No mundo de hoje, o processo de tomada de decisão requer dados e informações rápidas com fácil acesso e interpretação. Não há tempo suficiente para esperar alguém fazer uma análise de dados e enviar os resultados. O custo de oportunidade é alto se houverem atrasos ou demoras nesse processo.
Para atender essa demanda por análise de dados rápida e acessível foram criadas ferramentas do tipo “autosserviço”: a pessoa acessa uma interface ou aplicativo, seleciona ou filtra algumas opções e, instantaneamente, obtém os dados e informações que buscava. Tudo isso sem precisar enviar um email, whatsapp ou pedir para o colega de trabalho da área de dados.
Nesse artigo apresentamos o conceito de autosserviço de análise de dados, discutimos as vantagens e desvantagens destas ferramentas e mostramos um exemplo aplicado, em R e Python, com dados econômicos usando a biblioteca Shiny.
O que é autosserviço de análise de dados?
Autosserviço de análise de dados é um tipo de análise onde não é necessário pedir ao analista de dados ou analista de BI para te entregar um relatório ou dashboard. Se tudo que você precisar é gerar um gráfico, filtrar dados ou calcular métricas padronizadas, você pode fazer isso por conta própria usando uma ferramenta do tipo “autosserviço”.
Em outras palavras, o autosserviço de análise de dados possibilita que você faça perguntas e obtenha respostas sem precisar ter conhecimento técnico aprofundado e sem depender de alguém para obter os dados e informações.
Vantagens de autosserviço de análise de dados
Existem muitas vantagens de uso de ferramentas autosserviço de análise de dados, algumas são:
- Independência: qualquer pessoa que saiba utilizar um celular ou computador pode fazer análise de dados;
- Agilidade: os dados e informações podem ser acessados diretamente pelo demandante, sem necessidade de intermediários, agilizando o processo de tomada de decisão;
- Acessibilidade: não é necessário programar, instalar programas ou buscar em múltiplas fontes para utilizar ferramentas de autosserviço de análise de dados;
- Escalabilidade: é possível analisar grandes volumes de dados de diversas fontes e temas, comportando aumentos de demanda de usuários ou de volume de dados;
- Customização: é possível flexibilizar as análises possíveis que a ferramenta pode entregar, habilitando botões, opções, filtros e outros elementos interativos.
Desvantagens de autosserviço de análise de dados
As ferramentas de autosserviço de análise de dados também apresentam alguns pontos desfavoráveis, como:
- Cultura: em muitos contextos pode ser cultural “pedir para alguém fazer” do que acessar diretamente uma ferramenta e obter os dados/análises necessários por conta própria;
- Especialidade: conhecimentos e experiências prévias podem ser necessários para identificar quais dados são úteis para uma demanda e como analisá-los, o que pode não ser a realidade de todos os usuários da ferramenta;
- Comunicação: falhas de comunicação podem levar ferramentas de autosserviço de análise de dados ao desuso, sendo necessário instruir sobre o uso, escopo, acesso e outros aspectos pertinentes.
Ferramentas de autosserviço de análise de dados
Existem diversas ferramentas criadas ao longo dos anos para finalidade de autosserviço de análise de dados. Elas se diferenciam em múltiplos aspectos como preço, complexidade, recursos, linguagens de programação integradas, dentre outros. Abaixo listamos algumas ferramentas disponíveis conforme o aspecto do preço.
Ferramentas pagas:
- Excel
- PowerBI
- Tableau
Ferramentas gratuitas:
- Shiny
- Plotly Dash
- Quarto
Exemplo aplicado: autosserviço de dados econômicos usando o Shiny
Nessa seção apresentamos um exemplo de autosserviço de análise de dados no contexto de análise de conjuntura de dados econômicos do Brasil. O objetivo é demonstrar uma ferramenta simples que permita acompanhar e analisar a macroeconomia nacional. Para tal fim utilizamos a biblioteca Shiny, que permite desenvolver dashboards interativas com facilidade.
Os dados e indicadores que a dashboard disponibiliza para análise se dividem em temas:
- Atividade Econômica: PIB (CNT) e Pesquisa Mensal de Comércio (PMC);
- Mercado de Trabalho: Taxa de Desemprego (PNAD) e Saldo de Empregos (CAGED);
- Inflação: Taxa de Inflação (IPCA) e Núcleos de Inflação (BCB).
Note que estes são apenas alguns dos temas e indicadores pertinentes de conjunta econômica. Limitamos a esta seleção para que o exemplo seja simples de entender. Para saber mais sobre veja o curso de Análise de Conjuntura da Análise Macro.
A dashboard desenvolvida em Shiny conta com as seguintes opções de interação:
- Seleção de tema de análise de conjuntura;
- Seleção de pesquisa/indicador;
- Filtro temporal;
- Opção de modo de exibição de gráficos
Estes são elementos simples e básicos para a maioria das dashboards e customizações adicionais podem ser implementadas.
O código em R e Python disponibilizado no Clube AM gera um exemplo de dashboard Shiny para análise conjuntural dos dados brasileiros. Para entender todos os detalhes do código, confira o curso de Produção de Dashboards da Análise Macro.
O resultado desse código é a dashboard da imagem abaixo:
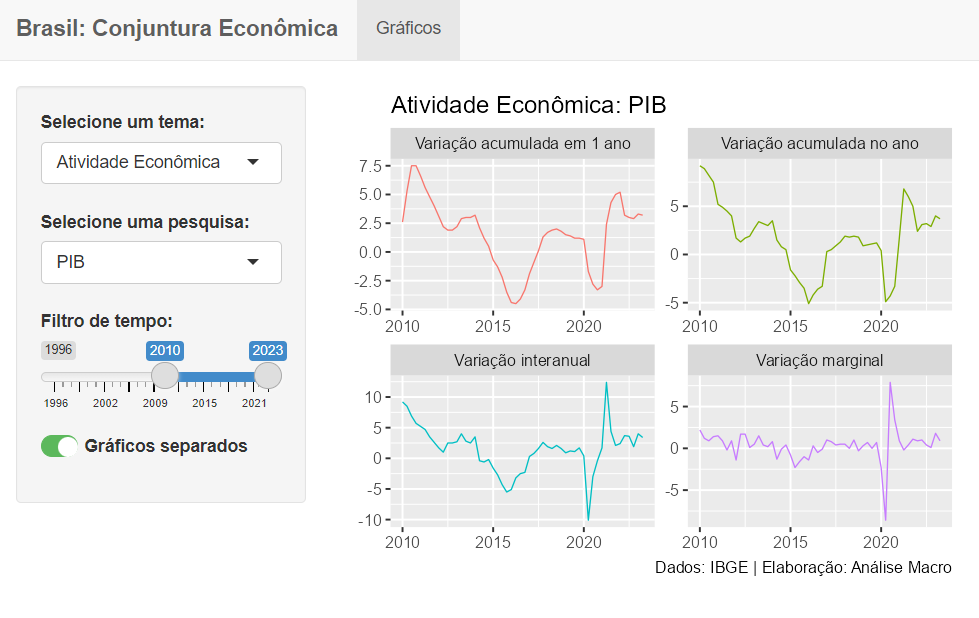
- Python: https://analisemacro.shinyapps.io/autosservico_py/
- R: https://analisemacro.shinyapps.io/autosservico_r/
Note que a dashboard é bastante simples e limitada, havendo bastante espaço para melhorias, porém já entrega a proposta de autosserviço de análise de dados, pois:
- O usuário consegue identificar a tendência dos indicadores;
- O usuário pode selecionar o indicador desejado;
- O usuário controla o período que quer analisar os dados;
- O usuário é capaz de alterar a interface de exibição.
Conclusão
Nesse artigo apresentamos o conceito de autosserviço de análise de dados, discutimos as vantagens e desvantagens destas ferramentas e mostramos um exemplo aplicado, em R e Python, com dados econômicos usando a biblioteca Shiny.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

