Os modelos multifatores de precificação de ativos, muito conhecidos na finanças, utilizam fatores de risco para calcular o retorno de um ativo. Modelos mais simples tais como o Modelo de Mercado, ou mesmo o mais conhecido no mundo das finanças, o Capital Asset Pricing Model, utilizam o conhecido Beta, fator de risco do mercado, para precificação. No post de hoje, iremos estender o CAPM e fazer um exercício de um modelo também conceituado, que utiliza mais de um fator para a precificação, o modelo Fama French de 3 fatores.
Como uma extensão do CAPM, o modelo Fama French relaciona o excesso de retorno (diferença do retorno do ativo com o retorno livre de risco) em relação ao prêmio pelo risco do mercado, além também de dois outro fatores: HML (High minus Low), sendo a diferença entre os retornos das firmas que tenham um alto book-to-market e baixo book-to-market; e SMB (Small minus Big Factor), sendo a diferença entre empresas grandes e pequenas.

A sensitividade de cada fator é medido pelos  da equação, sendo possível mensurar os riscos que uma carteira de ativos sofrem, bem como traçar estratégias com as informações da influência de cada fator de risco.
da equação, sendo possível mensurar os riscos que uma carteira de ativos sofrem, bem como traçar estratégias com as informações da influência de cada fator de risco.
Agora, vamos realizar um exemplo dentro do R. O site https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html facilita o trabalho realizando cálculos dos fatores de risco para diversos países. Como exemplo, utilizaremos ações e os fatores do EUA para demonstrar o cálculo do modelo Fama French. Para o Brasil, o NEFIN-USP realiza os cálculos para os fatores.
# Carrega os pacotes library(tidyverse) library(quantmod) library(permutations) library(lubridate) library(tidyquant) library(broom)
# Importa os dados baixados
factors <- read_csv("F-F_Research_Data_Factors.csv", skip=3) %>%
rename(date = ...1) %>%
mutate_at(vars(-date), as.numeric) %>%
mutate(date = ymd(parse_date_time(date, '%Y%m')),
date = rollback(date + months(1))) %>%
drop_na()
# Coleta os preços
symbols <- c("SPY","EFA", "IJS", "EEM","AGG")
prices <- tq_get(symbols,
get = "stock.prices",
from = "2012-12-31",
to = "2019-01-01")
# Transforma em retornos
asset_returns <- prices %>%
group_by(symbol) %>%
tq_transmute(select = adjusted,
mutate_fun = periodReturn,
period = "monthly",
indexAt = "lastof",
type = "log")
# Calcula o retorno do portfólio portfolio_return <- asset_returns %>% tq_portfolio(assets_col = symbol, returns_col = monthly.returns, col_rename = "returns", rebalance_on = "quarters")
# Junta os data frame ff_portfolio <- portfolio_return %>% left_join(factors, by = "date") %>% mutate(mkt_rf = `Mkt-RF`/100, smb = SMB/100, hml = HML/100, rf = RF/100, r_excess = round(returns - rf, 4)) %>% select(- rf)
# Cria o modelo ff_model <- ff_portfolio %>% lm(r_excess ~ mkt_rf + smb + hml, data = .) %>% augment() %>% mutate(date = ff_portfolio$date, returns = ff_portfolio$returns)
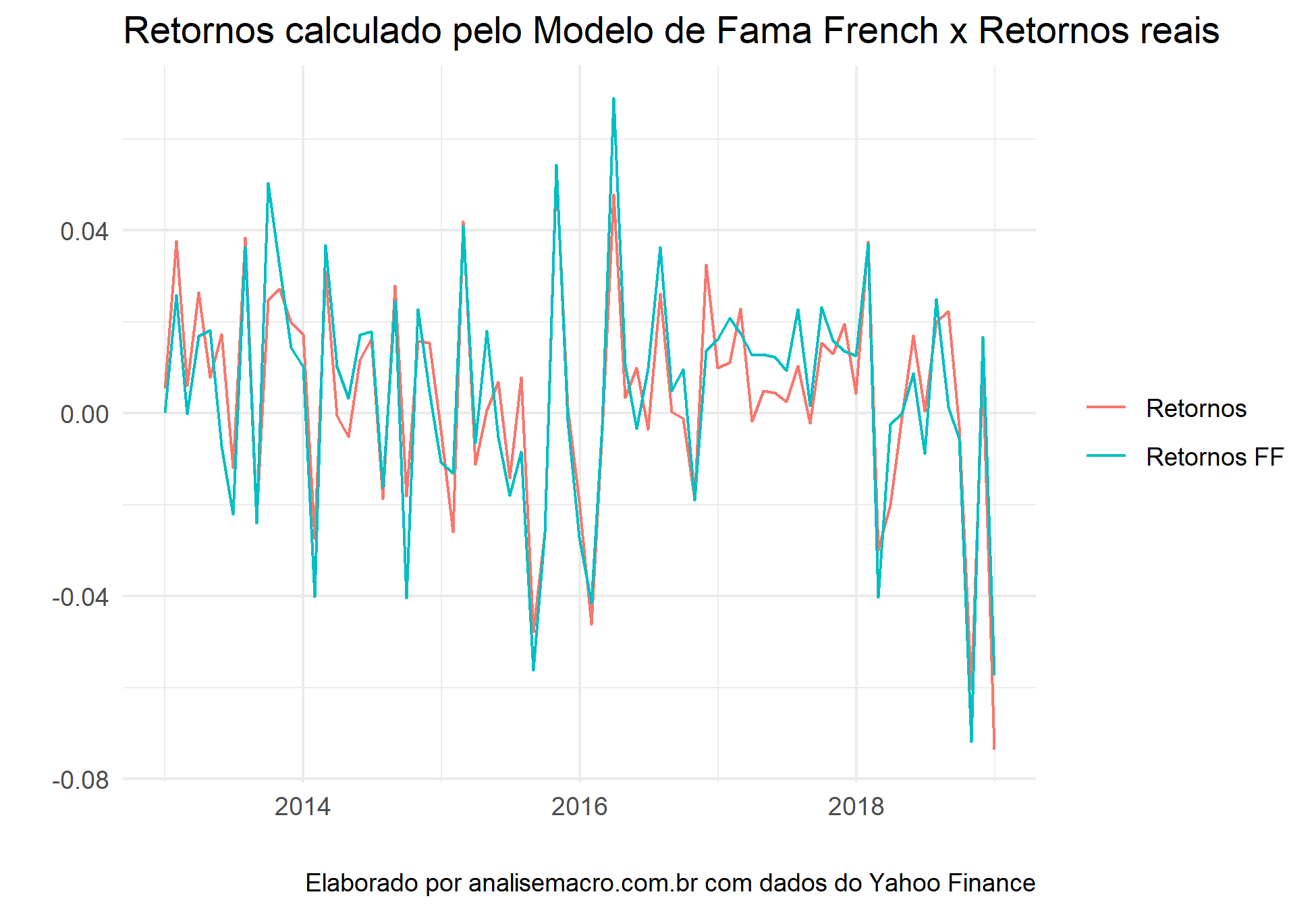
# Plota ff_model %>% ggplot(aes(x = date))+ geom_line(aes(y = .fitted, color = "Retornos"))+ geom_line(aes(y = returns, color = "Retornos FF"))+ labs(title = "Comparação - Retornos calculado pelo Modelo de 3 Fatores Fama French x Retornos reais", x = "", y = "", caption = "Elaborado por analisemacro.com.br com dados do Yahoo Finance")+ theme_minimal()+ theme(legend.title = element_blank())
 ________________________
________________________
(*) Para entender mais sobre finanças e modelagem, confira nosso curso de R para o Mercado Financeiro.
________________________


