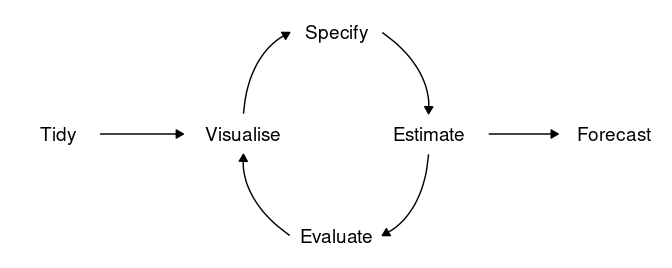
Produzir modelos preditivos para séries temporais é uma tarefa difícil e bastante valorizada no mercado de trabalho. São diversos os procedimentos que um profissional dessa área precisa sempre ter no radar e, se generalizarmos isso em um fluxo, a distância entre a idealização do modelo e sua implementação pode ser mais curta e menos árdua. Neste texto descrevemos resumidamente o dia a dia de um profissional que trabalha com previsões e mostramos um exemplo de rotinas em R!
Fluxo de trabalho
O processo de desenvolver modelos preditivos para séries temporais pode ser generalizado e dividido em 6 etapas:
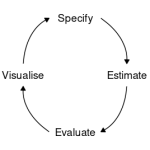
Fonte: Hyndman and Athanasopoulos (2021)
Este fluxo, em resumo, descreve como é o dia a dia de trabalho de modelagem e previsão em algumas etapas organizadas. São elas:
Preparar os dados
O primeiro passo é preparar os dados no formato correto para uso em modelos. Esse processo pode envolver a coleta e importação de dados, a identificação de valores ausentes, agregação/sumarização/ajustes/filtros nas séries e outras tarefas de pré-processamento (veja um post sobre coleta de dados aqui). O objetivo será, em geral, construir uma matriz de variáveis onde cada variável terá sua própria coluna, cada linha formará uma observação e os valores são armazenados nas células. Esse é o princípio de dados "tidy". A facilidade que o pacote {tsibble} e outros do {tidyverse} oferecem simplifica consideravelmente esta etapa usando o R.
Vale dizer que muitos modelos têm pressupostos e requisitos diferentes, sendo que você precisará levar isso em consideração ao preparar os dados. Alguns exigem que a série seja estacionária, outros exigem que não haja valores ausentes. Dessa forma, você precisará conhecer bem os seus dados enquanto os prepara e a análise exploratória é outra etapa que caminhará lado a lado.
Visualizar os dados
A visualização é uma etapa essencial para a compreensão dos dados. Suas séries temporais apresentam tendência? Possuem sazonalidade? Há quebras ou observações extremas nas séries (outliers)? Observar seus dados, através de uma análise exploratória (veja um post sobre aqui no blog) permite identificar estes padrões comuns e, posteriormente, especificar um modelo apropriado. Essa etapa pode andar em conjunto com a etapa de preparação dos dados, de modo que após entender os dados você talvez precise voltar a um passo anterior e aplicar uma transformação, por exemplo, nas séries. Os pacotes {ggplot2}, {feasts}, {fabletools} e outros oferecem formas elegantes e práticas de visualizar seus dados.
Definir o modelo
Existem muitos modelos de séries temporais diferentes que podem ser usados para previsão. Especificar um modelo apropriado para os dados é essencial para produzir previsões. Nesse sentido, além de conhecer os seus dados você precisará ter conhecimento sobre os modelos que pretende trabalhar. Papers publicados são, em geral, boas fontes para buscar esse conhecimento técnico.
Grande parte dos modelos econométricos é descrita em Hyndman and Athanasopoulos (2021) e podem ser implementados pelo pacote {fable} através de funções específicas como ARIMA(), TSLM(), VAR(), etc., cada uma usando uma interface de fórmula (y ~ x). As variáveis de resposta são especificadas à esquerda da fórmula e a estrutura do modelo, que pode variar, é escrita à direita. Para outros modelos fora do escopo do {fable} a lógica e sintaxe é semelhante, quase sempre utilizando uma interface de fórmula.
Estimar o modelo
Uma vez que um modelo apropriado é definido, passamos à estimação do modelo com os dados. Uma ou mais especificações de modelo podem ser estimadas usando a função model() do pacote {fabletools} — framework que contempla grande parte dos modelos econométricos; para outros modelos há pacotes e funções específicas, mas com sintaxe semelhante.
Avaliar a performance
Após termos um modelo estimado, é importante verificar o desempenho dele nos dados. Existem várias ferramentas de diagnóstico disponíveis para verificar o ajuste do modelo, assim como medidas de acurácia que permitem comparar um modelo com outro; o RMSE é a métrica mais comumente utilizada para a maioria dos problemas de previsão. Conforme o diagnóstico do modelo, em seguida possivelmente sejam necessárias readequações, seja na especificação ou até mesmo nos dados utilizados. Em outras palavras, o fluxo de trabalho não é simplesmente um amontoado de procedimentos a serem implementados sequencialmente, mas sim um processo de descobrimento que envolve, na vida real, sucessivas tentativas e erros.
Além disso, se o interesse é previsão, há técnicas como a validação cruzada que auxiliam na tomada de decisão entre mais de um modelo (veja um post sobre isso aqui no blog). É sempre preferível ter mais de um modelo "candidato" potencialmente usado para fazer previsões, além de modelos básicos para simples comparação.
Realizar previsões
Com um modelo especificado, estimado e diagnosticado, é hora de produzir as previsões fora da amostra. Para alguns modelos você poderá simplesmente chamar uma função, como a forecast() ou predict() no R, especificando o número de períodos (horizonte de previsão) que deseja obter previsões; para outros você precisará prover uma tabela com os valores futuros das variáveis regressoras utilizadas no modelo, que servirá para produzir as previsões da variável de interesse, ou seja, você precisará de cenários.
Exemplo no R
Com esse esquema em mente, vamos ilustrar o fluxo de trabalho com um exercício prático e didático: construir um modelo de previsão para a taxa de crescimento anual do PIB brasileiro.
Para reproduzir o exercício a seguir você precisará dos seguintes pacotes:
Preparar os dados
Por conveniência, utilizaremos o dataset global_economy armazenado como um objeto tsibble, trazendo variáveis econômicas em frequência anual para diversos países. Nosso interesse é a série da taxa de crescimento do PIB brasileiro:
Visualizar os dados
Visualização é uma etapa essencial para entender os dados, o que permite identificar padrões e modelos apropriados. No nosso exemplo, primeiro criamos um gráfico de linha para plotar a série do PIB brasileiro usando a função autoplot():
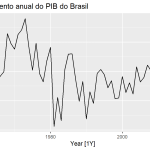
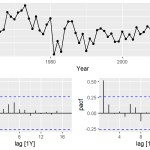
Podemos também plotar os correlogramas ACF e PACF para identificar o processo estocástico da série, obtendo alguns modelos candidatos:
Definir o modelo
Existem muitos modelos de séries temporais diferentes que podem ser usados para previsão, e especificar um modelo apropriado para os dados é essencial para produzir previsões. Nesse exercício didático focaremos em modelos univariados simples para explicar o PIB brasileiro.
Se formos analisar somente pelos correlogramas ACF e PACF, podemos identificar alguns modelos possivelmente candidatos: ARIMA(1,0,2), ARIMA(1,0,0) e ARIMA(0,0,2). Contudo, se nossa leitura estiver incorreta, podemos contar ainda com a tecnologia ao nosso favor utilizando a seleção automatizada da estrutura do modelo. Isso é possível graças ao algoritmo de seleção automatizada da especificação do ARIMA criado pelo prof. Rob Hyndman.
Por fim, além destes possíveis modelos candidatos, também estimaremos um modelo de benchmark na forma de um passeio aleatório, apenas para ter uma base de comparação de previsões dos modelos.
Estimar o modelo
Identificado um modelo (ou mais) apropriado, podemos em seguida fazer a estimação usando a função model()1. Existem diversas funções especiais para definir a estrutura do modelo e em ambos os lados da fórmula podem ser aplicadas transformações. Nesse caso definiremos apenas a estrutura básica do ARIMA; a função ARIMA() também define automaticamente a estrutura sazonal, mas você pode desabilitar isso (consulte detalhes da documentação do {fable}).
O objeto resultante é uma "tabela de modelo" ou mable, com a saída de cada modelo em cada coluna.
Diagnóstico do modelo
Para obter os critérios de informação use a função glance():
Os critérios de informação indicam que, dos modelos estimados, o modelo automatizado ARIMA(1,1,1) apresentou o menor valor de AICc — seguido pelos demais identificados pelos correlogramas ACF e PACF. Com a função gg_tsresiduals() podemos verificar o comportamento dos resíduos deste modelo, indicando que os resíduos se comportam como ruído branco:
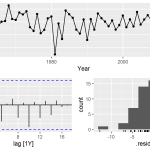
Um teste de autocorrelação (Ljung Box) retorna um p-valor grande, também indicando que os resíduos são ruído branco:
Também pode ser interessante visualizar o ajuste do modelo. Utilize a função augment() para obter os valores estimados:
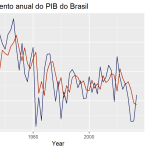
Outros diagnósticos e avaliações podem ser realizados. Se você estiver especialmente interessado em previsão, considere implementar o método de validação cruzada, como explicado neste post.
Realizar previsões
Com o modelo escolhido, previsões podem ser geradas com a função forecast() indicando um horizonte de escolha.
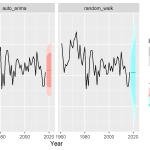
Perceba que os pontos de previsão médios gerados são bastante similares a um processo de passeio aleatório (equivalente a um ARIMA(0,1,0)). O trabalho adicional de especificar termos AR e MA trouxe pouca diferença para os pontos de previsão neste exemplo, apesar de ser perceptível que os intervalos de confiança do modelo auto ARIMA são mais estreitos do que de um passeio aleatório.
Além disso, a previsão fora da amostra gerada ficou bastante aquém dos dados reais para a taxa de crescimento do PIB brasileiro observados no horizonte em questão, configurando apenas um exercício didático.
Saiba mais
Este é apenas um exercício simples e didático demonstrando um fluxo de trabalho de modelagem e previsão. Existem diversos tópicos que podem ser aprofundados e se você quiser saber mais confira o curso de Modelos Preditivos da Análise Macro.
Confira também outros exercícios aplicados com pacotes do {tidyverts}:
- Gerando previsões desagregadas de séries temporais
- Como extrair componentes de tendência e sazonalidade de uma série temporal
- Como estimar modelos para múltiplas séries temporais ao mesmo tempo
Referências
Hyndman, R. J., & Athanasopoulos, G. (2021) Forecasting: principles and practice, 3rd edition, OTexts: Melbourne, Australia. OTexts.com/fpp3. Accessed on 2022-04-01.
1A função suporta estimação dos modelos com computação paralela usando o pacote {future}, veja detalhes na documentação e este post para saber mais sobre o tema.

