No post de hoje, iremos aprender passo a passo a como construir uma análise de dados do zero do IPCA, iniciando pela etapa de importação, seguindo para limpeza e tratamento, exploração, visualização e iremos finalizar criando um modelo de regressão de forma a entender a inflação com a ajuda da teoria econômica.
Replicaremos os métodos utilizados no último post Construindo sua primeira análise de dados do ZERO com o R, portanto, reutilizando os conteúdo, entretanto alterando para o Python.
Um tema que os economistas sempre estudam é a inflação. A inflação é conhecida como a taxa de crescimento do nível geral de preços entre dois períodos distintos.
Averiguar a inflação de um país é uma tarefa dificultosa, imagine, medir o preços de todos os produtos? Apesar disso, o IBGE realiza uma árdua tarefa que visa tentar replicar o valor da inflação através do Índice de Preço dos Consumidor Amplo - IPCA , criando pesquisas que visam entender o consumo dos brasileiros, ponderando os produtos e calculando as variações dos mesmos ao longo do tempo.
E o interessante é que o instituto disponibiliza os dados do indicador através de sua plataforma: SIDRA.
Conseguimos acessar os dados do SIDRA através de uma API disponibilizada pelo instituto, entretanto, seria um pouco dificultoso aprender a como utilizar a API e consultar os dados, não?
Por isso, a comunidade do Python fez a questão de criar um pacote que auxilia no processo: {sidrapy}. Vamos utilizar o pacote para buscar os dados.
Para buscar os dados do SIDRA, devemos acessar a plataforma, encontrar a tabela dos dados do IPCA que desejamos, selecionar os parâmetros (as informações que desejamos importar) e em seguida copiar a chave API. Para mais detalhes veja os posts de como importar os dados: Como importar dados do Banco Central, IPEADATA e Sidra no R? e Coletando dados do SIDRA com o Python.
Vamos utilizar a tabela 1737, referente aos dados do IPCA Acumulado em 12 meses. O objetivo de utilizar o acumulado é que desta forma podemos entender a variação em um período de maior longo prazo e que possibilita tirar informações mais interessante sobre a conjuntura se comparado com a variação mensal ou mesmo o número índice.
Com a chave API em mãos, podemos utilizar a função da biblioteca sidrapy, get_table(), e salvar o resultado da consulta em um objeto.
Bibliotecas
Coleta
Limpeza e Tratamento
Exploração dos Dados
Agora que realizamos a limpeza dos dados, podemos realizar a exploração dos dados.
Devemos começar com algumas perguntas para a nossa análise:
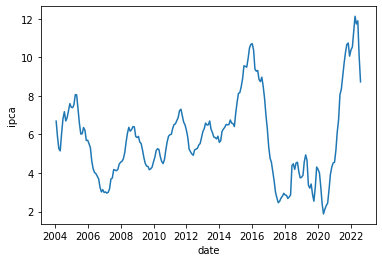
Como a inflação se comportou no Brasil?
Qual o período com menores e maiores taxas de inflação?
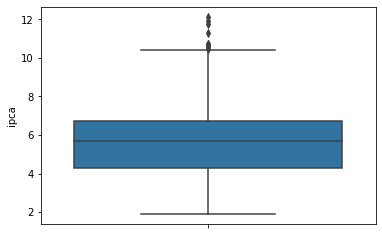
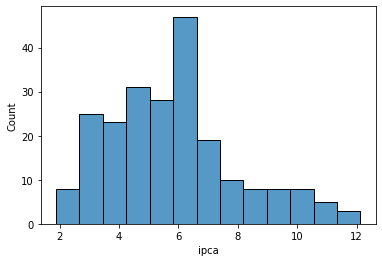
Qual o valor médio da inflação do Brasil e como é a distribuição de seus valores?
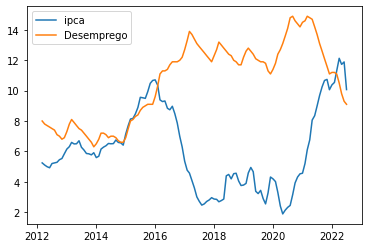
O que afeta a inflação? Com qual variável ela se relaciona?
Vamos começar com o método describre(), que permite calcular os cinco números dos valores do IPCA. Vemos que o valor mínimo do IPCA Acumulado em 12 meses foi de 1,880%, enquanto o valor máximo foi de 12,13%. A mediana dos valores durante o período está em 5,832%.
Modelagem
Agora, vamos tentar entender algo sobre a inflação, o que afeta ela? Vamos recapitular a teoria econômica para isso.
Curva de Phillips
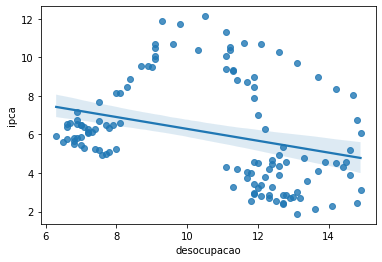
Em 1958, A. W. Phillips traçou um diagrama que mostrava a relação entre a taxa de inflação e a taxa de desemprego no Reino Unido para cada ano de 1861 a 1957. Logo após o trabalho de Phillips, Paul Samuelson e Robert Solow repetiram o exercício para o Estados Unidos e batizaram de curva de Phillips.
Rapidamente se tornou fundamental para o pensamento macroeconômico e para a política macroeconômica. Ela parecia implicar que os países poderiam escolher entre combinações diferentes de desemprego e inflação. Um país poderia ter um índice baixo de desemprego se estivesse disposto a tolerar uma inflação mais alta, ou atingir a estabilidade do nível de preços — inflação zero — se estivesse disposto a tolerar um desemprego mais alto.
A Curva de Phillips se tornou uma forma quase definitiva de entender a inflação em um país, entretanto, sofrendo diversas modificações ao longo do tempo, sendo aprimorada pela teoria econômica e por trabalhos empíricos.
Para manter a análise simples, vamos utilizar a Curva de Phillips original, traçando a relação entre Inflação e Desemprego no Brasil. Para isso, devemos obter os dados da Taxa de Desocupação do Brasil através do SIDRA. Repetimos o mesmo código de coleta e tratamento, entretanto, utilizando a chave API do indicador da tabela 6381.
____________________________________________________
Quer aprender mais?
Veja nosso curso de Fundamentos de Análise de Dados, onde ensinamos todo o processo para aqueles que desejam entrar na área. O curso faz parte da trilha Ciência de Dados para Economia e Finanças.
___________________________________________________
Referências
BLANCHARD, Olivier. Macroeconomia. Pearson, 2017.
DORNBUSCH, Rudiger; FISCHER, Stanley; STARTZ, Richard. Macroeconomia. Bookman Editora, 2013.

