A inflação é conhecida como o termo que representa a taxa de crescimento do nível geral de preços entre dois períodos distintos. No Brasil, o indicador que consolidou-se como o principal índice de preços é o Índice de Preços ao Consumidor Amplo (IPCA), divulgado pelo IBGE e amplamente utilizado pela autoridade monetária como referência para realizar o controle da inflação. No post de hoje, mostraremos como podemos realizar a importação dos dados do IPCA e visualizar como forma de obter um análise.
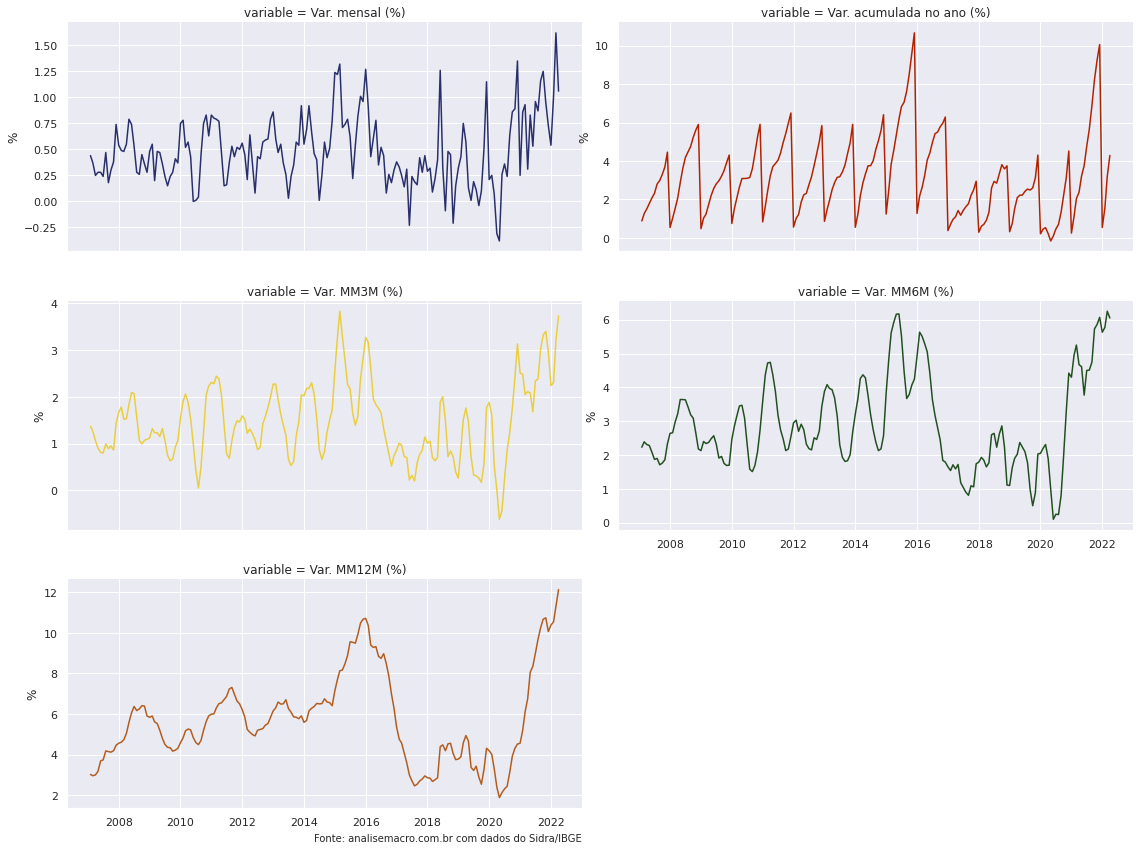
O IPCA é divulgado mensalmente pelo IBGE, portanto, podemos importar diretamente do SIDRA os dados do indicador utilizando a biblioteca {sidrapy}. Primeiro, iremos buscar a série que diz respeito a variação mensal, acumulada em 3 meses, acumulada em 6 meses, acumulada em 12 meses e acumulado no ano, que diz respeito a tabela 1737.
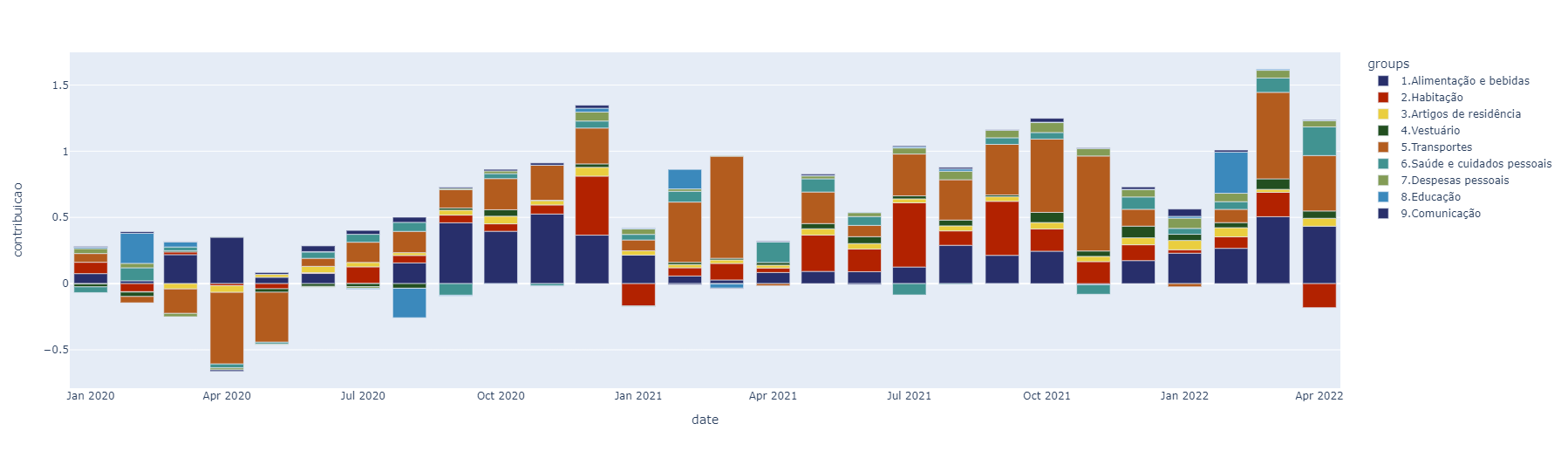
Em um segundo momento, buscaremos a série de pesos e variação de cada grupo do IPCA, e veremos a contribuição de cada grupo sobre o IPCA, através da tabela 7060.
Para importar as séries com a função get_table do {sidrapy}, buscamos a API das tabelas, com os parâmetros configurados, de forma a obter os códigos. Ensinamos este processo em um post anterior: Coletando dados do SIDRA com o Python.
Variações do IPCA: tabela 1737
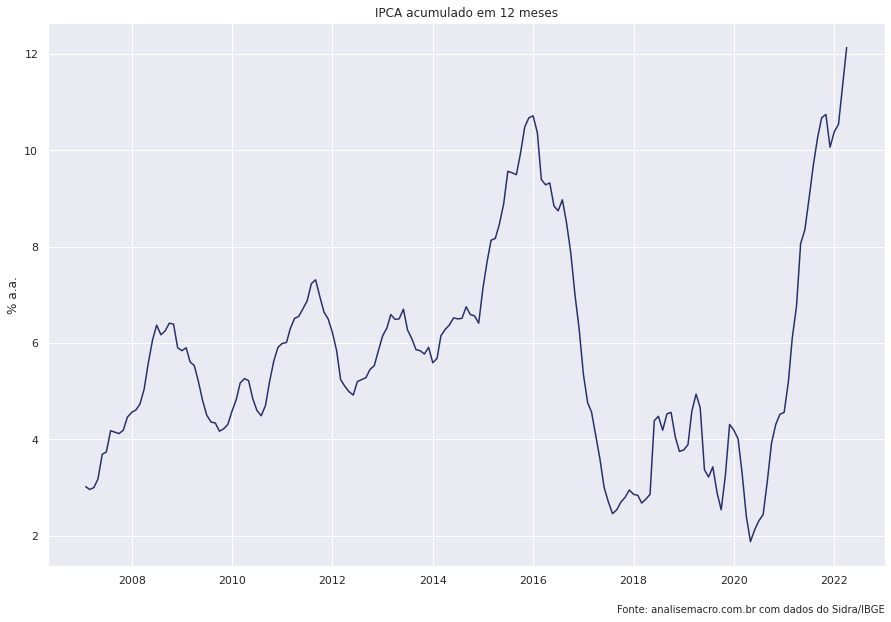
IPCA Contribuição por grupo: tabela 7060
Quer saber mais?
Veja nossos cursos de Macroeconomia através da nossa trilha de Macroeconomia Aplicada.

