Criar gráficos padronizados usando pipelines com o tidyverse no R não precisa ser uma tarefa tediosa de Ctrl+C / Ctrl+V mudando a variável de interesse a ser plotada no seu código de ggplot2. Isso torna o seu script caótico e ineficiente, além de ser potencialmente mais trabalhoso fazer atualização/manutenção desse código.
Uma maneira mais elegante de criar gráficos padronizados, para um relatório por exemplo, pode ser através da escrita de uma função que generaliza o resultado que se quer alcançar. Vamos supor que você queira gerar gráficos de linha padronizados em um relatório extenso. Cada uma das várias visualizações de dados do seu relatório terá um gráfico de linha do ggplot2 para as n variáveis do seu conjunto de dados. Nesta situação, a criação de uma função se encaixa perfeitamente, pois irá unificar em um único comando tudo o que você precisa fazer para todas as visualizações a serem geradas, sem precisar repetir código.
Em termos mais práticos, um exemplo desta situação pode ser código abaixo, onde demonstramos um exemplo bom (usando boas práticas de programação em R) e um exemplo ruim (repetindo manualmente o código).
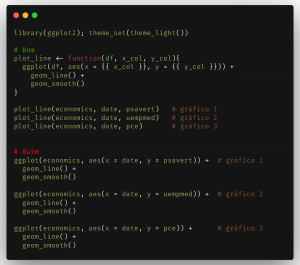
A diferença é bastante clara e significativa, o que você acha melhor? Ambas opções produzem os mesmos resultados gráficos:
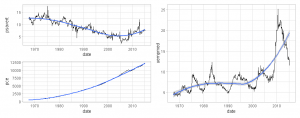
O "pulo do gato" aqui, no caso da criação da função plot_line, é utilizar o operador chamado curly-curly para passar os nomes das colunas do objeto data frame diretamente nos argumentos da função que criamos, usando a sintaxe {{ func_arg }} no corpo da função (neste caso em aes). O trabalho "sujo" de identificar corretamente o nome de coluna passado no argumento da função é feito todo internamente por esse operador.
Esse operador se originou em 2019 no pacote rlang e é bastante utilizado internamente nas funções do tidyverse. Se você quiser entender mais a fundo seu funcionamento sugiro começar por este post do blog do tidyverse.
Se mesmo após este exemplo básico você não se convenceu, dê uma olhada na diferença de performance (execução em milissegundos) dos dois códigos após 1000 execuções:
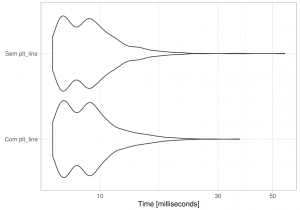
As inovações do tidyverse são maravilhosas e facilitam o dia a dia do usuário de R. Espero que este tenha sido um exercício que instigue curiosidade em investigar se seus códigos performam bem e seguem boas práticas.
________________________
(*) Para entender mais sobre a linguagem R e suas ferramentas, confira nosso Curso de Introdução ao R para análise de dados.

