Dando continuidade a série de exercícios de análise de dados temáticos sobre as Eleições 2022, hoje usaremos as narrativas de cada candidato a Presidente nas rodadas de entrevistas do Jornal Nacional para sintetizar quantitativamente o "tom" de cada entrevista. O objetivo é extrair os principais tópicos abordados por cada candidato nos 40 minutos de entrevista, além de mensurar a "forma" como cada candidato abordou os tópicos, ou seja, se foram emitidas emoções positivas ou negativas em sua fala.
Os códigos de replicação em R deste exercício estão disponíveis para membros do Clube AM da Análise Macro.
Para manter o exercício breve serei bastante objetivo. Já realizei neste espaço diversos exercícios semelhantes ao aqui proposto, abordando text mining, modelagem de tópicos, web scraping, análise de sentimentos, dentre outros. Portanto, hoje pularei qualquer conceitualização e/ou introdução às técnicas de análise dos dados e irei diretamente para a análise prática. Se algo ficar "solto" te peço, por favor, para verificar estes exercícios anteriores para melhor compreensão:
- Topic Modeling: sobre o que o COPOM está discutindo? Uma aplicação do modelo LDA
- Análise das Atas do COPOM com text mining
- Detecção de plágio com NLP no R: o caso Decotelli
- Teto de Gastos: análise de sentimentos com dados do Twitter
- Previsão da inflação (EUA) com fatores textuais do FOMC
- Text mining dos comunicados do FOMC: prevendo mudanças na política
- Como fazer web scrapping de tabelas de dados usando o R?
Além disso, membros do Clube AM podem sempre mandar dúvidas pelo chat!
Dados
Os dados que usaremos para tentar alcançar o objetivo do exercício são as transcrições (textos) das entrevistas dos candidados listados abaixo, realizadas no Jornal Nacional com os jornalistas William Bonner e Renata Vasconcellos em agosto/2022:
- Bolsonaro (PL): entrevistado no dia 22
- Ciro (PDT): entrevistado no dia 23
- Lula (PT): entrevistado no dia 25
- Tebet (MDB): entrevistada no dia 26
A fonte dos dados originais é o grupo Poder360, que compilou e disponibilizou as transcrições em seu site. Estes dados foram previamente organizados em formato de tabela pelo Gabriel Zanlorenssi, facilitando a análise, tratamento e o uso em linguagens de programação (obrigado!).
Além das transcrições, para uma parte das análises usaremos o dicionário de sentimentos (léxico) da língua portuguesa denominado OpLexicon V3.0. Esse dataset é disponibilizado através do pacote de R {lexiconPT} criado por Sillas Gonzaga.
Análises
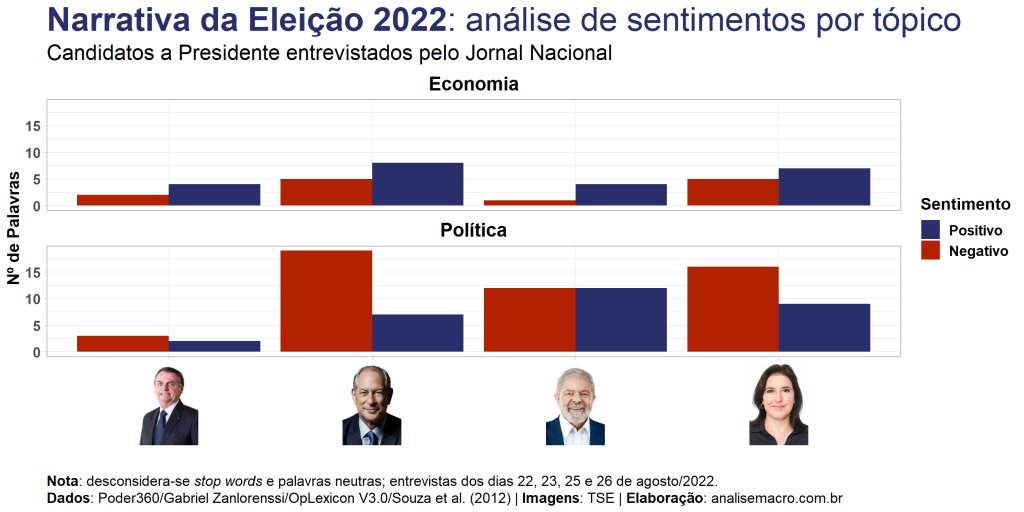
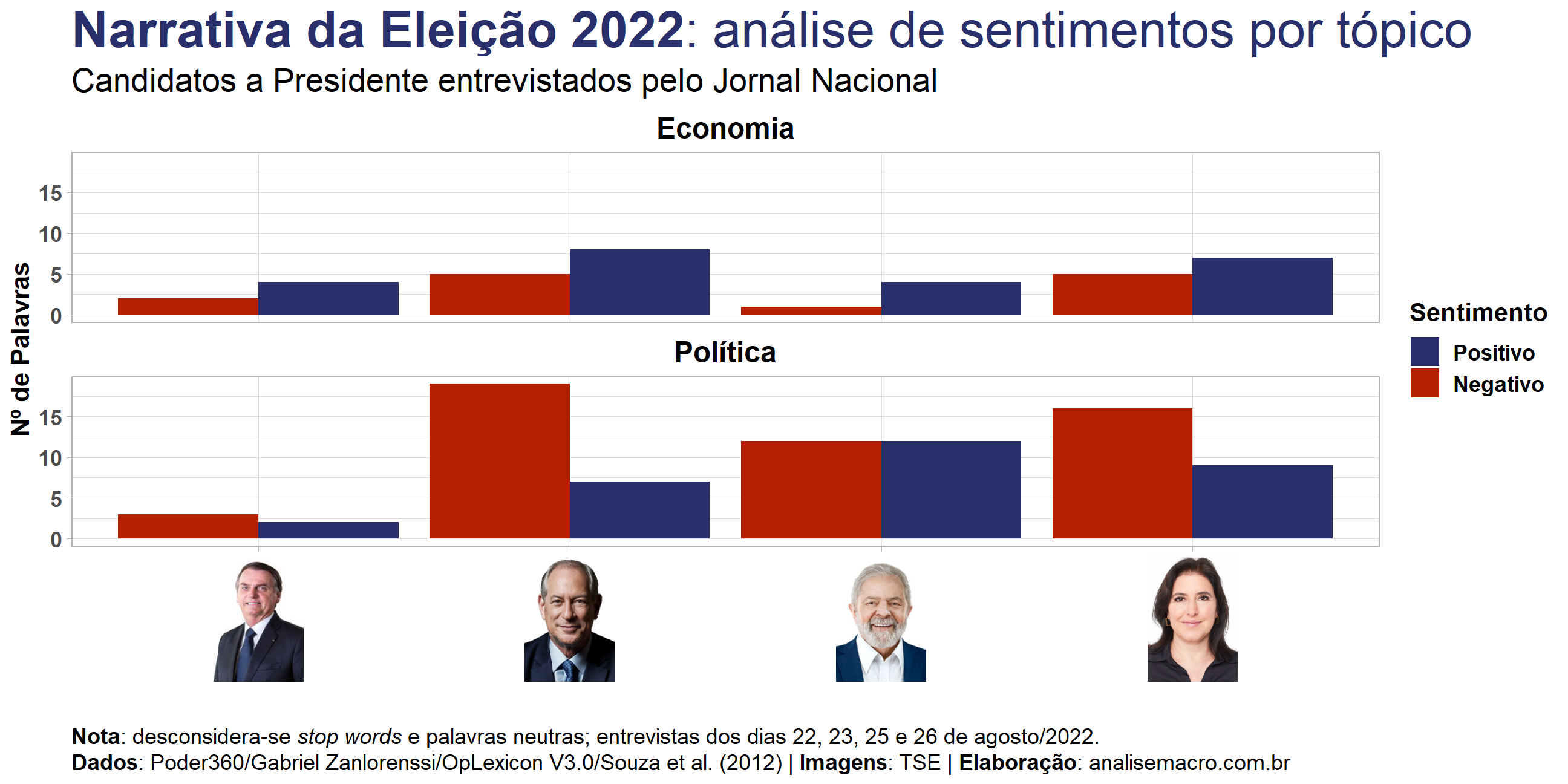
Para cumprir com o objetivo do exercício criaremos duas visualizações de dados: uma nuvem de palavras mais frequentes nas falas de cada candidato e uma contagem de palavras classificadas como positivas/negativas pelo léxico acima referido.
Mas antes disso vamos conferir algumas estatísticas gerais da narrativa dos candidatos, por ordem alfabética e após tratamentos:
Bolsonaro usou o total de 1.140 palavras únicas em sua entrevista. Dentre os tópicos discutidos, em Economia e Política, 33,8% das palavras indicaram sentimentos positivos e 31,2% negativos, sendo o restante classificadas como palavras neutras. O tópico classificado com o sentimento mais positivo foi STF e sistema eleitoral e com sentimento mais negativo foi Política. Bolsonaro utiliza, em média, 11 palavras por sentença.
Ciro usou o total de 1.562 palavras únicas em sua entrevista. Dentre os tópicos discutidos, em Economia e Política, 31,5% das palavras indicaram sentimentos positivos e 20,2% negativos, sendo o restante classificadas como palavras neutras. O tópico classificado com o sentimento mais positivo foi Economia e com sentimento mais negativo foi Polarização. Ciro utiliza, em média, 18 palavras por sentença.
Lula usou o total de 1.223 palavras únicas em sua entrevista. Dentre os tópicos discutidos, em Economia e Política, 31,9% das palavras indicaram sentimentos positivos e 23,8% negativos, sendo o restante classificadas como palavras neutras. O tópico classificado com o sentimento mais positivo foi Corrupção e com sentimento mais negativo foi Economia. Lula utiliza, em média, 16 palavras por sentença.
Tebet usou o total de 1.387 palavras únicas em sua entrevista. Dentre os tópicos discutidos, em Economia e Política, 30,1% das palavras indicaram sentimentos positivos e 20,9% negativos, sendo o restante classificadas como palavras neutras. O tópico classificado com o sentimento mais positivo foi Política e com sentimento mais negativo foi Mulheres. Tebet utiliza, em média, 16 palavras por sentença.
Nuvem de palavras
Apesar de haverem técnicas mais sofisticadas de extrair tópicos de dados textuais, neste caso as transcrições das entrevistas, talvez uma alternativa mais simples seja uma visualização do tipo "nuvem de palavras". Sendo assim, a imagem abaixo traz as palavras mais frequentemente faladas pelos candidatos, sendo o tamanho da palavra proporcional a sua frequência. Como de praxe, elimina-se palavras "irrelevantes" para a análise (as chamadas stop words), como, por exemplo, "de", "mas", "aquilo", etc; além de se desconsiderar números/pontuações e palavras de baixa frequência para não poluir a imagem.
A vantagem da nuvem de palavras é a sua simplicidade visual, mas um possível problema é a dificuldade do nosso cérebro em olhar esse conjunto de palavras e tentar encontrar um padrão, ou seja, um tópico sobre o qual as palavras se referem. Este tipo de exercício mais aprofundado fica para uma próxima, mas se você se contenta apenas com uma nuvem de palavras, recomendo utilizar o pacote {ggwordcloud} para reproduzir essa visualização!

Análise de sentimentos
De maneira a tentar sintetizar toda esse conjunto de informações textuais, mais especificamente quais emoções elas transmitem, podemos classificar as palavras com um léxico para obter o sentimento implícito nas falas dos candidatos. Aqui eu uso o dataset OpLexicon V3.0, que classifica mais de 30 mil palavras em polaridade (sentimento) de -1, 0 e 1, ou seja, negativa, neutra e positiva.
Para finalidade de comparação, considero somente os tópicos que foram discutidos com todos os candidatos. Conforme a visualização anterior, tratamentos de dados similares também são aplicados. Ao fim, contabiliza-se a frequência do sentimento classificado das palavras, considerando somente sentimentos positivos/negativos. Dessa forma, a visualização de dados é mais facilmente assimilada pelo cérebro, pois a informação foi resumida.
Saiba mais
Os códigos de replicação em R deste exercício estão disponíveis para membros do Clube AM da Análise Macro.
Para referências sobre os temas abordados confira os links supracitados.

