Mercado de crédito
O Mercado de crédito compreende-se como um sistema no qual ocorrem trocas financeiras, visando repassar o dinheiro dos poupadores para os tomadores. Esse mercado tem uma importância significativa nos países, principalmente no Brasil, de forma que empresas e pessoas consigam financiamento e empréstimos , estimulando novas formas de negócio e promovendo a dinâmica da economia. Para a análise do Mercado de Crédito, podemos acompanhar as concessões totais de créditos por tomadores, bem como a taxa média de juros dessas operações para que possamos compreender o momento macroeconômico do país. No post de hoje, iremos ensinar a como coletar esses indicadores e também a dessazonalizar e deflacionar as concessões de crédito. Esse exercício faz parte do nosso Curso de Análise de Conjuntura com o R, onde ensinamos a coletar, tratar e visualizar os dados do Mercado de Crédito.
Pacotes
# Carregar pacotes library(GetBCBData) library(magrittr) library(dplyr) library(ggplot2) library(scales) library(tidyr) library(deflateBR) library(lubridate) library(ggseas) library(stringr) library(zoo)
</pre> ## Funções e objetos úteis # Cores para gráficos e tabelas colors <- c( blue = "#282f6b", red = "#b22200" ) # Fonte para gráficos e tabelas foot_ibge <- "Fonte: analisemacro.com.br com dados do BCB." # Definir padrão de gráficos ggplot2::theme_set( theme( plot.title = ggplot2::element_text(size = 15, hjust = 0, vjust = 2) ) )
Código das séries
Para a coleta dos dados, devemos ter em mãos as séries disponibilizadas pelo Sistema Gerenciados de Séries Temporais do Banco Central. Através delas, coletamos os dados com o pacote {GetBCBData}.
</pre> ## Parâmetros e códigos para coleta de dados parametros <- c( # Concessões de crédito - Total - R$ (milhões) "Concessões de crédito - Total" = 20631, # Concessões de crédito - Pessoas jurídicas - Total - R$ (milhões) "Concessões de crédito - PJ" = 20632, # Concessões de crédito - Pessoas físicas - Total - R$ (milhões) "Concessões de crédito - PF" = 20633, # Taxa média de juros das operações de crédito - Total - % a.a. "Taxa média de juros das operações de crédito" = 20714 ) <pre>
</pre> ## Coleta dos dados # Dados do BCB (tidy) raw_dados <- GetBCBData::gbcbd_get_series( id = parametros, first.date = "2000-01-01", use.memoise = FALSE ) <pre>
Tratamento
Realizamos o tratamento de forma que possamos deflacionar as séries e visualizá-las.
</pre> ## Tratamento dos dados # Dados tratados em formato long dados <- raw_dados %>% dplyr::select( "date" = ref.date, "variable" = series.name, value ) # Deflacionar variáveis selecionadas (concessões) concessoes <- dados %>% dplyr::filter( variable %in% c( "Concessões de crédito - Total", "Concessões de crédito - PJ", "Concessões de crédito - PF" ) ) %>% tidyr::pivot_wider( id_cols = date, names_from = variable, values_from = value ) %>% dplyr::mutate( dplyr::across( -date, ~deflateBR::deflate( # deflacionar séries com o IPCA nominal_values = ., nominal_dates = date %m+% months(1), real_date = format(tail(date, 1), "%m/%Y"), index = "ipca" ) ) ) %>% tidyr::pivot_longer( cols = -date, names_to = "variable", values_to = "value" ) <pre>
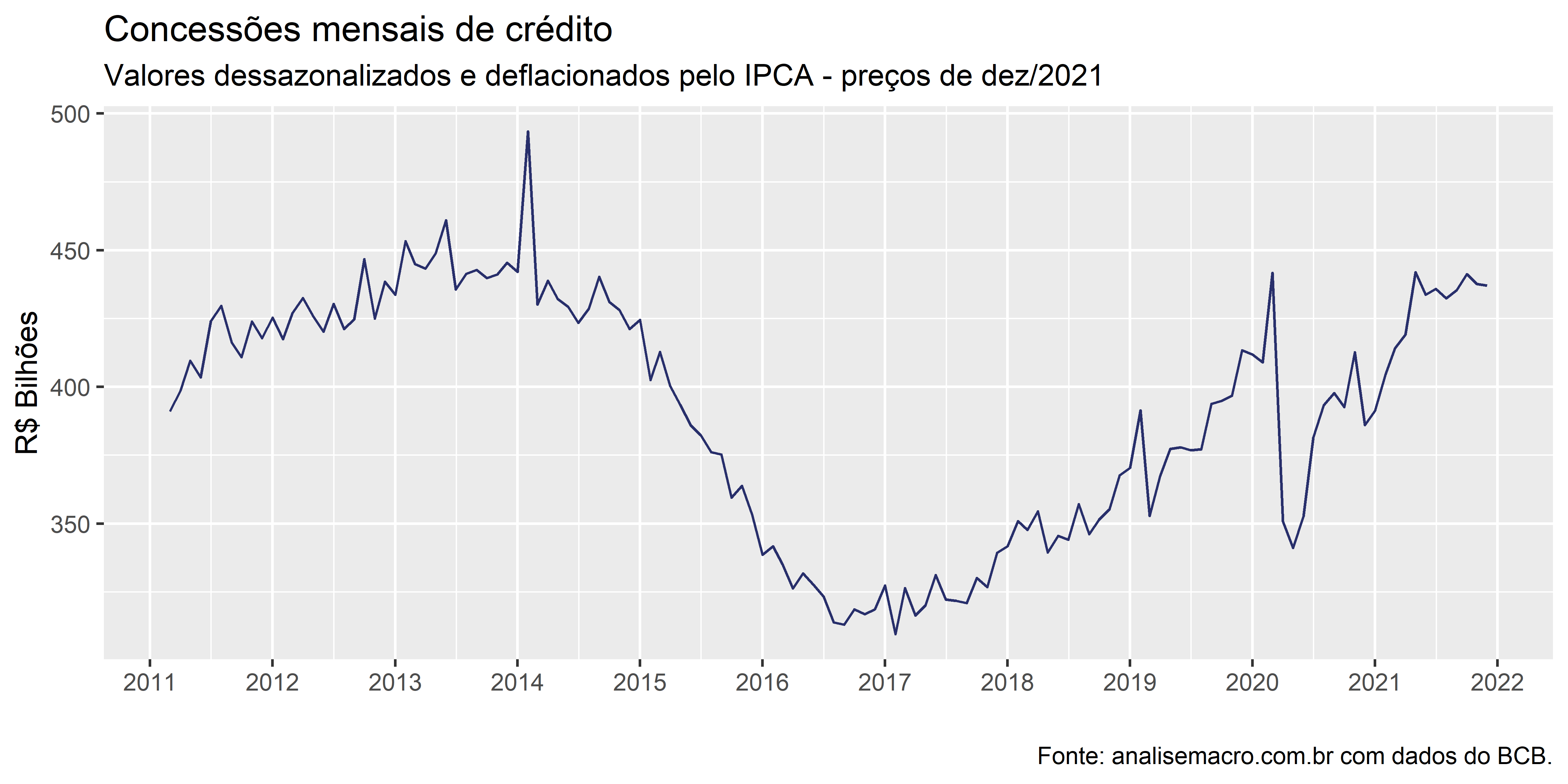
Concessões mensais de crédito
concessoes %>%
dplyr::filter(variable == "Concessões de crédito - Total") %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value/1000)) +
ggseas::stat_seas( # dessazonalizar série com X13
start = c(2011, 03),
frequency = 12,
colour = unname(colors["blue"])
) +
ggplot2::labs(
x = "",
y = "R$ Bilhões",
title = "Concessões mensais de crédito",
subtitle = paste0(
"Valores dessazonalizados e deflacionados pelo IPCA - preços de ",
format(tail(concessoes$date, 1), "%b/%Y")
),
caption = foot_ibge) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("1 year"),
labels = scales::date_format("%Y")
)
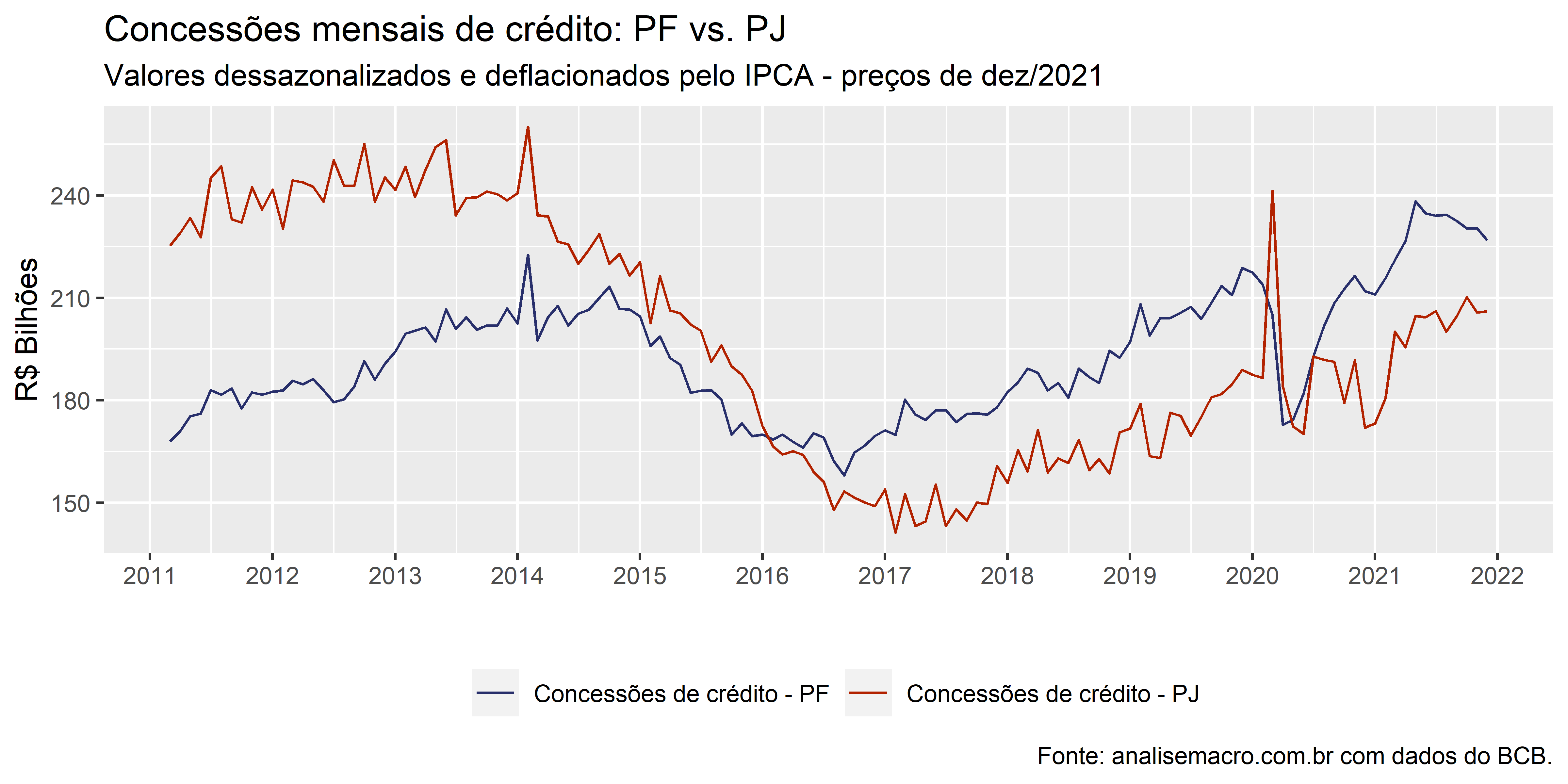
Concessões de Crédito: PJ x PF
concessoes %>%
dplyr::filter(variable %in% c("Concessões de crédito - PJ", "Concessões de crédito - PF")) %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value/1000, colour = variable)) +
ggseas::stat_seas( # dessazonalizar série com X13
start = c(2011, 03),
frequency = 12
) +
ggplot2::labs(
x = "",
y = "R$ Bilhões",
title = "Concessões mensais de crédito: PF vs. PJ",
subtitle = paste0(
"Valores dessazonalizados e deflacionados pelo IPCA - preços de ",
format(tail(concessoes$date, 1), "%b/%Y")
),
caption = foot_ibge) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("1 year"),
labels = scales::date_format("%Y")
) +
ggplot2::scale_color_manual(NULL, values = unname(colors[1:2])) +
ggplot2::theme(legend.position = "bottom")
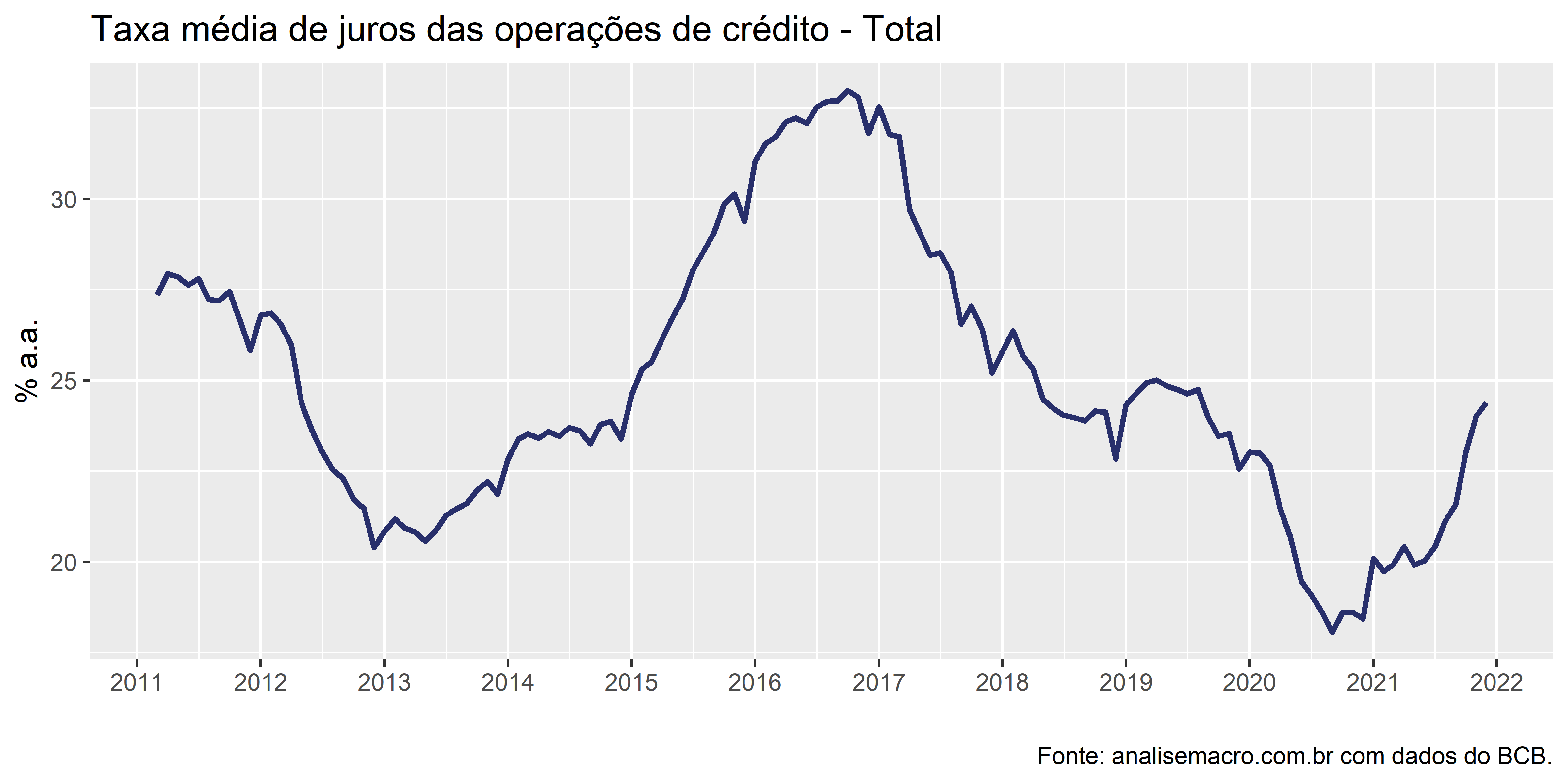
Taxa média de Juros
dados %>%
dplyr::filter(variable == "Taxa média de juros das operações de crédito") %>%
ggplot2::ggplot(ggplot2::aes(x = date, y = value)) +
ggplot2::geom_line(size = 1, colour = unname(colors[1])) +
ggplot2::labs(
x = "",
y = "% a.a.",
title = "Taxa média de juros das operações de crédito - Total",
caption = foot_ibge) +
ggplot2::scale_x_date(
breaks = scales::date_breaks("1 year"),
labels = scales::date_format("%Y")
)
Oferta Especial!
No próximo dia 17, das 9h às 19h da manhã, você terá a chance de participar do pré-lançamento do treinamento Análise de Dados Macroeconômicos e Financeiros no R. Para concorrer a uma das vagas com desconto, acesse o link e conheça os detalhes.
____________________

