O Ministério da Economia, enfim, divulgou os dados do CAGED em 2020. Os resultados, adianto, não são nada bons. Para analisar os dados do saldo do CAGED, podemos usar o pacote ecoseries e pegar os dados do IPEADATA. O código abaixo exemplifica.
library(ecoseries)
df_caged = series_ipeadata('272844966', periodicity = 'M')$serie_272844966
Uma vez que os dados sejam baixados, podemos visualizar os meses de abril de diversos anos com o código abaixo.
library(tidyverse)
library(lubridate)
library(scales)
df_caged_abril = filter(df_caged, month(data) == 4)
ggplot(df_caged_abril, aes(x=data))+
geom_bar(aes(y=valor/1000),
colour = ifelse(df_caged_abril$valor > 0, 'blue', "red"),
fill = ifelse(df_caged_abril$valor > 0, 'blue', "red"),
stat='identity', width = 100)+
geom_hline(yintercept=0, colour='black', linetype='dashed')+
scale_x_date(breaks = date_breaks("1 years"),
labels = date_format("%Y"))+
labs(x='', y='Mil pessoas',
title='Saldo do CAGED nos meses de Abril',
caption='Fonte: analisemacro.com.br com dados do CAGED.')+
theme(plot.title = element_text(size=12, face='bold'),
plot.caption = element_text(size=9),
axis.title.y = element_text(size=9),
axis.text.x=element_text(angle=45, hjust=1))
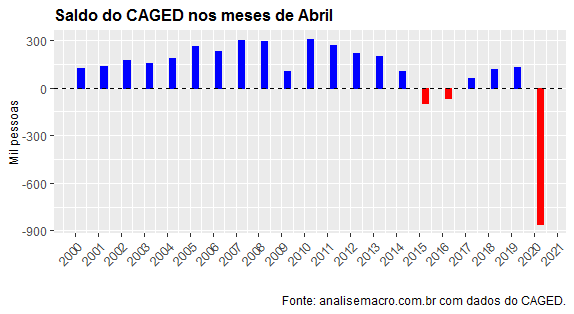
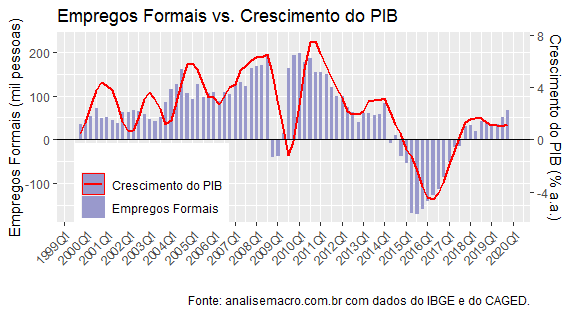
Os dados indicam que houve um queda líquida de 860,5 mil vagas no mês de abril, refletindo a pandemia do coronavírus. Isso é bastante preocupante, uma vez que existe uma correlação forte entre o CAGED e o crescimento do PIB, como pode ser visto abaixo.
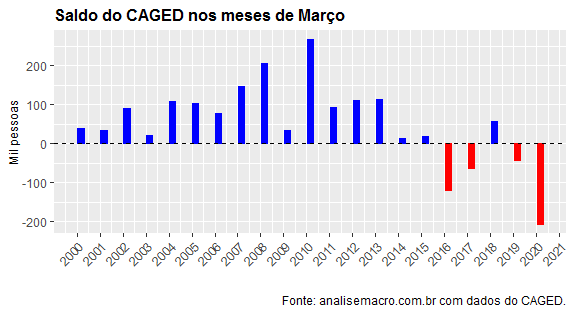
No mês de março, diga-se, houve uma queda líquida de 207,4 mil vagas. O gráfico abaixo ilustra.
Feita a dessazonalização da série, nós obtemos o gráfico abaixo, que ilustra melhor o comportamento do saldo do CAGED e o efeito da pandemia sobre ela.
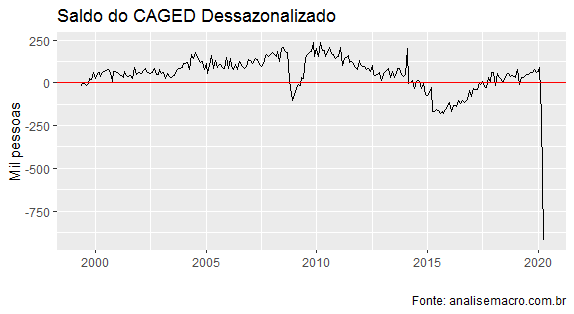
Como se vê, o impacto sobre a série foi brutal. Haverá algum impacto sobre o PIB do 1º trimestre, mas o maior efeito deverá ser mesmo sobre o PIB do 2º tri. O dado do PIB do 1º trimestre será divulgado nessa sexta-feira. Já o do 2º tri será divulgado apenas em setembro.
A relação entre CAGED e crescimento do PIB foi analisada na edição 58 do Clube do Código.
____________________
(*) Você aprende a coletar, tratar e visualizar dados macroeconômicos no nosso Curso de Análise de Conjuntura usando o R.

