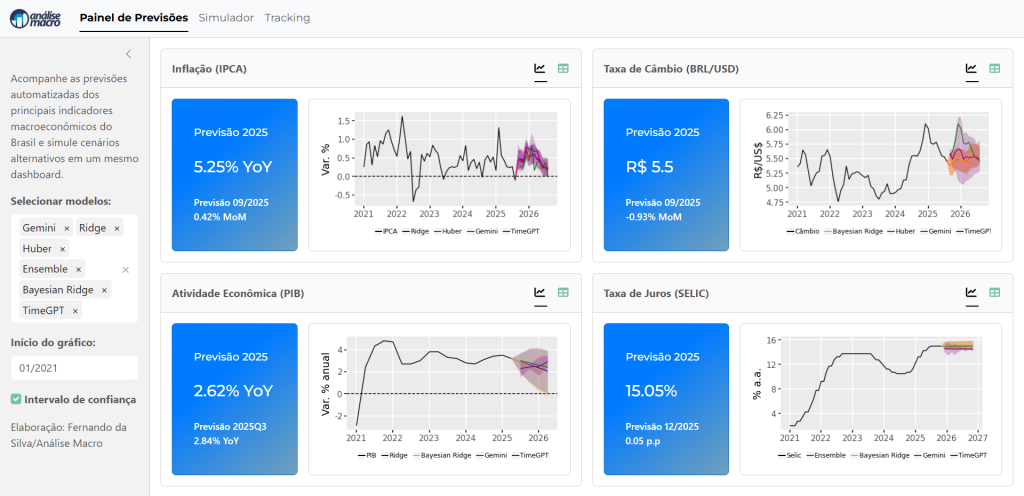
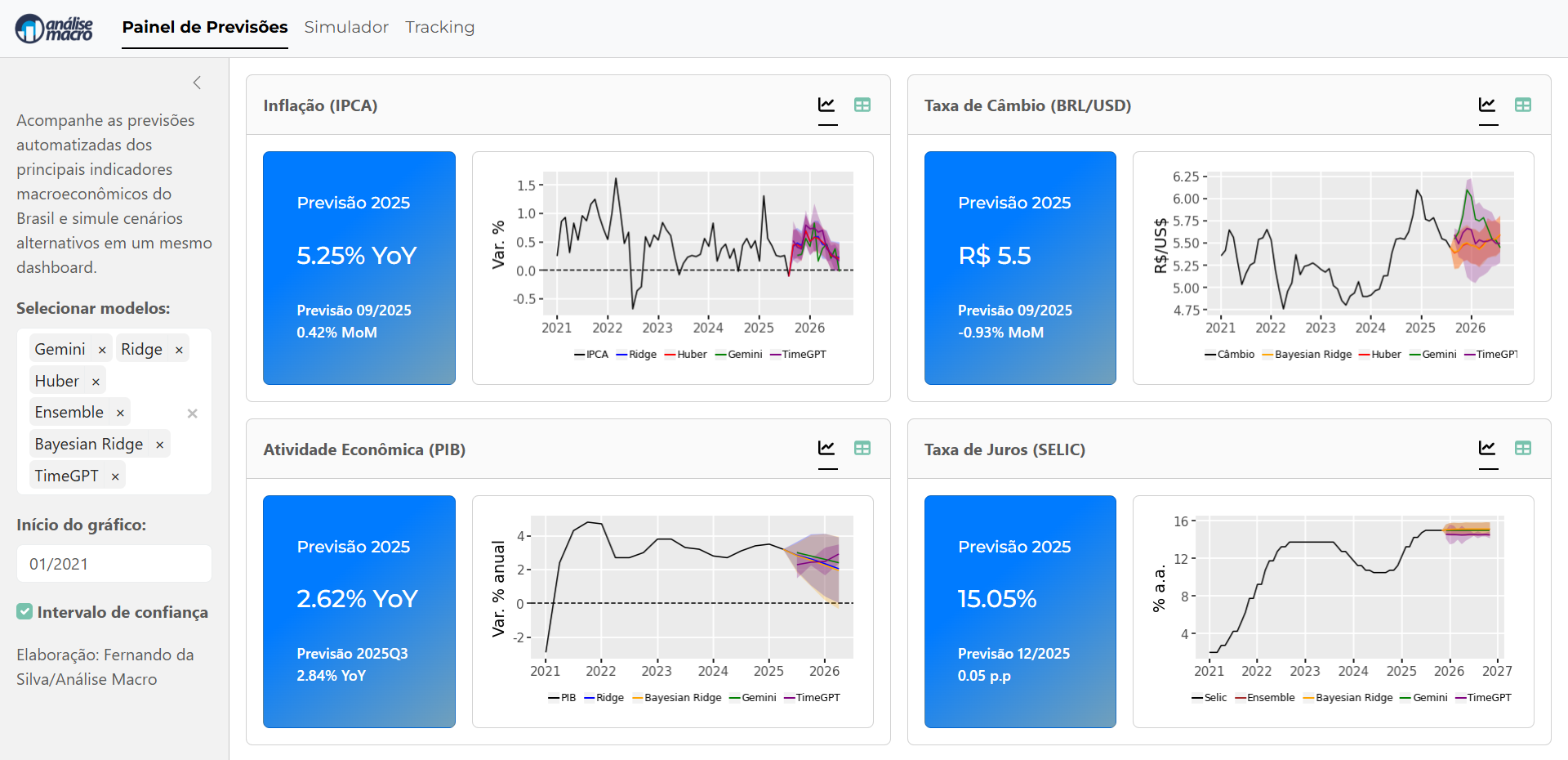
Quem trabalha com modelagem e previsão macroeconômica sabe o quanto é demorado reunir dados de diferentes fontes — Banco Central, IBGE, IPEA, FRED, IFI... Cada um com sua API, formato, frequência e estrutura. Esse gargalo de coleta e padronização consome tempo que poderia estar sendo usado na análise, nos modelos ou na comunicação dos resultados.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
Foi exatamente por isso que criamos uma rotina de coleta automatizada, que busca, trata e organiza séries temporais econômicas diretamente das APIs oficiais, pronta para ser integrada a pipelines de previsão, dashboards ou agentes de IA econometristas.
Como funciona a automação
Na Imersão Econometria vs. IA na Previsão Macro, você vai ver na prática como conectar dados de várias fontes públicas e manter tudo atualizado com apenas alguns comandos Python.
O código utiliza uma planilha de metadados centralizada, onde cada série tem seu identificador, fonte e frequência (Diária, Mensal, Trimestral, etc.). A partir dela, as funções de coleta percorrem automaticamente cada API:
-
BCB/SGS – coleta séries econômicas via
https://api.bcb.gov.br/ -
BCB/ODATA – acessa previsões e estatísticas como Focus e Selic
-
IPEADATA – integra séries históricas de indicadores fiscais, PIB e mercado de trabalho
-
IBGE/SIDRA – traz dados das pesquisas econômicas e sociais com tratamento automático de valores faltantes
-
FRED/IFI – amplia o contexto internacional e insere indicadores de hiato do produto
Cada função é projetada para lidar com falhas de rede, intervalos de datas extensos e diferenças de formato, garantindo resiliência e replicabilidade — algo essencial em pipelines de produção de dados.
O que você vai aprender na imersão
Durante a imersão, você verá passo a passo:
-
Como estruturar uma planilha de metadados para automatizar a coleta de dados macroeconômicos;
-
Como usar APIs públicas (BCB, IBGE, IPEA) de forma robusta;
-
Como integrar tudo em um data lake econômico pronto para modelagem;
-
E como esse pipeline serve de base para comparar modelos de Econometria, Machine Learning e Inteligência Artificial na previsão de variáveis macro.
Por que isso importa
Automatizar a coleta e integração de dados é o primeiro passo para escalar previsões macroeconômicas e construir agentes de IA econometristas capazes de aprender continuamente.
Em vez de gastar horas baixando planilhas e limpando dados, você foca no que realmente gera valor: modelar, interpretar e decidir.
👉 Quer aprender a criar seu próprio pipeline econômico automatizado e comparar modelos econométricos e de IA?
Inscreva-se na Imersão “Econometria vs. IA na Previsão Macro” e dê o próximo passo rumo à previsão inteligente.

