No mundo da ciência de dados aplicada à economia e finanças, somos constantemente bombardeados com os últimos modelos de "Inteligência Artificial" ou as mais novas técnicas econométricas. Mas há uma verdade inconveniente que muitos ignoram: nenhum modelo, por mais avançado que seja, sobrevive a dados ruins.
Para obter o código e o tutorial deste exercício faça parte do Clube AM e receba toda semana os códigos em R/Python, vídeos, tutoriais e suporte completo para dúvidas.
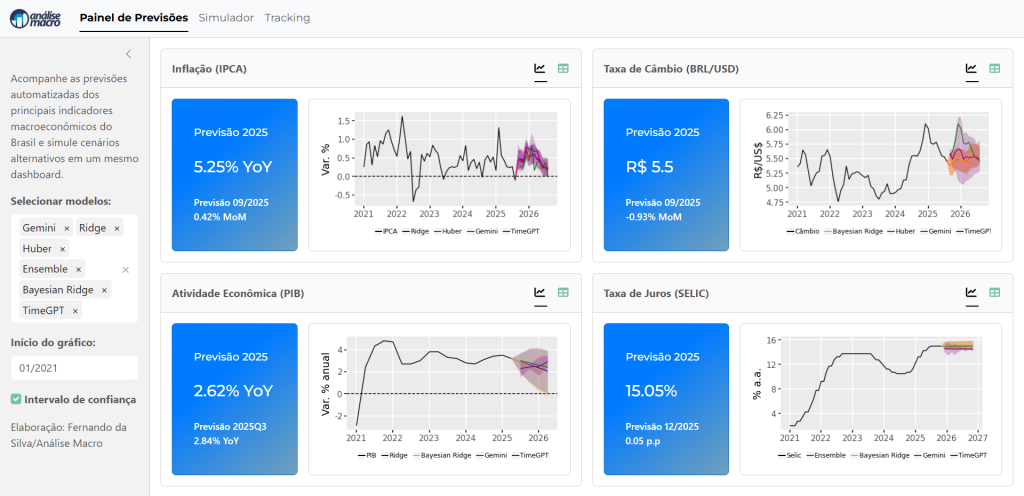
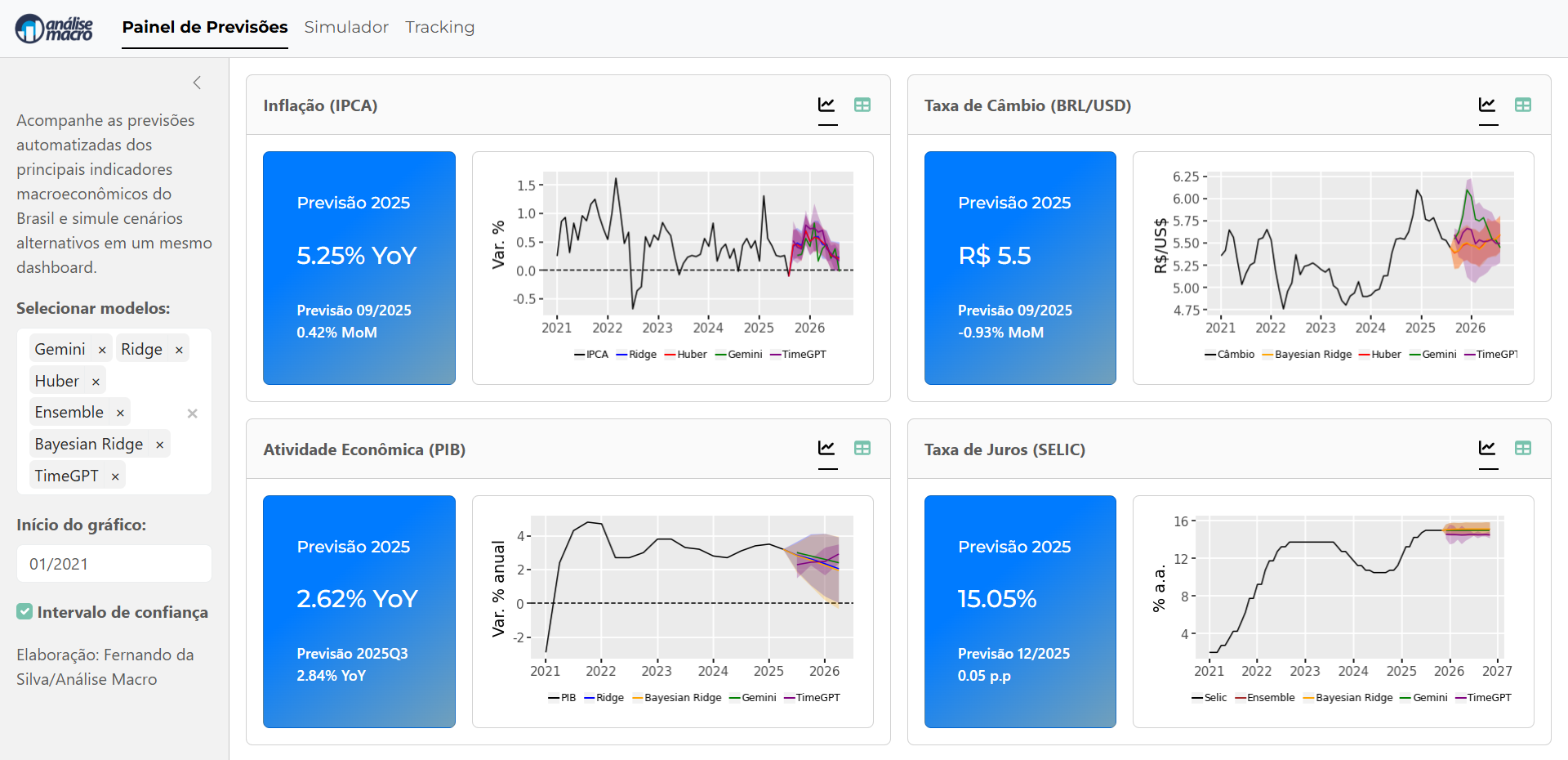
A previsão macroeconômica é um exemplo clássico. Para construir um dashboard robusto como o que estamos desenvolvendo em nossa imersão "Econometria vs. Inteligência Artificial na Previsão Macroeconômica", o trabalho mais pesado não está no model.fit(). Ele está na preparação dos dados.
Hoje, vamos mergulhar nos bastidores desse painel e focar em uma das aulas mais cruciais da imersão: o tratamento e a transformação de séries temporais. Usando os scripts de nosso projeto como guia, vamos ver como saímos de um emaranhado de fontes de dados para um dataset pronto para modelagem.
1. O desafio: um mar de fontes e frequências
O primeiro problema da análise macro é que os dados estão em toda parte. Em nosso projeto, por exemplo, nós coletamos dados de:
- BCB/SGS e BCB/ODATA (Banco Central do Brasil)
- IPEADATA (Instituto de Pesquisa Econômica Aplicada)
- IBGE/SIDRA (Instituto Brasileiro de Geografia e Estatística)
- FRED (Federal Reserve Bank of St. Louis)
- IFI (Instituição Fiscal Independente)
Esses dados chegam em frequências distintas: diária, mensal, trimestral e anual. Você não pode simplesmente jogar um IPCA (mensal) e um PIB (trimestral) no mesmo modelo sem um tratamento adequado.
2. A "faxina": agregação e harmonização
Aqui é onde a mágica começa, e o script de tratamento de dados é nosso mapa. A primeira etapa é a harmonização de frequência. Para nossos modelos mensais, precisamos que todos os dados estejam nessa granularidade.
Agregação por média vs. por posição
Para a maioria das séries diárias, como o câmbio ou índices de commodities, podemos simplesmente calcular a média mensal:
# Exemplo de agregação de diário para mensal
df_diario.resample("MS").mean()
Mas isso não vale para tudo. Veja o caso da taxa Selic. Em um modelo que usa a Selic como input, não queremos a "média" da Selic no mês, mas sim a taxa que estava vigente no início do mês (ou no fechamento do mês anterior). Nosso script de tratamento reflete esse conhecimento de negócio.
Tratando dados especiais: expectativas
Dados de expectativas, como os do Boletim Focus (coletados via BCB/ODATA), também exigem um tratamento especial. Não basta baixar a série. Precisamos filtrar pelo horizonte de previsão que nos interessa. Por exemplo, para "expectativas de curto prazo", filtramos apenas as previsões com horizonte de 1 mês à frente e depois calculamos a média para aquele mês.
3. A transformação: em busca da estacionariedade
Com os dados limpos, agregados e em uma única frequência, temos um novo desafio: a estacionariedade.
Muitos modelos econométricos e até mesmo algoritmos de machine learning assumem que a série temporal é estacionária (ou seja, sua média e variância não mudam ao longo do tempo). Um gráfico do PIB ou da taxa de câmbio mostra claramente que eles não são estacionários.
Para corrigir isso, aplicamos transformações. Em nosso script de modelagem, criamos uma função auxiliar para isso:
# Função para transformar dados
def transformar(x, tipo):
switch = {
"1": lambda x: x, # Nível
"2": lambda x: x.diff(), # 1ª Diferença
"3": lambda x: x.diff().diff(), # 2ª Diferença
"4": lambda x: np.log(x), # Log
"5": lambda x: np.log(x).diff(), # Log-diferença (taxa de crescimento)
"6": lambda x: np.log(x).diff().diff()
}
return switch[tipo](x)
4. O poder dos metadados
Aqui está o "pulo do gato" de um projeto bem-estruturado. Em vez de "chumbar" (hard-code) a transformação para cada variável em nosso script, nós usamos uma planilha de metadados centralizada (a mesma que usamos na etapa de coleta!).
Nessa planilha, para cada série, definimos qual é a transformação correta (ex: "5" para log-diferença). Nosso script de modelagem simplesmente lê esses metadados e aplica a transformação dinamicamente.
Isso torna o projeto incrivelmente modular. Se descobrirmos que uma transformação diferente é melhor, não precisamos mexer no código de modelagem, apenas atualizar uma célula na planilha.
Conclusão: pronto para modelar
Após todo esse processo, finalmente temos um dataset pronto. Passamos por:
- Coleta de dezenas de fontes.
- Harmonização de frequências diárias e trimestrais para mensais.
- Tratamento de casos especiais (Selic, Expectativas).
- Junção em um dataframe único por frequência.
- Transformação para garantir estacionariedade, de forma dinâmica via metadados.
Só agora podemos, com segurança, alimentar nossos modelos—sejam eles um Ridge (Econometria) ou Gemini e TimeGPT (Inteligência Artificial). Esse trabalho de base é o que separa uma análise amadora de um sistema de previsão profissional e automatizado, que é o objetivo final da nossa imersão.
Se você quer aprender como construir esse pipeline passo a passo, participe da Imersão “Econometria vs. IA na Previsão Macro”, onde exploramos detalhadamente a integração de modelos, APIs e dashboards automatizados aplicados à economia brasileira.

