No Hackeando o R de hoje, vamos mostrar métodos diferentes de visualizar dados distribuídos em categorias. Os dados utilizados no exemplo serão do dataset Titanic, disponível no R base.
ftable(Titanic)

A tabela acima é perfeitamente válida para acessarmos os dados conforme a necessidade. Apesar disso, a comparação entre linhas e suas subdivisões pode levar algum tempo, de modo que a criação de gráficos se justifica como método de facilitar a compreensão dos dados. Uma visualização inicial que podemos fazer é conferir o número de pessoas no navio por sexo. Para isso, um gráfico de barras simples é válido:
library(ggplot2) df_titanic <- as.data.frame(Titanic) ggplot(df_titanic, aes(x=Sex, y= Freq)) + geom_bar(stat = 'identity') + labs(x='Sexo', y = 'Número de pessoas') + theme_minimal()
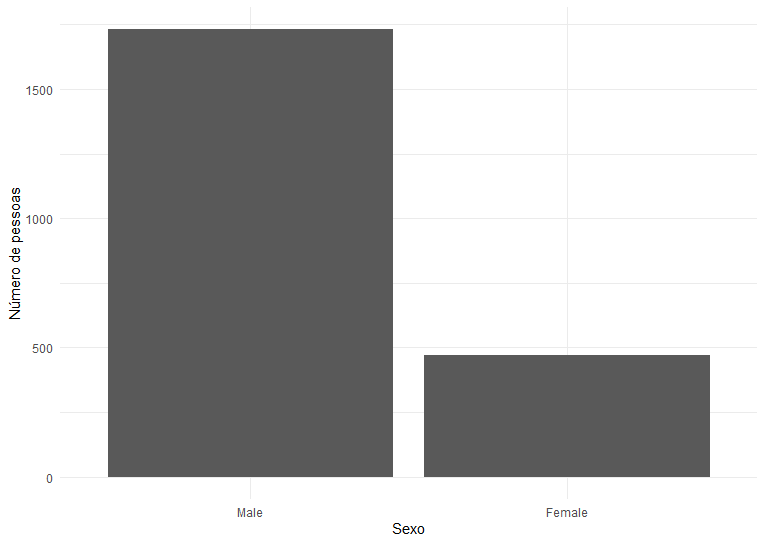
A partir desse gráfico, uma expansão simples é dividir as pessoas entre quem sobreviveu ou não. Para isso, basta adicionar um fill:
ggplot(df_titanic, aes(x=Sex, y= Freq, fill = Survived)) + geom_bar(stat = 'identity', position = position_dodge()) + labs(x='Sexo', y = 'Número de pessoas') + theme_minimal()

A inclusão das barras separadas já traz resultados interessantes, mostrando que a maior parte das mulheres sobreviveram, enquanto a taxa de sobrevivência para homens ficou abaixo de 25%. No código do gráfico, utilizamos o argumento position_dodge, que deixa as colunas de cada grupo organizadas horizontalmente, tornando a comparação entre número de sobreviventes para cada sexo rápida, pois basta comparar o nível no eixo y para cada cor. Agora, vamos separar os grupos entre classes, para verificar disparidades entre grupos diferentes de pessoas no navio:
ggplot(df_titanic, aes(x=Sex, y= Freq, fill = Survived)) + geom_bar(stat = 'identity', position = position_dodge()) + labs(x='Sexo', y = 'Número de pessoas') + facet_wrap(~Class) + theme_minimal()
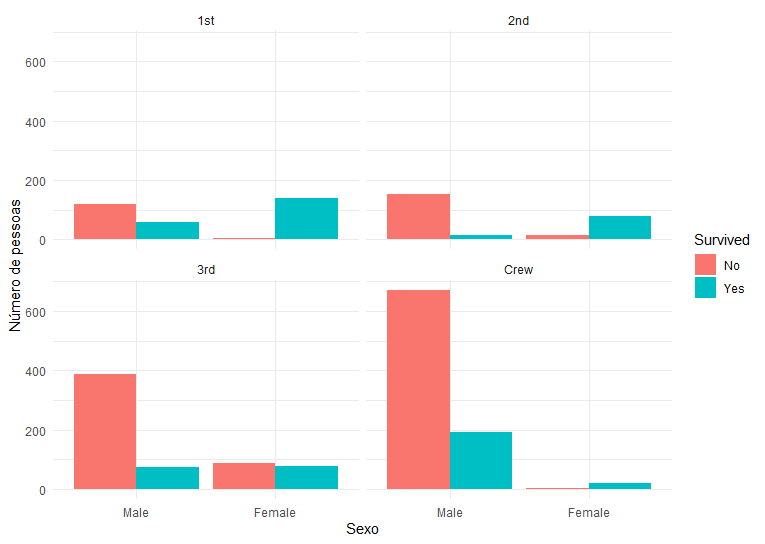
A separação indica que quase nenhuma mulher na primeira classe morreu, e quase nenhum homem da segunda classe sobreviveu. A escala de todos os gráficos é idêntica por padrão, o que pode ou não ser justificável, dependendo do tipo dos dados utilizados. No nosso caso, é importante manter tal configuração, pois permite a comparação entre classes diferentes. A última informação que podemos adicionar é a separação entre idades. Para fazer isso, vamos adicionar linhas que indicam a idade (criança ou adulto), gerando subdivisões das divisões originais. A função utilizada está disponível no pacote ggpattern.
#remotes::install_github("coolbutuseless/ggpattern")
library(ggpattern)
ggplot(df_titanic, aes(x=Sex, y= Freq, fill = Survived)) + geom_bar(stat = 'identity', position = position_dodge()) +
geom_col_pattern(
aes(Sex, Freq, pattern_fill = Age, fill = Survived),
color = 'black'
) +
labs(x='Sexo', y = 'Número de pessoas') + facet_wrap(~Class) + theme_minimal()

O resultado indica que quase todas as crianças foram salvas. Podemos variar as opções do geom_col_pattern, porém a visualização já se torna complicada pois é difícil incluir tantos detalhes em um gráfico de barras. Outra opção seria quebrar o gráfico em múltiplas categorias com o facet_wrap, porém rapidamente temos um número grande de gráficos pequenos, difíceis de comparar entre si. Uma solução que iremos apresentar aqui é a introdução de gráficos de mosaico, com o pacote vcd. A ideia de um gráfico desse tipo é utilizar os 4 lados dele como eixos, permitindo a análise de múltiplas categorias de modo conciso. Para utilizarmos a função mosaic(), os dados devem ser um array de categorias.
library(vcd) mosaic(Titanic, shade = TRUE)
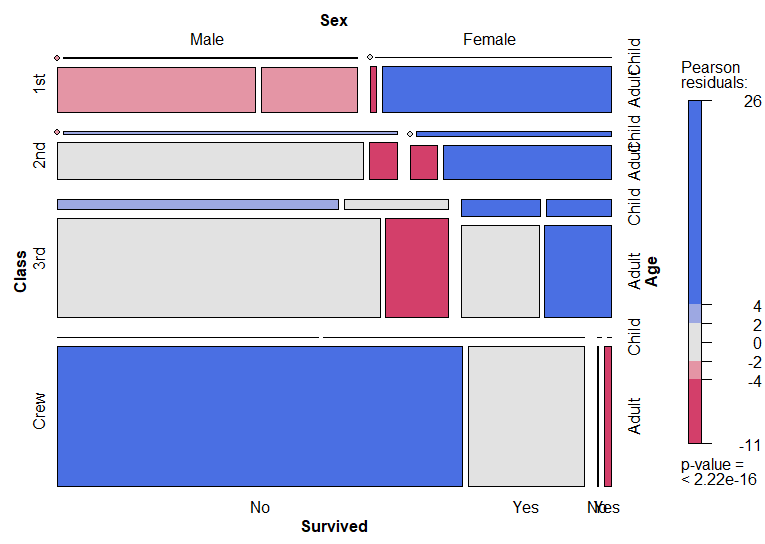
Cada retângulo do gráfico acima é facilmente identificado analisando cada um dos 4 eixos, e a comparação de tamanho entre os grupos é facilitada pois estão próximos em um mesmo gráfico. Ademais, as cores geradas são o resultado de um teste estatístico que verifica se a distribuição da amostra é independente dos atributos, sendo setores azuis estatisticamente acima do esperado, e vermelhos abaixo. O resultado indica que há muito mais tripulantes que não sobreviveram do que ocorreria se fossem salvas pessoas aleatórias, assim como muito mais mulheres foram salvas. Por outro lado, menos homens da primeira classe foram salvos do que esperado.


