A utilização de linguagens de programação tem permitido o uso mais frequente de cálculos complexos para o mundo das finanças, de forma simples e rápida. O Python é uma dessas linguagens, e tem encabeçado essa mudança do mundo quantitativo. No post de hoje, mostraremos o poder do Python ao realizar o cálculo da relação de risco e retorno de uma carteira de ações teóricas, bem como realizar a simulação de 200 carteiras com pesos diferentes, obtendo um gráfico de conjunto de oportunidades.
A partir de três métricas, sendo elas a média, a variância, além de uma matriz de covariância, construiremos as possíveis combinações da relação de risco x retorno de uma carteira dos ativos contendo três ações. O método aqui utilizado é bastante conhecido, sendo parte da Teoria de Carteiras. Esse método é útil para buscarmos o melhor cenário de combinações de pesos que entregam valores de retornos e risco que o investidor deseje.
Vamos seguir para o nosso código.
# Importa as bibliotecas import numpy as np import pandas as pd import matplotlib.pyplot as plt import pandas_datareader.data as web import seaborn as sns !pip install yfinance --upgrade --no-cache-dir import yfinance as yf yf.pdr_override()
# Importa os preços de fechamento prices = web.get_data_yahoo(['ITUB4.SA', 'B3SA3.SA', 'VALE3.SA'], start = '2013-01-01')['Close'] # Retira dados faltantes prices = prices.dropna() # Plota os preços de fechamento sns.set() prices.plot(subplots = True, figsize = (22, 8))
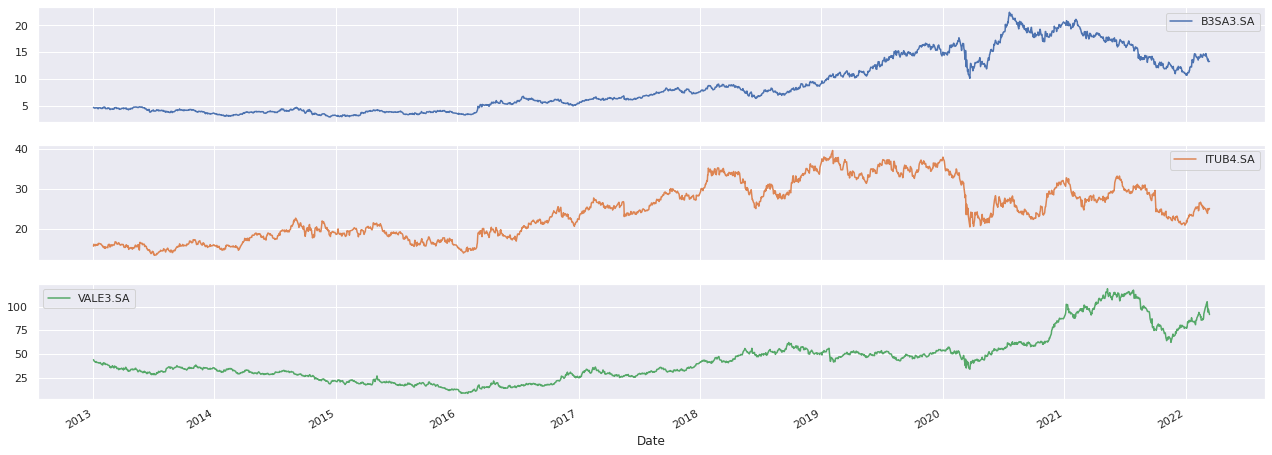
Escolhemos três ativos sem critério algum, com dados diários desde 2013 até o dia atual (14/03/2022). Visualizamos o preço de fechamento de cada ativo acima. Como vemos, os preço são similares a um passeio aleatório, portanto, não seria interessante trabalharmos com eles. Por isso, devemos realizar uma transformação, utilizando os retornos dos preços, que na prática, é uma transformação através de uma diferenciação.
Após a transformação para retornos diários, realizamos mais dois cálculos: a média dos retornos, que será aqui utilizada como o retorno esperado de cada ativo, e a matriz de covariância dos retornos, para entender a associação linear entre os ativos e entender o ponto de diversificação entre eles.
# Tamanho das colunas (número de ativos) n = len(prices.columns) # Calcula os retornos returns = prices/prices.shift(1)-1 # Retira os dados faltantes returns = returns.dropna() # Calcula a média (retorno esperado) mi = returns.mean() # Calcula a covariância sigma = returns.cov()
 Como possuímos mais ativos na carteira, seria interessante calculá-los todos em conjunto, ao invés de individualmente. Para o retorno esperado, calculamos como a soma dos pesos multiplicados pelo retorno esperado de cada ativo. Para o desvio padrão da carteira, calculamos como a variância de cada ativo ponderado pelos seus respectivos pesos, e considerando a associação linear de cada ativo entre si (covariância) de forma que possamos obter uma forma de calcular a diversificação da carteira. Definimos o vetor de pesos da nossas carteira, seguindo a ordenação de cada ativo no data frame.
Como possuímos mais ativos na carteira, seria interessante calculá-los todos em conjunto, ao invés de individualmente. Para o retorno esperado, calculamos como a soma dos pesos multiplicados pelo retorno esperado de cada ativo. Para o desvio padrão da carteira, calculamos como a variância de cada ativo ponderado pelos seus respectivos pesos, e considerando a associação linear de cada ativo entre si (covariância) de forma que possamos obter uma forma de calcular a diversificação da carteira. Definimos o vetor de pesos da nossas carteira, seguindo a ordenação de cada ativo no data frame.# Define os pesos aleatórios para os ativos w = np.array([0.4, 0.2, 0.3]) # Calcula o retono esperado da carteira retorno = np.sum(w*mi) # Calcula os desvio padrão (risco) da carteira risco = np.sqrt(np.dot(w.T, np.dot(sigma, w)))

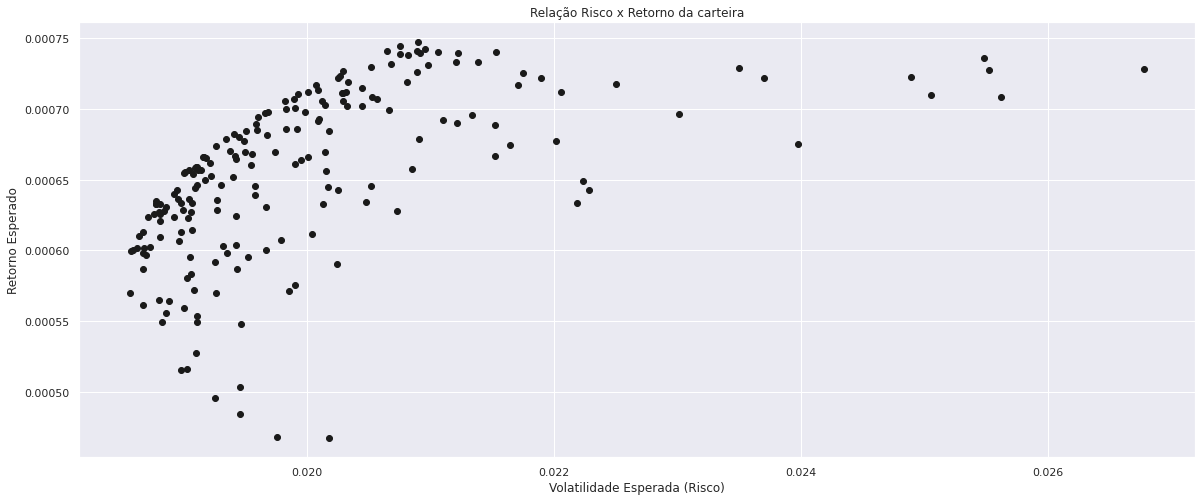
Para criarmos o conjunto de oportunidades, isto é, as diversas carteiras teóricas que podem ser obtidas pela combinação de n pesos dos ativos, criamos um for loop com 200 simulações.
# Cria listas vazias
vet_R = []
vet_Vol = []
# Realiza a simulação de 200 carteiras com pesos diferentes
for i in range(200):
# --------------- pesos dos ativos ---------------- #
w = np.random.random(n)
w = w/np.sum(w)
# ---------------- Retorno e Risco ---------------- #
retorno = np.sum(w*mi)
risco = np.sqrt(np.dot(w.T, np.dot(sigma, w)))<
# ------------------------------------------------- #
vet_R.append(retorno)
vet_Vol.append(risco)
# Plota
sns.set()
plt.figure(figsize=(20, 8))
plt.plot(vet_Vol, vet_R, 'ok')
plt.ylabel('Retorno Esperado')
plt.xlabel('Volatilidade Esperada (Risco)')
plt.title('Relação Risco x Retorno da carteira')