Na última terça-feira, na nossa 10ª live de análise de dados com R (clique aqui para se inscrever para a próxima), eu mostrei como analisar microdados da PNAD Contínua com o R. Em particular, mostrei alguns dados sobre renda nesse país desigual chamado Brasil. Nesse post faço um resumo da aula.
Conheça o Curso de Avaliação de Políticas Públicas usando o R
Na aula, usei os pacotes abaixo.
library(tidyverse) library(PNADcIBGE) library(survey) library(geobr)
O pacote PNADcIBGE é utilizado, basicamente, para baixar e ler os dados. Você pode baixar os microdados da PNAD de forma direta para o RStudio ou pegar os dados manualmente no ftp do IBGE. Na aula, optei por usar essa última opção, posto que há uma demora para baixar/ler os dados. Assim, peguei os microdados da PNAD Contínua trimestral referente ao 4º trimestre de 2020 no ftp e importei para o R como abaixo. Além de ler os dados, também já preparei os mesmos para ser analisado com o pacote survey.
microdados_pnadc = read_pnadc('PNADC_042020.txt', 'input_PNADC_trimestral.txt')
microdados_pnadc = pnadc_labeller(microdados_pnadc,
'dicionario_PNADC_microdados_trimestral.xls')
microdados_pnadc = pnadc_design(microdados_pnadc)
Uma vez que os dados estejam prontos, nós podemos analisar alguns dados de renda e tirar algumas lições importantes. Por exemplo, qual a renda média mensal do brasileiro? Para ver isso, podemos rodar a linha de código abaixo.
renda_media = svymean(~VD4020, microdados_pnadc, na.rm=T)
Chegamos à conclusão que a renda média mensal no nosso país é de R$ 2482,40. Há diferença se a pessoa é branca ou preta? Vejamos...
svymean(~VD4020, subset(microdados_pnadc, V2010 == "Branca"), na.rm=T) svymean(~VD4020, subset(microdados_pnadc, V2010 == "Preta"), na.rm=T)
Uma pessoa branca ganha em média R$ 3197,70 enquanto uma pessoa preta ganha em média bem menos, R$ 1845,90.
A coisa parece ficar ainda mais complicada se adicionamos o sexo. Por exemplo, um homem branco com mais de 38 anos ganha em média R$ 4075, 40. Para ver isso, basta rodar a linha de código abaixo.
svymean(~VD4020, subset(microdados_pnadc, V2007 == 'Homem' & V2010 == "Branca" & V2009 > 38), na.rm=T)
Já uma mulher branca com mais de 38 anos ganha em média R$ 3112,50. Homens pretos com mais de 38 anos ganham em média R$ 2311,3 e mulheres pretas com mais de 38 anos ganham em média 1684,90. Para visualizar esses dados, basta substituir no código acima o sexo (V2007) e a cor (V2010).
Nesse país extremamente desigual, o sexo e a cor da pele explicam diferenciais consideráveis de renda.
Mas, vamos lembrar que o Brasil também é um país pobre. A renda média, como visto, é de pouco menos de R$ 2500. E quanto você acha que é preciso ganhar para estar nos 10% mais ricos? Podemos ver os quantis de renda com a linha de código abaixo.
renda_quantile = svyquantile(~VD4020, microdados_pnadc, quantiles = c(.1,.25,.5,.75,.90,.99,.999), na.rm=TRUE, ci=TRUE) print(xtable(renda_quantile), type='html')
| 0.1 | 0.25 | 0.5 | 0.75 | 0.9 | 0.99 | 0.999 | |
|---|---|---|---|---|---|---|---|
| VD4020 | 400.00 | 1000.00 | 1500.00 | 2500.00 | 5000.00 | 20000.00 | 40000.00 |
Pois é. Para estar entre os 10% mais ricos, basta ganhar mais do que R$ 5000 mensais. Já para estar nos 1% mais ricos, você deve auferir R$ 20 mil de renda mensal. E, acredite, para estar no 0,1% mais rico da população brasileira, você tem que ganhar mais do que R$ 40 mil mensais.
A maioria da população não tem ideia de quão pobre é o Brasil e isso é um baita problema, viu...
E a educação importa para a renda?
### Média de renda por nível educacional mediaRendaEduc = svyby(~VD4020, ~VD3004, microdados_pnadc, svymean, na.rm=T) mediaRendaEduc %>% ggplot(aes(x=VD4020, y=VD3004))+ geom_bar(stat='identity', colour='lightblue', fill='lightblue')
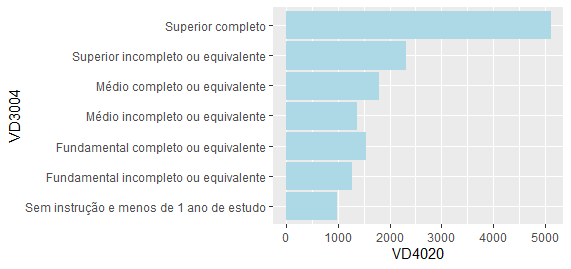
Sim, parece que sim. Pessoas com nível superior completo auferem em média mais de R$ 5000 mensais, quase três vezes mais de quem tem apenas o ensino médio completo.
E a ocupação importa para a renda?
mediaRendaOcup = svyby(~VD4020, ~VD4008, microdados_pnadc, svymean, na.rm=T) mediaRendaOcup$VD4008 = recode(mediaRendaOcup$VD4008, "Empregado no setor público (inclusive servidor estatutário e militar)" = "Empregado no setor público") mediaRendaOcup %>% as_tibble() %>% ggplot(aes(x=VD4020, y=VD4008))+ geom_bar(stat='identity', colour='orange', fill='orange')
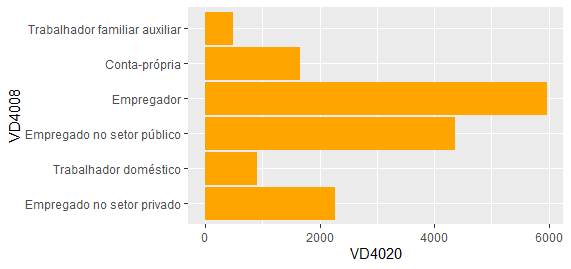
A renda média do empregado no setor público é quase o dobro do empregado no setor privado.
Por fim, como é a renda nos estados?
### Média da Renda nas UFs
mediaRendaUF = svyby(~VD4020, ~UF, microdados_pnadc, svymean, na.rm = TRUE)
states = read_state(year=2019)
### Gráfico
no_axis = theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank())
states = left_join(states, mediaRendaUF, by = c('name_state' = 'UF'))
sapply(states, function(x) sum(is.na(x)))
states$VD4020[states$name_state=='Amazônas'] = mediaRendaUF$VD4020[mediaRendaUF$UF=='Amazonas']
states$VD4020[states$name_state=='Rio Grande Do Norte'] = mediaRendaUF$VD4020[mediaRendaUF$UF=='Rio Grande do Norte']
states$VD4020[states$name_state=='Rio Grande Do Sul'] = mediaRendaUF$VD4020[mediaRendaUF$UF=='Rio Grande do Sul']
states$VD4020[states$name_state=='Mato Grosso Do Sul'] = mediaRendaUF$VD4020[mediaRendaUF$UF=='Mato Grosso do Sul']
states$VD4020[states$name_state=='Rio De Janeiro'] = mediaRendaUF$VD4020[mediaRendaUF$UF=='Rio de Janeiro']
ggplot()+
geom_sf(data=states, aes(fill = as.numeric(VD4020)), colour=NA, size=.15)+
scale_fill_distiller(palette = 'Spectral', name='Renda Média')
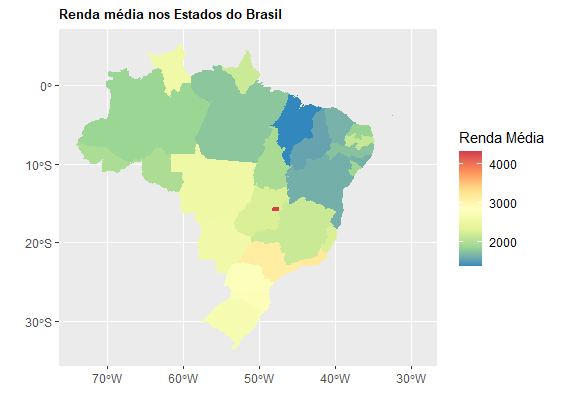
O Distrito Federal destoa no mapa como sendo quase uma ilha, com a maior renda média do país. Por que será?
_______________________
(*) A renda aqui considerada é o rendimento mensal efetivo de todos os trabalhos para pessoas de 14 anos ou mais de idade (apenas para pessoas que receberam em dinheiro, produtos ou mercadorias em qualquer trabalho).
(**) Conheça o Curso de Avaliação de Políticas Públicas usando o R


