Outubro termina com uma espécie de redenção na agenda econômica. Após mais de 20 anos e cinco presidentes, enfim, foi aprovada uma reforma no sistema público de previdência de grande envergadura. O resultado prático disso são dois. Primeiro, deve haver alguma contaminação em indicadores macro e financeiros desse grande evento - ainda que boa parte já tenha sido antecipada. Segundo, a agenda parlamentar fica aberta para mares nunca antes navegados, como a reforma tributária e a administrativa.
Nesse comentário de conjuntura, por suposto, gostaria de avaliar o comportamento de quatro variáveis: taxa de câmbio R$/US$, Ibovespa, CDS 5 anos e CRB. Os três primeiros são afetados de forma direta pela agenda econômica, de modo que é esperado alguma contaminação sobre eles da aprovação da reforma da previdência. O quarto eu coloco como uma espécie de controle, dada a influência do mesmo sobre a taxa de câmbio.
Antes de mais nada, vamos carregar alguns pacotes...
library(quantmod) library(ggplot2) library(scales) library(forecast) library(readr) library(xts) library(gridExtra)
E abaixo eu importo os dados para o RStudio...
## Pegar dados
getSymbols("BRL=X",src="yahoo", from='2019-06-02')
getSymbols("^BVSP",src="yahoo", from='2019-06-02')
cds = read_csv2('cds.csv', col_types = list(col_date(format='%d/%m/%Y'),
col_double()))
crb = read_csv2('crb.csv', col_types = list(col_date(format='%d/%m/%Y'),
col_double()))
Os dados do câmbio e do ibovespa eu pego do yahoo finance com o pacote quantmod enquanto os dados do CDS e do CRB de um arquivo csv usando o pacote readr. Abaixo, um tratamento rápido dos dados.
cambio = `BRL=X`[,4]
ibov = BVSP[,4]
cds = window(xts(cds$cds5y, order.by = cds$date), start='2019-06-02')
crb = window(xts(crb$crb, order.by = crb$date), start='2019-06-02')
data = cbind(cambio, ibov, cds, crb)
data = data[complete.cases(data)]
colnames(data) = c('cambio', 'ibov', 'cds', 'crb')
Com os dados prontos, meu objetivo é construir uma espécie de painel com o gráfico das quatro variáveis. Isso pode ser feito com a combinação de quatro pacotes: ggplot2, forecast, scales e gridExtra. Abaixo, crio e guardo o gráfico da primeira variável.
g1 = autoplot(cambio)+
scale_x_date(breaks = date_breaks("15 days"),
labels = date_format("%d/%b"))+
theme(axis.text.x=element_text(angle=45, hjust=1),
plot.title = element_text(size=10))+
labs(x='', y='R$/US$',
title='Taxa de Câmbio R$/US$ diária')
O código é idêntico para as demais variáveis, então não os repito aqui. Uma vez construídos e guardados os objetos, posso gerar meu painel com a função grid.arrange do pacote gridExtra como abaixo.
grid.arrange(g1, g2, g3, g4, ncol=2, nrow=2, bottom='Fonte: Yahoo Finance e Bloomberg')
E aí está o gráfico...
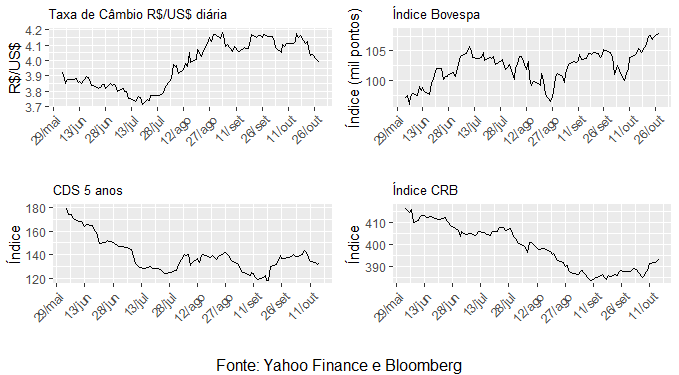
Podemos observar na ponta um recuo do câmbio para próximo a 4 R$/US$ e um avanço do índice Bovespa para recordes históricos. Já o CDS 5 anos recuou no período selecionado, o mesmo comportamento registrado para o CRB. A agenda econômica pró-reformas traz um alento para o país em um momento bastante delicado no cenário internacional, marcado por riscos consistentes de uma desaceleração global. Algo que obviamente tem impacto nas variáveis aqui selecionadas.
________________________
(*) Saiba coletar e tratar dados macroeconômicos com o nosso Curso de Análise de Conjuntura usando o R.
(**) Agradeço ao meu amigo Sávio Barbosa, da Paineiras Investimentos, por disponibilizar os dados do CDS5Y e do CRB.


