Dia de decisão da taxa de juros Selic é dia de muita expectativa. Além do valor numérico dos juros, o comunicado textual da decisão do COPOM pode apresentar conteúdo informacional relevante para estratégias de investimentos. Como diria o provérbio, “o diabo mora nos detalhes” e as entrelinhas dos comunicados da autoridade monetária costumam revelar sinalizações mais importantes do que a decisão de juros em si.
Neste espaço já exploramos a análise de sentimentos, a modelagem de tópicos e a previsão com dados textuais no contexto de comunicação de Bancos Centrais. Apesar de serem aplicações interessantes de text mining, geralmente requerem procedimentos que podem ser onerosos ou complexos em excesso.
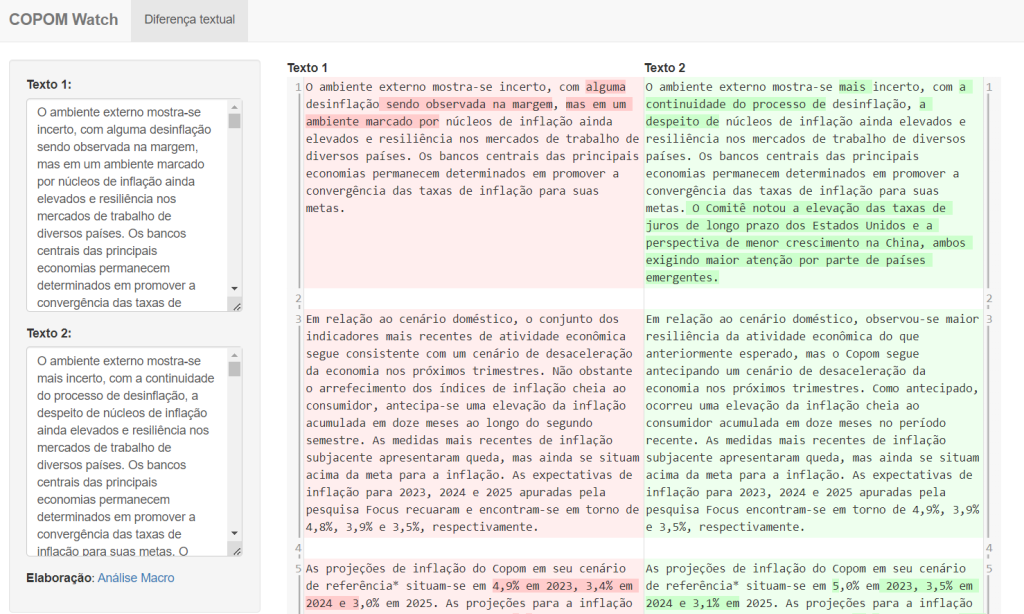
Hoje apresentaremos uma solução simples de análise textual dos comunicados do COPOM. A ideia é construir um aplicativo Shiny que permita comparar diferenças entre dois textos, destacando as mudanças. Como os comunicados são padronizados, com essa ferramenta é possível rapidamente avaliar mudanças de posicionamento e condução da política monetária.
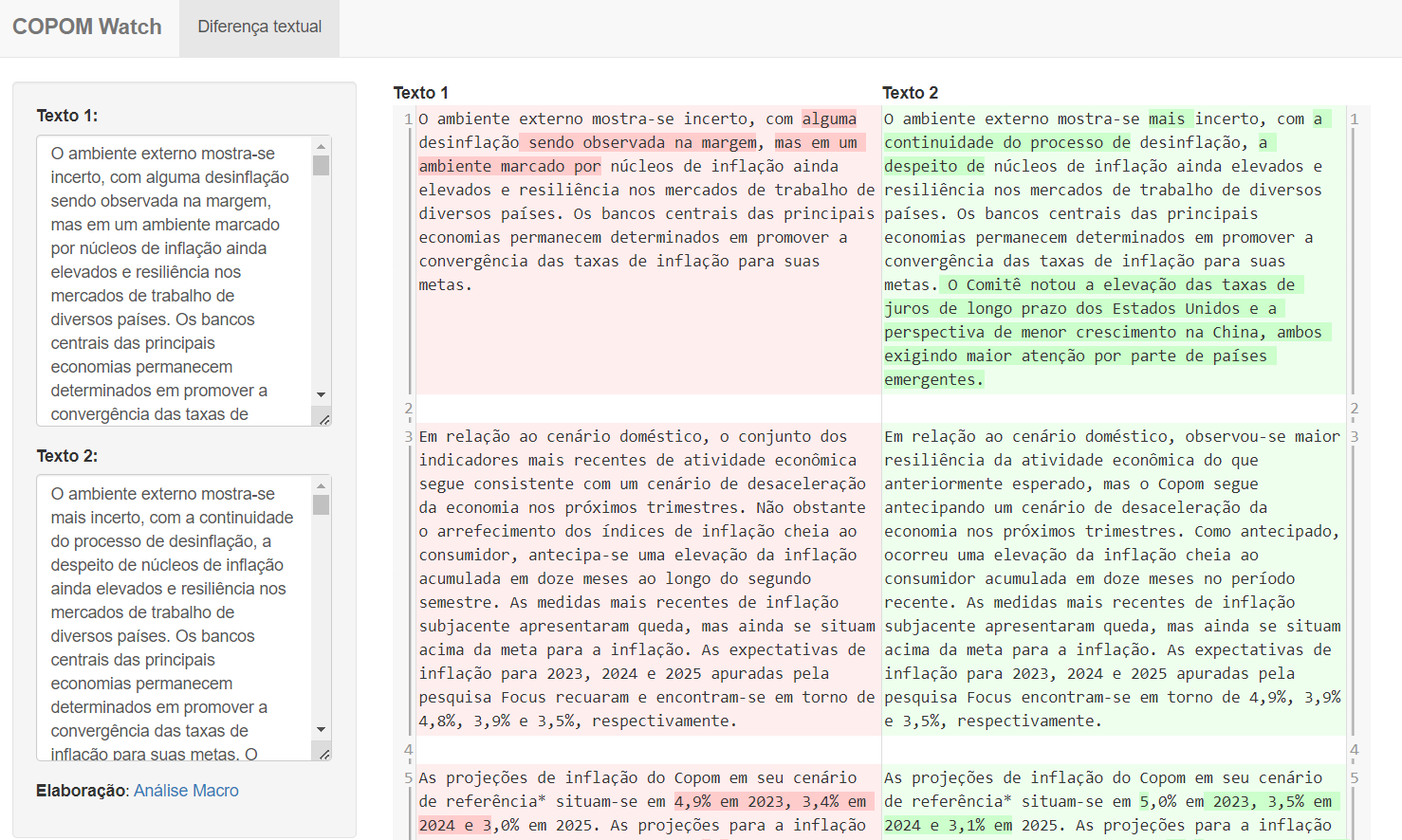
Acesse o aplicativo Shiny: https://analisemacro.shinyapps.io/copomwatch_py/
O que é Shiny?
Shiny é uma ferramenta para desenvolvimento de dashboards e aplicativos web interativos, como o exemplo acima, implementada em R e Python. Com ele é possível analisar dados de maneira interativa sem precisar escrever uma linha de HTML, CSS ou JavaScript.
Em termos simples, o Shiny é composto por dois componentes:
- Interface do usuário: é a parte visual que está aos olhos do usuário, ou seja, layout, botões, campos, gráficos, tabelas, cores e outros.
- Lógica do servidor: é a parte de código que é executada para a dashboard ser interativa, ou seja, é o código executado quando o usuário clica em um botão e um gráfico se atualiza, por exemplo.
A união destes dois componentes forma uma dashboard ou aplicativo web interativo. Para saber mais sobre Shiny e conferir mais exemplos, dê uma olhada no curso de Produção de Dashboards da Análise Macro.
App Shiny de Análise Textual do COPOM
Agora vamos entender como construir o aplicativo Shiny do exemplo acima para analisar os comunicados do COPOM.
Para organizar o código deste projeto estamos utilizando a seguinte estrutura de arquivos:
.
├── app.py
├── comunicado256.txt
└── comunicado257.txtOnde o primeiro arquivo armazena os códigos em Shiny e os demais arquivos de texto armazenam os últimos comunicados do COPOM para exemplificar a aplicação.
Interface do Usuário
Começamos definindo o primeiro componente do aplicativo Shiny: a interface visual.
Utilizamos o tipo de página “navbar” para criar um layout de páginas de navegação e definimos na interface dois painéis: o painel da barra lateral com campos de entrada textual e o painel principal com visualização textual (resultado da comparação).
Lógica do Servidor
Prosseguimos definindo o segundo componente do aplicativo Shiny: o código de servidor.
Aqui definimos um retorno textual da aplicação para ser exibido no painel principal. Esse código é executado toda vez que os campos de entrada textual mudarem. A função txt_highlighter() faz todo o trabalho de comparar os dois textos e gerar a visualização com destaques.
Resultado final
Unindo a interface visual com a lógica do servidor chegamos na aplicação Shiny, que pode ser visualizada localmente com o comando abaixo.
Conclusão
Tomar decisões rápidas com novas informações no mercado, especialmente em dia de COPOM, pode ser decisivo para estratégias bem sucedidas. Nesse artigo mostramos como analisar o texto da decisão de juros básico da economia, a Selic, usando a ferramenta Shiny.
Quer aprender mais?
- Cadastre-se gratuitamente aqui no Boletim AM e receba toda terça-feira pela manhã nossa newsletter com um compilado dos nossos exercícios com exemplos reais de análise de dados envolvendo as áreas de Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas;
- Quer ter acesso aos códigos, vídeos e scripts de R/Python desse exercício? Vire membro do Clube AM aqui e tenha acesso à nossa Comunidade de Análise de Dados;
- Quer aprender a programar em R ou Python com Cursos Aplicados e diretos ao ponto em Data Science, Econometria, Machine Learning, Macroeconomia Aplicada, Finanças Quantitativas e Políticas Públicas? Veja nossos Cursos aqui.

