O procedimento de Toda-Yamamoto
O procedimento Toda-Yamamoto é baseado no conceito de causalidade de Granger, que postula que uma variável X "causa" (no sentido granger) outra variável Y se as informações passadas de X ajudarem a prever melhor Y do que apenas as informações passadas de Y. O teste de Toda-Yamamoto é uma extensão do teste de causalidade de Granger, que leva em consideração a presença de tendências e estruturas não lineares nas séries temporais.
O procedimento descrito por Toda e Yamamoto (1995) consiste, basicamente, nos seguintes passos:
- Verificar a ordem de integração das variáveis através de testes de raiz unitária e estacionariedade;
- Definir a ordem máxima (m) de integração entre as variáveis;
- Montar o VAR em nível para as variáveis;
- Determinar a ordem de defasagem do VAR(p) pelos critérios de informação tradicionais;
- Ver a estabilidade do modelo, em particular problemas de autocorrelação;
- Se estiver tudo certo, adicionar m defasagens ao VAR, de modo que você terá um VAR(p+m);
- Rodar o teste de Wald com p coeficientes e p graus de liberdade.
Ibovespa vs. Variação da FBCF no Python
Neste exercícios construímos um código que permita coletar, tratar e visualizar os dados do Ibovespa e da FBCF, e em seguida aplicar o procedimento de Toda-Yamamoto no Python.
Para obter todo o código do processo de criação do modelo, faça parte do Clube AM, o repositório de códigos da Análise Macro, contendo exercícios semanais de R e Python.
Os dados Ibovespa são coletados através do Yahoo Finance via biblioteca yfinance, e referem-se aos pontos do índice de acordo com seu preço de fechamento ajustado do trimestre. A transformação do período é necessária de forma que seja possível comparar com a série da FBCF, visto que esta possui periodicidade trimestral, de acordo com as Contas Nacionais Trimestrais divulgadas pelo IBGE.
Os dados da FBCF, como mencionado, são coletados do IBGE, neste caso, via SIDRA, utilizando a biblioteca sidrapy. Uma vez obtido o índice, é aplicado o cálculo de variação interanual, por meio da equação.
![\[\text{Variação interanual} = \frac{\text{Índice}_{t}}{\text{Índice}_{t-4}}\]](https://analisemacro.com.br/wp-content/ql-cache/quicklatex.com-d8fe9ae008c30a34c5b13aff5c1a1134_l3.png "Rendered by QuickLaTeX.com")
Visualizamos as duas séries:

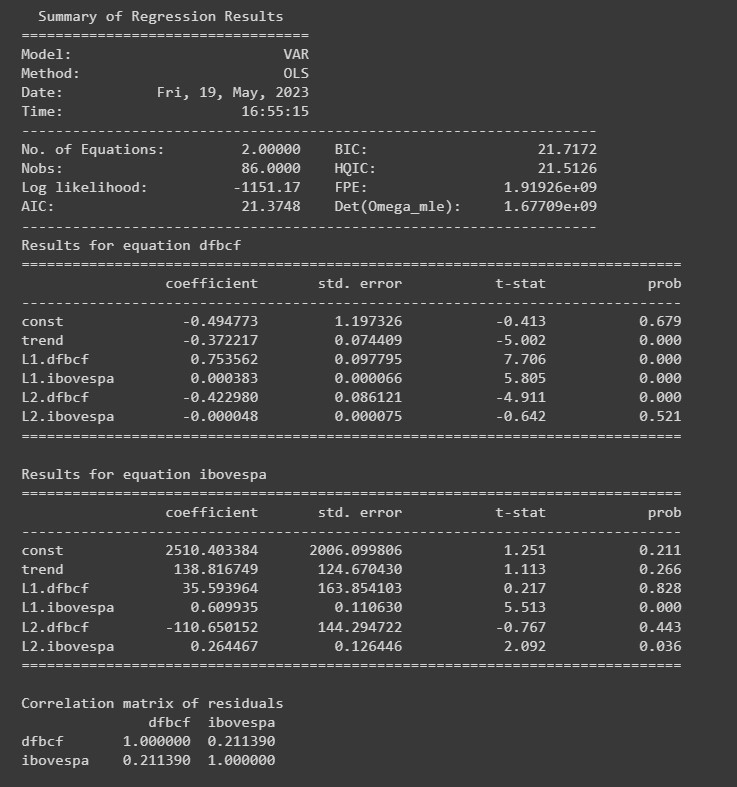
Estimação do VAR
Neste exercício, vamos pular os três primeiros passos e prosseguir após o quarto, em que estimamos diretamente, um VAR(2). Abaixo, o sumário das estatísticas do modelo.
Portmanteau Test
Posterior a estimação dos modelos, e realizamos um teste de correlação serial dos erros.
O Portmanteau Test é usado para avaliar se existe autocorrelação residual significativa em um modelo ajustado, ou seja, se há dependência linear entre os resíduos em diferentes defasagens.
Se os resíduos são verdadeiramente aleatórios, espera-se que as autocorrelações sejam próximas de zero. O teste calcula uma estatística de teste baseada nas autocorrelações dos resíduos em várias defasagens e a compara com uma distribuição qui-quadrado para determinar se há autocorrelação significativa.
Queremos achar um modelo tal que não rejeite a hipótese nula de ausência de autocorrelação, isto é, não desejamos obter um resultado do p-value do Portmanteau Test menor de 0,05 (5%).

Wald Test
Agora vamos verificar a causalidade. Para tanto, utilizamos o Wald test, que é um teste estatístico utilizado para avaliar a significância dos coeficientes estimados em modelos de regressão. Ele é baseado na comparação entre a estimativa do coeficiente e a sua variância estimada.
Para tanto vamos testar a hipótese nula de que um coeficiente é igual a zero. A ideia é verificar se a estimativa do coeficiente é estatisticamente diferente de zero, o que indicaria a presença de um efeito significativo da variável explicativa correspondente sobre a variável resposta.
Se a estatística de teste calculada for maior do que o valor crítico da distribuição qui-quadrado, rejeita-se a hipótese nula, indicando que o coeficiente é significativamente diferente de zero.
Por outro lado, se a estatística de teste for menor do que o valor crítico, não há evidência suficiente para rejeitar a hipótese nula, sugerindo que o coeficiente não é significativamente diferente de zero.


Através do exercício, chegamos a conclusão de que o IBOVESPA granger causa DFBCF.
Referências
_____________________________________
Quer aprender mais?
Seja um aluno da nossa trilha de Macroeconomia Aplicada e aprenda a criar projetos voltados para a Macroeconomia.

