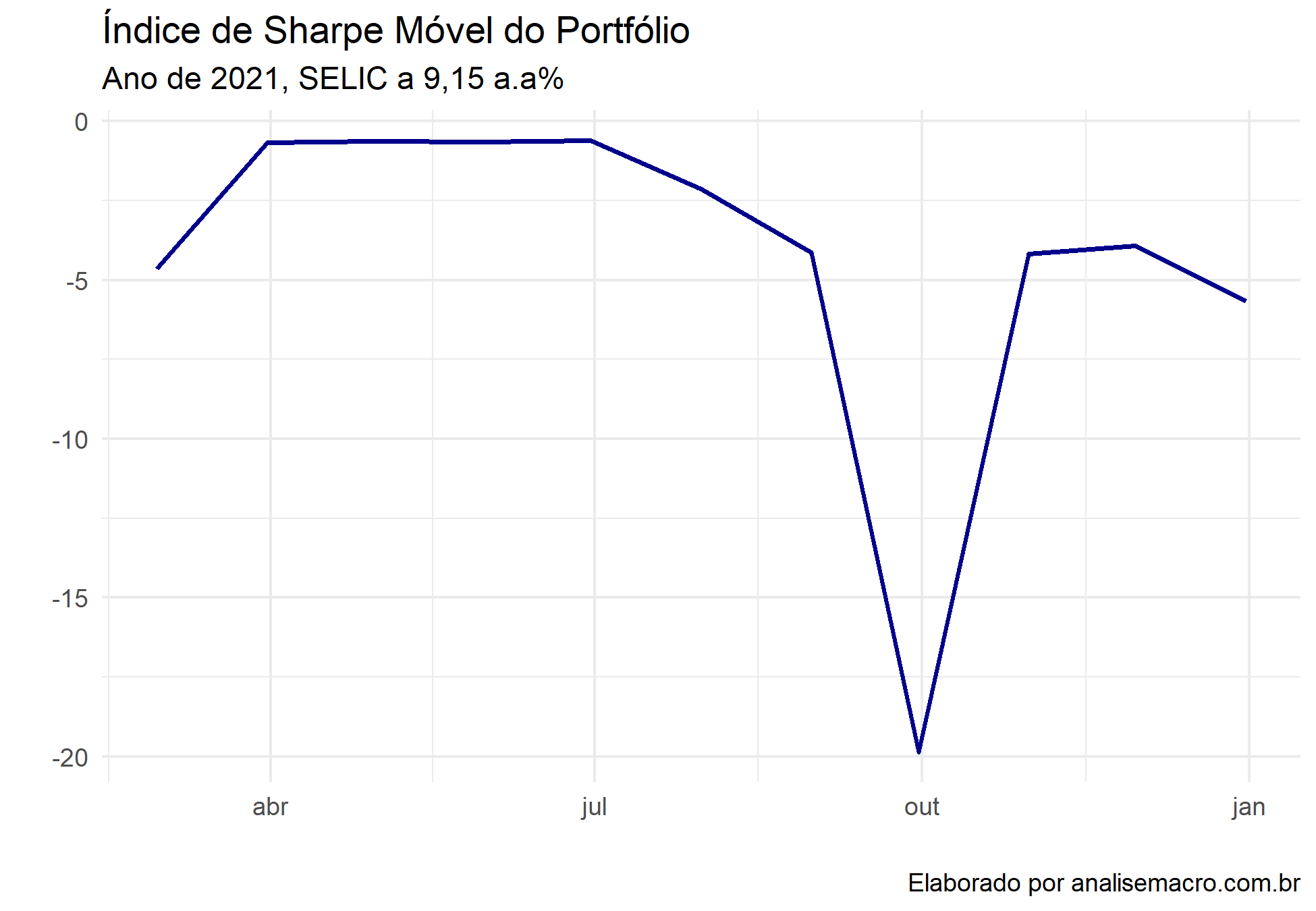
 É possível também que seja criado o Índice de Sharpe móvel, de forma que possamos acompanhar suas mudanças ao longo do tempo.
É possível também que seja criado o Índice de Sharpe móvel, de forma que possamos acompanhar suas mudanças ao longo do tempo.
Para isso, utilizaremos as funções do pacote {tidyquant}.
# Cria a função do IS
sharpe_tq_roll <- function(df){
SharpeRatio(df,
Rf = rf,
FUN = "StdDev")
}
# Transforma de xts para tibble
portfolio_return_2021_tbl <- portfolio_return_2021 %>%
tk_tbl(preserve_index = TRUE,
rename_index = "date")
# Calcula o Índice de Sharpe móvel
rolling_sharpe_tq <-
portfolio_return_2021_tbl %>%
tq_mutate(
select = port_returns,
mutate_fun = rollapply,
width = 2,
FUN = sharpe_tq_roll,
col_rename = "sharpe") %>%
na.omit()
Por fim, visualizamos o IS móvel.
rolling_sharpe_tq %>% ggplot(aes(x = date, y = sharpe))+ geom_line(size = .8, color = "darkblue")+ labs(title = "Índice de Sharpe Móvel do Portfólio", subtitle = "Ano de 2021, SELIC a 9,15 a.a%", x = "", y = "", caption = "Elaborado por analisemacro.com.br")+ theme_minimal()
________________________
(*) Para entender mais sobre Mercado Financeiro e aprender como realizar a coleta, tratamento e visualização de dados financeiros, confira nosso curso de R para o Mercado Financeiro.
________________________


